You might also like
- BK2000 - 2e - Probability and Measure Theory - Ash and Doleans-DadeDocument541 pagesBK2000 - 2e - Probability and Measure Theory - Ash and Doleans-DadeBaiyi Wu100% (1)
- Information TheoryDocument48 pagesInformation Theorynumlock_100% (1)
- Shumway and StofferDocument5 pagesShumway and StofferReem SakNo ratings yet
- (A. Hernando, A. Plastino and A.R. Plastino) MaxEnDocument8 pages(A. Hernando, A. Plastino and A.R. Plastino) MaxEnJPiero 777No ratings yet
- On Lower Bounds For Statistical Learning TheoryDocument17 pagesOn Lower Bounds For Statistical Learning TheoryBill PetrieNo ratings yet
- Pde 1707.02568Document13 pagesPde 1707.02568heavywaterNo ratings yet
- Principle of Maximum EntropyDocument10 pagesPrinciple of Maximum Entropydev414No ratings yet
- Inverse Problems Quest For Information: V, Leads To A Solution VDocument12 pagesInverse Problems Quest For Information: V, Leads To A Solution VRahul ShajNo ratings yet
- Matrix Product States, Random Matrix Theory and The Principle of Maximum EntropyDocument15 pagesMatrix Product States, Random Matrix Theory and The Principle of Maximum EntropyFernando GuerreroNo ratings yet
- Statistical Mechanics of On-Line LearningDocument23 pagesStatistical Mechanics of On-Line LearningmorepjNo ratings yet
- Statistics Lecture NotesDocument15 pagesStatistics Lecture NotesAriel MorgensternNo ratings yet
- Opinion Particles: Classical Physics and Opinion DynamicsDocument19 pagesOpinion Particles: Classical Physics and Opinion DynamicsAldiarso UtomoNo ratings yet
- Inverse Problems Quest For InformationDocument16 pagesInverse Problems Quest For Informationbm_niculescuNo ratings yet
- Stat Phys Info TheoDocument214 pagesStat Phys Info TheomaxhkNo ratings yet
- ML Unit IIIDocument40 pagesML Unit IIIVasu 22No ratings yet
- A Philosophical Analysis of Bayesian ModDocument32 pagesA Philosophical Analysis of Bayesian ModArthur CostaNo ratings yet
- Solving High-Dimensional Partial Differential Equations Using Deep LearningDocument14 pagesSolving High-Dimensional Partial Differential Equations Using Deep LearningJames MattosNo ratings yet
- 16992-Article Text-20486-1-2-20210518Document9 pages16992-Article Text-20486-1-2-20210518julio.dutraNo ratings yet
- Risk Evaluation in Failure Mode and Effects Analysis Based On D Numbers TheoryDocument20 pagesRisk Evaluation in Failure Mode and Effects Analysis Based On D Numbers TheoryasiyahNo ratings yet
- Bayesian Modeling of Human Concept Learning - Tenenbaum 1999Document7 pagesBayesian Modeling of Human Concept Learning - Tenenbaum 1999Carlos ArayaNo ratings yet
- Statistics For The LHC: Progress, Challenges, and Future: Kyle S. CranmerDocument14 pagesStatistics For The LHC: Progress, Challenges, and Future: Kyle S. CranmerMarcelo Irigoyen GimenaNo ratings yet
- Symmetry in Optics and Photonics A Group Theory ApproachDocument12 pagesSymmetry in Optics and Photonics A Group Theory ApproachMurat YücelNo ratings yet
- Kerja Kursus Add MatDocument8 pagesKerja Kursus Add MatSyira SlumberzNo ratings yet
- Principal Component Analysis For Data Containing Outliers and Missing ElementsDocument16 pagesPrincipal Component Analysis For Data Containing Outliers and Missing ElementsDeeptimayee SahooNo ratings yet
- Lancaster - Sample Chapter - Intro To Modern Bayesian EconometricsDocument69 pagesLancaster - Sample Chapter - Intro To Modern Bayesian Econometricsperri_dimaanoNo ratings yet
- Entropy: Statistical Information: A Bayesian PerspectiveDocument11 pagesEntropy: Statistical Information: A Bayesian PerspectiveMiguel Angel HrndzNo ratings yet
- On Two Micromechanics Theories For Determining Micro Macro Relations in Heterogeneous SolidsDocument16 pagesOn Two Micromechanics Theories For Determining Micro Macro Relations in Heterogeneous Solidsdavibarbosa91No ratings yet
- ZozorBrcher - EntropyDocument32 pagesZozorBrcher - EntropyCaehhsegffNo ratings yet
- Axioms: Optimization Models For Reaction Networks: Information Divergence, Quadratic Programming and Kirchhoff's LawsDocument10 pagesAxioms: Optimization Models For Reaction Networks: Information Divergence, Quadratic Programming and Kirchhoff's LawscliffordNo ratings yet
- Stochastic Approximations and Differential Inclusions, Part II: ApplicationsDocument23 pagesStochastic Approximations and Differential Inclusions, Part II: ApplicationsMark Edward GonzalesNo ratings yet
- AI Mod4@AzDOCUMENTS - inDocument41 pagesAI Mod4@AzDOCUMENTS - inBhavana NagarajNo ratings yet
- Received 16 November 2016 Accepted 9 May 2017Document14 pagesReceived 16 November 2016 Accepted 9 May 2017Hamza DhakerNo ratings yet
- The World According To R Enyi: Thermodynamics of Multifractal SystemsDocument23 pagesThe World According To R Enyi: Thermodynamics of Multifractal SystemsIrene AdlerNo ratings yet
- Bayesian FusionDocument32 pagesBayesian FusionJasmeet SinghNo ratings yet
- Empirical Bayes For Learning To LearnDocument8 pagesEmpirical Bayes For Learning To Learnmariana henteaNo ratings yet
- A Multidimensional Unfolding Method Based On Bayes' TheoremDocument12 pagesA Multidimensional Unfolding Method Based On Bayes' TheoremAresshioNo ratings yet
- 2012 Entropy StatstInform A.BayesianPerspectiveDocument12 pages2012 Entropy StatstInform A.BayesianPerspectiveKenneth UgaldeNo ratings yet
- From Continuum Mechanics To SPH Particle Systems and Back: Systematic Derivation and ConvergenceDocument28 pagesFrom Continuum Mechanics To SPH Particle Systems and Back: Systematic Derivation and ConvergenceManish Kumar SinghNo ratings yet
- Zayernouri 2016 ADocument14 pagesZayernouri 2016 ARed WarNo ratings yet
- Yet Another Resolution of The Gibbs Paradox: An Information Theory ApproachDocument10 pagesYet Another Resolution of The Gibbs Paradox: An Information Theory ApproachMatteo ScandiNo ratings yet
- DatascienceDocument14 pagesDatasciencejoseluisapNo ratings yet
- 1983 S Baker R D Cousins-NIM 221 437-442Document6 pages1983 S Baker R D Cousins-NIM 221 437-442shusakuNo ratings yet
- Conditional Density Estimation With Neural NetworkDocument41 pagesConditional Density Estimation With Neural Networkالشمس اشرقتNo ratings yet
- SaifDocument20 pagesSaifMaliCk TaimoorNo ratings yet
- Metaheuristic Optimization: Algorithm Analysis and Open ProblemsDocument12 pagesMetaheuristic Optimization: Algorithm Analysis and Open ProblemsOlivia brianneNo ratings yet
- Practical Statistics For Particle Physics: © CERN, 2020,,, ISSN 0531-4283Document49 pagesPractical Statistics For Particle Physics: © CERN, 2020,,, ISSN 0531-4283Tuan PhamNo ratings yet
- Richard Durbin Sean Eddy Anders Krogh Graeme MitchisonDocument25 pagesRichard Durbin Sean Eddy Anders Krogh Graeme MitchisonJagjeet DhaliwalNo ratings yet
- Bayesian Statistics and Quality Modelling in The - Groen Kennisnet 134085Document15 pagesBayesian Statistics and Quality Modelling in The - Groen Kennisnet 134085MiltonNo ratings yet
- Simulating Normalizing Constants: From Importance Sampling To Bridge Sampling To Path SamplingDocument23 pagesSimulating Normalizing Constants: From Importance Sampling To Bridge Sampling To Path SamplingminaskarNo ratings yet
- Generalized Gleason Theorem and Contextuality: 1 2 M M N 1 N K KDocument8 pagesGeneralized Gleason Theorem and Contextuality: 1 2 M M N 1 N K KjrashidNo ratings yet
- Gibbs Sampling For The UninitiatedDocument23 pagesGibbs Sampling For The Uninitiatedmirando93No ratings yet
- Conditional Likelihood Maximisation: A Unifying Framework For Information Theoretic Feature SelectionDocument40 pagesConditional Likelihood Maximisation: A Unifying Framework For Information Theoretic Feature SelectionSudhit SethiNo ratings yet
- Bin Pois PRIDocument19 pagesBin Pois PRIImdadul HaqueNo ratings yet
- DL-PDE: Deep-Learning Based Data-Driven Discovery of Partial Differential Equations From Discrete and Noisy DataDocument28 pagesDL-PDE: Deep-Learning Based Data-Driven Discovery of Partial Differential Equations From Discrete and Noisy DataAman JalanNo ratings yet
- Joint MLEDocument34 pagesJoint MLEAjay DhamijaNo ratings yet
- A Hybrid Particle Swarm Evolutionary Algorithm For Constrained Multi-Objective Optimization Jingxuan WeiDocument18 pagesA Hybrid Particle Swarm Evolutionary Algorithm For Constrained Multi-Objective Optimization Jingxuan WeithavaselvanNo ratings yet
- Hilpisch 2020 Artificial Intelligence in Finance 1 477 PagesDocument7 pagesHilpisch 2020 Artificial Intelligence in Finance 1 477 Pagesthuyph671No ratings yet
- Lecture 1 2019 Thermo ReviewDocument9 pagesLecture 1 2019 Thermo ReviewJay SteeleNo ratings yet
- Teaching Bayes' Theorem: Strength of Evidence As Predictive AccuracyDocument18 pagesTeaching Bayes' Theorem: Strength of Evidence As Predictive AccuracySigit WahyudiNo ratings yet
- Bayesian Analysis of Extreme Operational Losses: Chyng-Lan LiangDocument17 pagesBayesian Analysis of Extreme Operational Losses: Chyng-Lan LiangOnkar BagariaNo ratings yet
- Family Member Search Algorithms For Peridynamic AnDocument27 pagesFamily Member Search Algorithms For Peridynamic AnNur Anira AsyikinNo ratings yet
- ACST356 Section 4 Complete NotesDocument29 pagesACST356 Section 4 Complete NotesAnNo ratings yet
- Probability Test PDFDocument4 pagesProbability Test PDFSithmi HimashaNo ratings yet
- Basic Statistics (Course Outline)Document1 pageBasic Statistics (Course Outline)Yohannes AlemuNo ratings yet
- Poisson Mixture ModelsDocument21 pagesPoisson Mixture ModelsSebaNo ratings yet
- Lec25 1121Document12 pagesLec25 1121aqszaqszNo ratings yet
- 19 250 HW2Document8 pages19 250 HW2Erman KurterNo ratings yet
- Rules of Probability: Prepared By: Engr. Gilbey'S Jhon - Ladion InstructorDocument25 pagesRules of Probability: Prepared By: Engr. Gilbey'S Jhon - Ladion InstructorMark B. BarrogaNo ratings yet
- Uecm3243 Topic 1Document16 pagesUecm3243 Topic 1YU XUAN LEENo ratings yet
- Bayes' Theorem: Probability Theory StatisticsDocument9 pagesBayes' Theorem: Probability Theory StatisticsVanlal KhiangteNo ratings yet
- Croon's Bias-Corrected Factor Score Path Analysis For Small-To Moderate - Sample Multilevel Structural Equation ModelsDocument23 pagesCroon's Bias-Corrected Factor Score Path Analysis For Small-To Moderate - Sample Multilevel Structural Equation ModelsPhuoc NguyenNo ratings yet
- Ips-1, 2017Document21 pagesIps-1, 2017Mayank KumarNo ratings yet
- ISLR Chap 4 ShaheryarDocument16 pagesISLR Chap 4 ShaheryarShaheryar ZahurNo ratings yet
- An Introduction To Modern Bayesian Econometrics: Tony Lancaster May 26, 2003Document10 pagesAn Introduction To Modern Bayesian Econometrics: Tony Lancaster May 26, 2003gabrielsarmanhoNo ratings yet
- Moments and Moment Generating FunctionsDocument17 pagesMoments and Moment Generating FunctionsDharamNo ratings yet
- Measures of DispersionDocument23 pagesMeasures of DispersionAarushi Sharma67% (3)
- Assignment Task II Task 2: Bu Ildi NG Ty Pe S Count of V4Document9 pagesAssignment Task II Task 2: Bu Ildi NG Ty Pe S Count of V4Abishek RisalNo ratings yet
- Theoretical Distribution Statistics)Document22 pagesTheoretical Distribution Statistics)KNOWLEDGE CREATORS50% (2)
- Parameter Estimation For The Truncated Pareto DistributionDocument22 pagesParameter Estimation For The Truncated Pareto Distributionagbas20026896No ratings yet
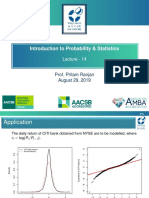
- Introduction To Probability & Statistics: Lecture - 14Document28 pagesIntroduction To Probability & Statistics: Lecture - 14Venkatesh MundadaNo ratings yet
- Estimation of Parameters FinalDocument23 pagesEstimation of Parameters FinalMay Ann MonteroNo ratings yet
- Busstat Module 2Document11 pagesBusstat Module 2CARL JAMESNo ratings yet
- Lab 5 - Elementary Statistics With R - Matlab - Numerical MeasuresDocument8 pagesLab 5 - Elementary Statistics With R - Matlab - Numerical MeasuresSam Caunca OrtizNo ratings yet
- Calculation of Erlang Capacity For Cellular CDMA Uplink SystemsDocument5 pagesCalculation of Erlang Capacity For Cellular CDMA Uplink SystemsBouziane BeldjilaliNo ratings yet
- Stat&Prob Module 1 EditedDocument14 pagesStat&Prob Module 1 EditedJeycelNo ratings yet
- STA222 Week7Document14 pagesSTA222 Week7Kimondo KingNo ratings yet
- Discrete Structures For Computing: Huynh Tuong Nguyen, Tran Tuan Anh, Nguyen Ngoc LeDocument27 pagesDiscrete Structures For Computing: Huynh Tuong Nguyen, Tran Tuan Anh, Nguyen Ngoc LeLê Văn HoàngNo ratings yet
- PRP NotesDocument10 pagesPRP NotesBharath JojoNo ratings yet
- Math Investigatory ProjectDocument15 pagesMath Investigatory ProjectrahulNo ratings yet