You might also like
- Mach 3 MillDocument157 pagesMach 3 Millafricano333100% (1)
- Consent Form For Telemedicine ConsultationDocument3 pagesConsent Form For Telemedicine ConsultationAdmin dahsNo ratings yet
- Class 10 Free Span AnalysisDocument37 pagesClass 10 Free Span AnalysisLK AnhDungNo ratings yet
- Experiment No: 4-Characteristics of BJT in CE Configuration AimDocument6 pagesExperiment No: 4-Characteristics of BJT in CE Configuration AimGANESH KUMAR B eee2018100% (2)
- Post-Processing APDL Models Inside ANSYS® Workbench v15Document26 pagesPost-Processing APDL Models Inside ANSYS® Workbench v15LK AnhDungNo ratings yet
- Inspection Maintenance and Repair of Deepwater Pipelines PDFDocument51 pagesInspection Maintenance and Repair of Deepwater Pipelines PDFLK AnhDung100% (2)
- Runge Kutta MethodDocument33 pagesRunge Kutta MethodHemangi Priya Devi Dasi100% (1)
- Yu 等。 - 2021 - Frequency-Aware Spatiotemporal Transformers for ViDocument10 pagesYu 等。 - 2021 - Frequency-Aware Spatiotemporal Transformers for Vitadeas kellyNo ratings yet
- 2018 WarpingErrorDocument16 pages2018 WarpingErrorlaura.alvargonzaNo ratings yet
- A Simple Baseline For Video Restoration With Grouped Spatial-Temporal ShiftDocument14 pagesA Simple Baseline For Video Restoration With Grouped Spatial-Temporal Shift黃丰楷No ratings yet
- Direction Oriented Fast Iterative Block Based Video Inpainting Using Morphological Operations and SSDDocument10 pagesDirection Oriented Fast Iterative Block Based Video Inpainting Using Morphological Operations and SSDShanmuganathan V (RC2113003011029)No ratings yet
- Qiu Learning Spatio-Temporal Representation ICCV 2017 PaperDocument9 pagesQiu Learning Spatio-Temporal Representation ICCV 2017 Papermjt0207No ratings yet
- Learning Video Object Segmentation From Static ImagesDocument10 pagesLearning Video Object Segmentation From Static ImagesJunaid KNo ratings yet
- Tokenlearner: What Can 8 Learned Tokens Do For Images and Videos?Document21 pagesTokenlearner: What Can 8 Learned Tokens Do For Images and Videos?Papasanimohan SrinivasNo ratings yet
- Photorealistic Video Generation With Diffusion ModelsDocument13 pagesPhotorealistic Video Generation With Diffusion ModelsSayan HaldarNo ratings yet
- Blazingly Fast SegDocument10 pagesBlazingly Fast SegadityaNo ratings yet
- Teco GANDocument19 pagesTeco GANИпцаэлNo ratings yet
- TPSeNCE: Towards Artifact-Free Realistic Rain Generation For Deraining and Object Detection in RainDocument7 pagesTPSeNCE: Towards Artifact-Free Realistic Rain Generation For Deraining and Object Detection in Rainmallikarjunareddy kotaNo ratings yet
- Aafaq Spatio-Temporal Dynamics and Semantic Attribute Enriched Visual Encoding For Video CVPR 2019 PaperDocument10 pagesAafaq Spatio-Temporal Dynamics and Semantic Attribute Enriched Visual Encoding For Video CVPR 2019 Paperford ferrariNo ratings yet
- Learning Video Object Segmentation From Static ImagesDocument16 pagesLearning Video Object Segmentation From Static ImagesAlejandro PosadaNo ratings yet
- Maggie: Masked Guided Gradual Human Instance MattingDocument26 pagesMaggie: Masked Guided Gradual Human Instance Mattingsofic94935No ratings yet
- Temporal Feature Warping For Video Shadow DetectioDocument12 pagesTemporal Feature Warping For Video Shadow DetectioPriyal MehtaNo ratings yet
- Spatiotemporal Integration Network For Video Saliency Detection....Document18 pagesSpatiotemporal Integration Network For Video Saliency Detection....GALLEGO LUPIANEZNo ratings yet
- Attention 2Document15 pagesAttention 2neetu siggerNo ratings yet
- Deep Affine Motion Compensation Network For Inter Prediction in VVCDocument11 pagesDeep Affine Motion Compensation Network For Inter Prediction in VVCMateus AraújoNo ratings yet
- EI 2017 Art00004 Grigorios-TsagkatakisDocument6 pagesEI 2017 Art00004 Grigorios-Tsagkatakismr.parth147No ratings yet
- Video Transformer NetworkDocument11 pagesVideo Transformer NetworkAqib MumtazNo ratings yet
- A Review Enhancement of Degraded VideoDocument4 pagesA Review Enhancement of Degraded VideoEditor IJRITCCNo ratings yet
- Video Representation Learning by Dense Predictive Coding 1909.04656Document13 pagesVideo Representation Learning by Dense Predictive Coding 1909.04656FgpeqwNo ratings yet
- Review Paper Yonas - BrhanuDocument4 pagesReview Paper Yonas - BrhanuyonasNo ratings yet
- Ma 等。 - 2020 - Efficient and Fast Real-World Noisy Image DenoisinDocument14 pagesMa 等。 - 2020 - Efficient and Fast Real-World Noisy Image DenoisinNex VinsNo ratings yet
- Zhang Deep Exemplar-Based Video Colorization CVPR 2019 PaperDocument10 pagesZhang Deep Exemplar-Based Video Colorization CVPR 2019 Paperzeeh2005No ratings yet
- Real-Time Foreground Segmentation and Boundary Matting For Live Videos Using SVM TechniqueDocument5 pagesReal-Time Foreground Segmentation and Boundary Matting For Live Videos Using SVM TechniqueRiya soniNo ratings yet
- FRESCODocument10 pagesFRESCOxepit98367No ratings yet
- Event Management Using End-To-End Image Encryption A ReviewDocument7 pagesEvent Management Using End-To-End Image Encryption A ReviewIJRASETPublicationsNo ratings yet
- High-Fidelity Pluralistic Image Completion With TransformersDocument10 pagesHigh-Fidelity Pluralistic Image Completion With TransformersTCOC33T Shivani RaoNo ratings yet
- Quo Vadis, Action Recognition? A New Model and The Kinetics DatasetDocument10 pagesQuo Vadis, Action Recognition? A New Model and The Kinetics DatasetAkashGargNo ratings yet
- Temporal Segment Networks: Towards Good Practices For Deep Action RecognitionDocument16 pagesTemporal Segment Networks: Towards Good Practices For Deep Action RecognitionAkashGargNo ratings yet
- Unsupervised Learning of Depth and Ego-Motion From VideoDocument10 pagesUnsupervised Learning of Depth and Ego-Motion From VideoSagar URNo ratings yet
- Spatio-Temporal Deformable Convolution For Compressed Video Quality EnhancementDocument8 pagesSpatio-Temporal Deformable Convolution For Compressed Video Quality EnhancementSunilmahek MahekNo ratings yet
- Collaborative Video Object Segmentation by Foreground-Background IntegrationDocument17 pagesCollaborative Video Object Segmentation by Foreground-Background Integrationkaran tanwarNo ratings yet
- Rubiksnet: Learnable 3D-Shift For Efficient Video Action RecognitionDocument17 pagesRubiksnet: Learnable 3D-Shift For Efficient Video Action RecognitionJames Rafael BNo ratings yet
- Masked Autoencoders As Spatiotemporal LearnersDocument13 pagesMasked Autoencoders As Spatiotemporal Learnersperry1005No ratings yet
- CoCoCo: Improving Text-Guided Video Inpainting For Better Consistency, Controllability and CompatibilityDocument23 pagesCoCoCo: Improving Text-Guided Video Inpainting For Better Consistency, Controllability and Compatibilityxepit98367No ratings yet
- EdgeConnect Structure Guided Image Inpainting Using Edge PredictionDocument10 pagesEdgeConnect Structure Guided Image Inpainting Using Edge Predictiontthod37No ratings yet
- Cite 255 Single Shot Temporal Action Detection ACM M 2017Document9 pagesCite 255 Single Shot Temporal Action Detection ACM M 2017姜华为No ratings yet
- Bise NetDocument17 pagesBise NetdasdasdNo ratings yet
- Robust CVDDocument11 pagesRobust CVDqwertyNo ratings yet
- Adversarial Steganography Embedding Via Stego Generation and SelectionDocument15 pagesAdversarial Steganography Embedding Via Stego Generation and SelectionSowmyaNo ratings yet
- Frame-Skip Convolutional Neural Networks For Action RecognitionDocument6 pagesFrame-Skip Convolutional Neural Networks For Action RecognitionMitchell Angel Gomez OrtegaNo ratings yet
- Zhou Breaking Through The Haze An Advanced Non-Homogeneous Dehazing Method Based CVPRW 2023 PaperDocument10 pagesZhou Breaking Through The Haze An Advanced Non-Homogeneous Dehazing Method Based CVPRW 2023 Paperlohithinfinite154No ratings yet
- Efficient Hybrid Tree-Based Stereo Matching With Applications To Postcapture Image RefocusingDocument15 pagesEfficient Hybrid Tree-Based Stereo Matching With Applications To Postcapture Image RefocusingIsaac AnamanNo ratings yet
- DL SurveyDocument12 pagesDL SurveyYe DuNo ratings yet
- Codef: Content Deformation Fields For Temporally Consistent Video ProcessingDocument11 pagesCodef: Content Deformation Fields For Temporally Consistent Video Processingdvae fredNo ratings yet
- Transformer-Based Image CompressionDocument10 pagesTransformer-Based Image CompressionBolivar Omar PacaNo ratings yet
- Video-to-Video Synthesis: WebsiteDocument14 pagesVideo-to-Video Synthesis: WebsiteCristian CarlosNo ratings yet
- Learning Spatiotemporal Features With 3D Convolutional NetworksDocument16 pagesLearning Spatiotemporal Features With 3D Convolutional NetworksVenkata PraneethNo ratings yet
- Terbouche Multi-Annotation Attention Model For Video Summarization CVPRW 2023 PaperDocument10 pagesTerbouche Multi-Annotation Attention Model For Video Summarization CVPRW 2023 Paper22 / Gyanaranjan NayakNo ratings yet
- Li Lets See Clearly Contaminant Artifact Removal For Moving Cameras ICCV 2021 PaperDocument10 pagesLi Lets See Clearly Contaminant Artifact Removal For Moving Cameras ICCV 2021 PaperPS InnovationsNo ratings yet
- Monovit: Self-Supervised Monocular Depth Estimation With A Vision TransformerDocument11 pagesMonovit: Self-Supervised Monocular Depth Estimation With A Vision TransformerPengZai ZhongNo ratings yet
- Semantic-Guided Selective Representation For ImageDocument10 pagesSemantic-Guided Selective Representation For ImageTomislav IvandicNo ratings yet
- Applsci 11 08802 - CompressedDocument28 pagesApplsci 11 08802 - CompressedIlias PapadeasNo ratings yet
- S Patio Temporal Kernel RegressionDocument18 pagesS Patio Temporal Kernel Regressionsonalidhali157622No ratings yet
- AdaStereo (2021)Document18 pagesAdaStereo (2021)Elizabeth MartinezNo ratings yet
- MIT DriveSeg ManualDocument5 pagesMIT DriveSeg ManualsummrinaNo ratings yet
- A Deep CNN Method For Underwater Image EnhancementDocument5 pagesA Deep CNN Method For Underwater Image EnhancementSepta CahyaniNo ratings yet
- Embedded Deep Learning: Algorithms, Architectures and Circuits for Always-on Neural Network ProcessingFrom EverandEmbedded Deep Learning: Algorithms, Architectures and Circuits for Always-on Neural Network ProcessingNo ratings yet
- Swapping Autoencoder For Deep Image Manipulation: WebpageDocument23 pagesSwapping Autoencoder For Deep Image Manipulation: WebpageLK AnhDungNo ratings yet
- Hybrid Deep Learning For Detecting Lung Diseases From X-Ray ImagesDocument23 pagesHybrid Deep Learning For Detecting Lung Diseases From X-Ray ImagesLK AnhDungNo ratings yet
- Embedding Expansion: Augmentation in Embedding Space For Deep Metric LearningDocument14 pagesEmbedding Expansion: Augmentation in Embedding Space For Deep Metric LearningLK AnhDungNo ratings yet
- COVID-19 Chest CT Image Segmentation - A Deep Convolutional Neural Network SolutionDocument10 pagesCOVID-19 Chest CT Image Segmentation - A Deep Convolutional Neural Network SolutionLK AnhDungNo ratings yet
- Chul H. JoDocument1 pageChul H. JoLK AnhDungNo ratings yet
- Meshing Methods (ANSYS Meshing) - Everyone Is Number OneDocument14 pagesMeshing Methods (ANSYS Meshing) - Everyone Is Number OneLK AnhDungNo ratings yet
- User ManualDocument70 pagesUser ManualLK AnhDungNo ratings yet
- Understanding DM: Parts and Bodies: April 28, 2006 Issue 47Document5 pagesUnderstanding DM: Parts and Bodies: April 28, 2006 Issue 47LK AnhDungNo ratings yet
- Meshing Methods - HexahedralDocument2 pagesMeshing Methods - HexahedralLK AnhDungNo ratings yet
- Networking TechnologyDocument55 pagesNetworking TechnologyLK AnhDungNo ratings yet
- CAD IntegrationDocument122 pagesCAD IntegrationLK AnhDungNo ratings yet
- Network Design Using Access Controls and Voip: Saurav Kumar PandeyDocument46 pagesNetwork Design Using Access Controls and Voip: Saurav Kumar PandeyLK AnhDungNo ratings yet
- Finite Element Method: Fem For 3D SolidsDocument46 pagesFinite Element Method: Fem For 3D SolidsLK AnhDungNo ratings yet
- Result KSDDocument17 pagesResult KSDrakumar500No ratings yet
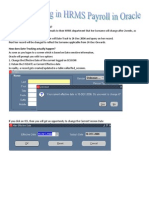
- Date Tracking in Oracle HRMSDocument3 pagesDate Tracking in Oracle HRMSBick KyyNo ratings yet
- Orthogonal Frequency Division Multiplexing (OFDM) : Concept and System-ModelingDocument31 pagesOrthogonal Frequency Division Multiplexing (OFDM) : Concept and System-ModelingAsif_Iqbal_8466No ratings yet
- BLEMBA 30 - Syndicate 1 - Financial DetectiveDocument20 pagesBLEMBA 30 - Syndicate 1 - Financial DetectiveDyani Nabyla Widyaputri0% (1)
- Modified Seven-Level Pack U-Cell Inverter For Photovoltaic ApplicationsDocument9 pagesModified Seven-Level Pack U-Cell Inverter For Photovoltaic ApplicationsSPOOKY WARRIORSNo ratings yet
- Crash Analysis and SimulationDocument26 pagesCrash Analysis and SimulationNyakakussagaNo ratings yet
- Comp 100 ReviewerDocument3 pagesComp 100 ReviewerFionalee B.No ratings yet
- II IIR18 IT DBMS (0) FGDocument5 pagesII IIR18 IT DBMS (0) FGManish BhatiaNo ratings yet
- Introduction ToDocument83 pagesIntroduction ToRambhupalReddy100% (1)
- Kaspersky Statement Regarding Data Processing For Marketing Purposes (Marketing Statement)Document2 pagesKaspersky Statement Regarding Data Processing For Marketing Purposes (Marketing Statement)j4k4l0d4n9No ratings yet
- HVX-O 36Kv Catalogue DNFDocument44 pagesHVX-O 36Kv Catalogue DNFAction GamesNo ratings yet
- SIMATIC S7-300 S7-300 CPU Data: CPU 315T-2 DPDocument127 pagesSIMATIC S7-300 S7-300 CPU Data: CPU 315T-2 DPNguyễn Quang HảoNo ratings yet
- Example Fast Fourier Oppenheim PDF TransformDocument2 pagesExample Fast Fourier Oppenheim PDF TransformJamesNo ratings yet
- International Law On Cyber Security in The Age of Digital Sovereignty PDFDocument5 pagesInternational Law On Cyber Security in The Age of Digital Sovereignty PDFPk MullickNo ratings yet
- Fig: Dual Beam CRO With Separate Time BasesDocument27 pagesFig: Dual Beam CRO With Separate Time BasesYashaswiniNo ratings yet
- Cod.390S.B: Instruction ManualDocument24 pagesCod.390S.B: Instruction ManualAshrafNo ratings yet
- PVS-16/20/24MH: PV Combiner Box For SystemDocument1 pagePVS-16/20/24MH: PV Combiner Box For SystemThắng CòiNo ratings yet
- Anime Face Generation Using DC-GANsDocument6 pagesAnime Face Generation Using DC-GANsHSSSHSNo ratings yet
- 5 6 ArrayDocument48 pages5 6 ArrayG tarikNo ratings yet
- ROBOTICSDocument14 pagesROBOTICSShyam NaiduNo ratings yet
- Vmware Techinical DocumentDocument14 pagesVmware Techinical DocumentsameervmNo ratings yet
- lastCleanException 20220424185711Document19 pageslastCleanException 20220424185711beom choiNo ratings yet
- DVDR3570H - SB KL Ex Si - 1221814332Document54 pagesDVDR3570H - SB KL Ex Si - 1221814332olomouc7267No ratings yet
- Project Name: Stephanie's Ponytail Class: FRIT: 7233Document4 pagesProject Name: Stephanie's Ponytail Class: FRIT: 7233Melanie Brooke KirbyNo ratings yet
- Jurnal Internasional IBM11!3!5523 5529XXXXXXDocument7 pagesJurnal Internasional IBM11!3!5523 5529XXXXXXLidya SNo ratings yet
- High-Wattage General Purpose Relay: Small PCB Relay For Automobile UseDocument3 pagesHigh-Wattage General Purpose Relay: Small PCB Relay For Automobile Usesuan kwang TanNo ratings yet