You might also like
- Project Control Methods and Best Practices: Achieving Project SuccessFrom EverandProject Control Methods and Best Practices: Achieving Project SuccessNo ratings yet
- Critical Success Factors For Projects: David BaccariniDocument10 pagesCritical Success Factors For Projects: David BaccariniAastha ShahNo ratings yet
- Q & As for the PMBOK® Guide Sixth EditionFrom EverandQ & As for the PMBOK® Guide Sixth EditionRating: 4.5 out of 5 stars4.5/5 (18)
- Critical Success Factors For Projects: David BaccariniDocument10 pagesCritical Success Factors For Projects: David BaccariniRyanNo ratings yet
- Pankratz-Basten-2013-ICIS-Eliminating Failure by Learning From It - Systematic Review of IS PDFDocument20 pagesPankratz-Basten-2013-ICIS-Eliminating Failure by Learning From It - Systematic Review of IS PDFRudi IryantoNo ratings yet
- Avoiding Project Failure DissertationDocument32 pagesAvoiding Project Failure DissertationPrecious MoyoNo ratings yet
- Human Error and Successful Project Management in Two Construction CompaniesDocument6 pagesHuman Error and Successful Project Management in Two Construction CompaniesMadonna SamirNo ratings yet
- Project Management Failure IssuesDocument3 pagesProject Management Failure IssuesNicole Patricia Alinea NogueraNo ratings yet
- Critique Paper 1Document3 pagesCritique Paper 1Den XiongNo ratings yet
- Thesis Project Management PDFDocument4 pagesThesis Project Management PDFCustomHandwritingPaperCanada100% (2)
- The Influence of Experience and Education of Project Managers On Project SuccessDocument8 pagesThe Influence of Experience and Education of Project Managers On Project SuccessMarija Šiško KulišNo ratings yet
- 1 s2.0 S1877705816302144 MainDocument8 pages1 s2.0 S1877705816302144 MainNicole Louise RiveraNo ratings yet
- Development of The SMARTTM Project Planning FrameworkDocument12 pagesDevelopment of The SMARTTM Project Planning Frameworkjohnalis22No ratings yet
- MSC Project Management Thesis TopicsDocument4 pagesMSC Project Management Thesis TopicsCollegePaperWritingServicesCanada100% (2)
- For Successful Projects: Why Information Systems Projects Fail: GuidelinesDocument6 pagesFor Successful Projects: Why Information Systems Projects Fail: GuidelinesBakhtawar SaleemNo ratings yet
- 1 AAhimbisibwe Cavana DaleanbatchDocument28 pages1 AAhimbisibwe Cavana DaleanbatchSam GvmxdxNo ratings yet
- Project Management Failure: Main Causes: by Soraya J. NetoalvarezDocument22 pagesProject Management Failure: Main Causes: by Soraya J. Netoalvarezvitza1No ratings yet
- Introduction To Project ManagementDocument53 pagesIntroduction To Project ManagementAml MakaremNo ratings yet
- Critique Paper 1Document4 pagesCritique Paper 1Den XiongNo ratings yet
- How Project Management Approach Impact Project SuccessDocument28 pagesHow Project Management Approach Impact Project SuccessDavid FerrerNo ratings yet
- Managing Project Scope Creep in Construction Industry: Aman Jaiswal (224104301) Vikas Sharma (224104309)Document13 pagesManaging Project Scope Creep in Construction Industry: Aman Jaiswal (224104301) Vikas Sharma (224104309)Vikas SharmaNo ratings yet
- Critical Factors in Project Implementation: A Comparison of Construction and R&D ProjectsDocument14 pagesCritical Factors in Project Implementation: A Comparison of Construction and R&D ProjectsAastha ShahNo ratings yet
- An Empirical Analysis of The Relationship Between Project Planning and Project Success PDFDocument8 pagesAn Empirical Analysis of The Relationship Between Project Planning and Project Success PDFTakdir S PangaraNo ratings yet
- Thesis Delay Construction ProjectDocument5 pagesThesis Delay Construction Projectjessicadeakinannarbor100% (2)
- Case StudyDocument29 pagesCase StudyTherese ChiuNo ratings yet
- Sustainability PDFDocument15 pagesSustainability PDFMr. KNo ratings yet
- Research Papers On Construction Project ManagementDocument8 pagesResearch Papers On Construction Project Managementgbjtjrwgf100% (1)
- Literature Review Construction Project ManagementDocument8 pagesLiterature Review Construction Project Managementc5qfb5v5No ratings yet
- It Project Management Thesis PDFDocument8 pagesIt Project Management Thesis PDFmichellerobertsonportland100% (2)
- Construction Project Management Dissertation ExamplesDocument6 pagesConstruction Project Management Dissertation ExamplesCustomCollegePaperCanadaNo ratings yet
- Eai 14-9-2020 2304479Document13 pagesEai 14-9-2020 2304479Eyael ShimleasNo ratings yet
- Assessment of Critical Success Factors For Construction Projects in PakistanDocument13 pagesAssessment of Critical Success Factors For Construction Projects in PakistanAbdul Qayoom Memon100% (1)
- 10 11648 J Ajtab 20210704 13Document8 pages10 11648 J Ajtab 20210704 13kefiyalew BNo ratings yet
- Factors Affecting Success of Construction ProjectDocument10 pagesFactors Affecting Success of Construction ProjectInternational Organization of Scientific Research (IOSR)No ratings yet
- An Empirical Analysis of The Relationship Between Project Planning and Project SuccessDocument7 pagesAn Empirical Analysis of The Relationship Between Project Planning and Project Successapi-3707091No ratings yet
- Literature Review On Risk Management in Construction ProjectsDocument10 pagesLiterature Review On Risk Management in Construction ProjectscmaqqsrifNo ratings yet
- Awareness and Knowledge of Project ManagDocument6 pagesAwareness and Knowledge of Project Managdnyanesh1inNo ratings yet
- Quantity Surveying Dissertation IdeasDocument8 pagesQuantity Surveying Dissertation IdeasWriteMyStatisticsPaperNewOrleans100% (1)
- 9 SUCCESS BannermanDocument13 pages9 SUCCESS BannermantsjatobaNo ratings yet
- Determinants of Successful Project Implementation in Nigeria Volume1Document17 pagesDeterminants of Successful Project Implementation in Nigeria Volume1HannaNo ratings yet
- Research Paper 3.3.3Document12 pagesResearch Paper 3.3.3Sailee RedkarNo ratings yet
- Andreki, P. (2016) - Exploring Critical Success Factors of Construction Projects.Document12 pagesAndreki, P. (2016) - Exploring Critical Success Factors of Construction Projects.beast mickeyNo ratings yet
- Significance of Scope in Project Success - AwatefDocument8 pagesSignificance of Scope in Project Success - AwatefWong LippingNo ratings yet
- VBNet Thery Ass 1Document24 pagesVBNet Thery Ass 1NdumisoSitholeNo ratings yet
- Thesis Manufacturing ProcessDocument7 pagesThesis Manufacturing Processlisadiazsouthbend100% (2)
- Construction Project Management Thesis PDFDocument8 pagesConstruction Project Management Thesis PDFbsqkr4kn100% (2)
- Cook& Davies, Real Success Factors On Projects, 2002Document6 pagesCook& Davies, Real Success Factors On Projects, 2002Christian PffhsnNo ratings yet
- Project Manager ThesisDocument6 pagesProject Manager Thesisdonnacastrotopeka100% (2)
- Thesis On Project FailureDocument6 pagesThesis On Project Failurehod1beh0dik3100% (2)
- Alexandrova and IvanovaDocument10 pagesAlexandrova and IvanovaSiencia No Enjinaria DitNo ratings yet
- Cost and Time Project Management Success Factors For Information Systems Development ProjectsDocument48 pagesCost and Time Project Management Success Factors For Information Systems Development ProjectsGeremew Tarekegne TsegayeNo ratings yet
- Real Success Factors On ProjectDocument6 pagesReal Success Factors On ProjectBenard OderoNo ratings yet
- Scheduling and It Current StateDocument2 pagesScheduling and It Current StateJose DivasNo ratings yet
- List of Thesis Topics in Construction Project ManagementDocument4 pagesList of Thesis Topics in Construction Project ManagementJames Heller100% (1)
- Thesis Topics Construction ManagementDocument6 pagesThesis Topics Construction Managementbseb81xq100% (2)
- MSC Construction Project Management Dissertation TopicsDocument7 pagesMSC Construction Project Management Dissertation TopicsBuyingPapersOnlineCollegeSpringfieldNo ratings yet
- A Vision-Oriented Approach For Innovative Product DesignDocument10 pagesA Vision-Oriented Approach For Innovative Product DesignAnonymous G3ixxpLyknNo ratings yet
- Chapter 3Document60 pagesChapter 3abbasamir2998No ratings yet
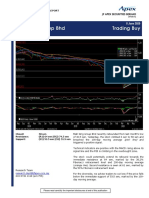
- 20200605technical Stock Pick - Mah Sing PDFDocument2 pages20200605technical Stock Pick - Mah Sing PDFAHMADNo ratings yet
- Key Success/failure Factors and Their Impacts On System Performance of Web-Based Project Management Systems in ConstructionDocument22 pagesKey Success/failure Factors and Their Impacts On System Performance of Web-Based Project Management Systems in ConstructionAHMADNo ratings yet
- Engtex 1Q20 Results PDFDocument4 pagesEngtex 1Q20 Results PDFAHMADNo ratings yet
- Gadang - Bags ECRL Project PDFDocument3 pagesGadang - Bags ECRL Project PDFAHMADNo ratings yet
- Gadang 3QFY20 Results PDFDocument4 pagesGadang 3QFY20 Results PDFAHMADNo ratings yet
- Axiata - 1Q20 Results PDFDocument3 pagesAxiata - 1Q20 Results PDFAHMADNo ratings yet
- Axiata - 1Q20 Results PDFDocument3 pagesAxiata - 1Q20 Results PDFAHMADNo ratings yet
- Gadang - Bags ECRL Project PDFDocument3 pagesGadang - Bags ECRL Project PDFAHMADNo ratings yet
- 20200605technical Stock Pick - Mah Sing PDFDocument2 pages20200605technical Stock Pick - Mah Sing PDFAHMADNo ratings yet
- Technical Stock Pick - PUCDocument2 pagesTechnical Stock Pick - PUCAHMADNo ratings yet
- Gadang 3QFY20 Results PDFDocument4 pagesGadang 3QFY20 Results PDFAHMADNo ratings yet
- Breakdow of Topics Ent530Document10 pagesBreakdow of Topics Ent530AHMADNo ratings yet
- FKEUR1 DoctorofPhilosophy (Economics) DevelopmentDocument5 pagesFKEUR1 DoctorofPhilosophy (Economics) DevelopmentAHMADNo ratings yet
- Off Grid Solar Hybrid Inverter Operate Without Battery: HY VMII SeriesDocument1 pageOff Grid Solar Hybrid Inverter Operate Without Battery: HY VMII SeriesFadi Ramadan100% (1)
- Data Mining in IoTDocument29 pagesData Mining in IoTRohit Mukherjee100% (1)
- World BankDocument28 pagesWorld BankFiora FarnazNo ratings yet
- A-1660 11TH Trimester From Mcdowell To Vodafone Interpretation of Tax Law in Cases. OriginalDocument18 pagesA-1660 11TH Trimester From Mcdowell To Vodafone Interpretation of Tax Law in Cases. OriginalPrasun TiwariNo ratings yet
- The Fastest Easiest Way To Secure Your NetworkDocument9 pagesThe Fastest Easiest Way To Secure Your NetworkMark ShenkNo ratings yet
- Richardson ResumeDocument3 pagesRichardson Resumeapi-549248694No ratings yet
- 2023 2024 Syllabus PDFDocument23 pages2023 2024 Syllabus PDFRika DianaNo ratings yet
- Request For Proposals/quotationsDocument24 pagesRequest For Proposals/quotationsKarl Anthony Rigoroso MargateNo ratings yet
- DC Generator - Construction, Working Principle, Types, and Applications PDFDocument1 pageDC Generator - Construction, Working Principle, Types, and Applications PDFGokul GokulNo ratings yet
- Department of Education: Republic of The PhilippinesDocument2 pagesDepartment of Education: Republic of The PhilippinesISMAEL KRIS DELA CRUZNo ratings yet
- Cummins: ISX15 CM2250Document17 pagesCummins: ISX15 CM2250haroun100% (4)
- Storage-Tanks Titik Berat PDFDocument72 pagesStorage-Tanks Titik Berat PDF'viki Art100% (1)
- Very Hungry Caterpillar Clip CardsDocument5 pagesVery Hungry Caterpillar Clip CardsARTGRAVETO ARTNo ratings yet
- Evan Lagueux - H Argument EssayDocument7 pagesEvan Lagueux - H Argument Essayapi-692561087No ratings yet
- Linux and The Unix PhilosophyDocument182 pagesLinux and The Unix PhilosophyTran Nam100% (1)
- Pizza Restaurant PowerPoint TemplatesDocument49 pagesPizza Restaurant PowerPoint TemplatesAindrila BeraNo ratings yet
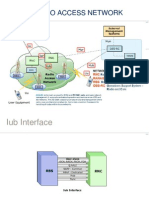
- WCDMA Radio Access OverviewDocument8 pagesWCDMA Radio Access OverviewDocMasterNo ratings yet
- Speaking RubricDocument1 pageSpeaking RubricxespejoNo ratings yet
- Academic Performance of Senior High School Students 4Ps Beneficiaries in VNHSDocument19 pagesAcademic Performance of Senior High School Students 4Ps Beneficiaries in VNHSkathlen mae marollanoNo ratings yet
- ProjectDocument32 pagesProjectroshan jaiswalNo ratings yet
- Final Lesson PlanDocument3 pagesFinal Lesson Planapi-510713019No ratings yet
- Wiska Varitain - 0912Document18 pagesWiska Varitain - 0912Anonymous hHWOMl4FvNo ratings yet
- On The Wings of EcstasyDocument79 pagesOn The Wings of Ecstasygaya3mageshNo ratings yet
- 1en 02 PDFDocument96 pages1en 02 PDFAndrey100% (2)
- PretestDocument8 pagesPretestAlmonte Aira LynNo ratings yet
- Charter of The New UrbanismDocument4 pagesCharter of The New UrbanismBarabas SandraNo ratings yet
- Student Research Project Science ReportDocument8 pagesStudent Research Project Science Reportapi-617553177No ratings yet
- Introduction: Meaning of HypothesisDocument8 pagesIntroduction: Meaning of HypothesisMANISH KUMARNo ratings yet
- Task of ProjectDocument14 pagesTask of ProjectAbdul Wafiy NaqiuddinNo ratings yet
- Unilever PakistanDocument26 pagesUnilever PakistanElie Mints100% (3)
- The PARA Method: Simplify, Organize, and Master Your Digital LifeFrom EverandThe PARA Method: Simplify, Organize, and Master Your Digital LifeRating: 5 out of 5 stars5/5 (36)
- Agile: The Insights You Need from Harvard Business ReviewFrom EverandAgile: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (34)
- Building a Second Brain: A Proven Method to Organize Your Digital Life and Unlock Your Creative PotentialFrom EverandBuilding a Second Brain: A Proven Method to Organize Your Digital Life and Unlock Your Creative PotentialRating: 4.5 out of 5 stars4.5/5 (238)
- High Velocity Innovation: How to Get Your Best Ideas to Market FasterFrom EverandHigh Velocity Innovation: How to Get Your Best Ideas to Market FasterRating: 5 out of 5 stars5/5 (1)
- The PARA Method: Simplify, Organize, and Master Your Digital LifeFrom EverandThe PARA Method: Simplify, Organize, and Master Your Digital LifeRating: 4.5 out of 5 stars4.5/5 (3)
- The Third Wave: An Entrepreneur's Vision of the FutureFrom EverandThe Third Wave: An Entrepreneur's Vision of the FutureRating: 4 out of 5 stars4/5 (63)
- Managing Time (HBR 20-Minute Manager Series)From EverandManaging Time (HBR 20-Minute Manager Series)Rating: 4.5 out of 5 stars4.5/5 (47)
- 300+ PMP Practice Questions Aligned with PMBOK 7, Agile Methods, and Key Process Groups - 2024: First EditionFrom Everand300+ PMP Practice Questions Aligned with PMBOK 7, Agile Methods, and Key Process Groups - 2024: First EditionNo ratings yet
- The Myth of Multitasking: How "Doing It All" Gets Nothing DoneFrom EverandThe Myth of Multitasking: How "Doing It All" Gets Nothing DoneRating: 5 out of 5 stars5/5 (1)
- Agile: The Complete Overview of Agile Principles and PracticesFrom EverandAgile: The Complete Overview of Agile Principles and PracticesRating: 4.5 out of 5 stars4.5/5 (27)
- PMP Exam Prep: Master the Latest Techniques and Trends with this In-depth Project Management Professional Guide: Study Guide | Real-life PMP Questions and Detailed Explanation | 200+ Questions and AnswersFrom EverandPMP Exam Prep: Master the Latest Techniques and Trends with this In-depth Project Management Professional Guide: Study Guide | Real-life PMP Questions and Detailed Explanation | 200+ Questions and AnswersRating: 5 out of 5 stars5/5 (2)
- Building a Second Brain: A Proven Method to Organize Your Digital Life and Unlock Your Creative PotentialFrom EverandBuilding a Second Brain: A Proven Method to Organize Your Digital Life and Unlock Your Creative PotentialRating: 4 out of 5 stars4/5 (113)
- The Manager's Path: A Guide for Tech Leaders Navigating Growth and ChangeFrom EverandThe Manager's Path: A Guide for Tech Leaders Navigating Growth and ChangeRating: 4.5 out of 5 stars4.5/5 (99)
- Harvard Business Review Project Management Handbook: How to Launch, Lead, and Sponsor Successful ProjectsFrom EverandHarvard Business Review Project Management Handbook: How to Launch, Lead, and Sponsor Successful ProjectsRating: 4.5 out of 5 stars4.5/5 (15)
- Project Management For Beginners: The ultimate beginners guide to fast & effective project management!From EverandProject Management For Beginners: The ultimate beginners guide to fast & effective project management!Rating: 4 out of 5 stars4/5 (1)
- Change Management for Beginners: Understanding Change Processes and Actively Shaping ThemFrom EverandChange Management for Beginners: Understanding Change Processes and Actively Shaping ThemRating: 4.5 out of 5 stars4.5/5 (3)
- The Digital Transformation Playbook - SECOND Edition: What You Need to Know and DoFrom EverandThe Digital Transformation Playbook - SECOND Edition: What You Need to Know and DoNo ratings yet
- Project Management: The Ultimate Guide for Managing Projects, Productivity, Profits of Enterprises, Startups and Planning with Lean, Scrum, Agile.From EverandProject Management: The Ultimate Guide for Managing Projects, Productivity, Profits of Enterprises, Startups and Planning with Lean, Scrum, Agile.Rating: 4.5 out of 5 stars4.5/5 (3)
- PMP Exam Prep: How to pass the PMP Exam on your First Attempt – Learn Faster, Retain More and Pass the PMP ExamFrom EverandPMP Exam Prep: How to pass the PMP Exam on your First Attempt – Learn Faster, Retain More and Pass the PMP ExamRating: 4.5 out of 5 stars4.5/5 (3)
- Crossing the Chasm, 3rd Edition: Marketing and Selling Disruptive Products to Mainstream CustomersFrom EverandCrossing the Chasm, 3rd Edition: Marketing and Selling Disruptive Products to Mainstream CustomersRating: 4.5 out of 5 stars4.5/5 (19)
- Project Management All-in-One For DummiesFrom EverandProject Management All-in-One For DummiesRating: 5 out of 5 stars5/5 (6)
- Secrets of Home Staging: The Essential Guide to Getting Higher Offers Faster (Home décor ideas, design tips, and advice on staging your home)From EverandSecrets of Home Staging: The Essential Guide to Getting Higher Offers Faster (Home décor ideas, design tips, and advice on staging your home)No ratings yet
- PMP Exam Code Cracked: Success Strategies and Quick Questions to Crush the TestFrom EverandPMP Exam Code Cracked: Success Strategies and Quick Questions to Crush the TestNo ratings yet