You might also like
- Lec5 6Document32 pagesLec5 6abhinav kumarNo ratings yet
- The Virtual Flute: An Advanced Fingering Guide Generated Via Machine IntelligenceDocument14 pagesThe Virtual Flute: An Advanced Fingering Guide Generated Via Machine IntelligenceZachNo ratings yet
- Lec9-10 Speech ProcessingDocument34 pagesLec9-10 Speech Processingabhinav kumarNo ratings yet
- The Acoustics of Wind Instruments - and of The Musicians Who Play ThemDocument10 pagesThe Acoustics of Wind Instruments - and of The Musicians Who Play ThemÀlber CatalàNo ratings yet
- 2010 Bromage Al Acustica OpenAreasOfVibratingLlipsInTrombonePlaying PDFDocument32 pages2010 Bromage Al Acustica OpenAreasOfVibratingLlipsInTrombonePlaying PDFAndré QianNo ratings yet
- Klatt Formant SynthesizerDocument49 pagesKlatt Formant Synthesizeramariac810No ratings yet
- Synthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezDocument5 pagesSynthesis of Diplophonic and Biphonic Voices: Y. Bennane, A. Kacha F. GrenezZellagui EnergyNo ratings yet
- Signal Processing in Auditory Neuroscience: Temporal and Spatial Features of Sound and SpeechFrom EverandSignal Processing in Auditory Neuroscience: Temporal and Spatial Features of Sound and SpeechNo ratings yet
- The Acoustics of Wind InstrumentsDocument10 pagesThe Acoustics of Wind InstrumentsagjNo ratings yet
- Speech Signal ProcessingDocument173 pagesSpeech Signal ProcessingLizy Abraham100% (2)
- A Practical Handbook of Speech CodersDocument14 pagesA Practical Handbook of Speech CodersVany BraunNo ratings yet
- Assignment On SpeechDocument9 pagesAssignment On SpeechKH Khaleduzzaman ShawonNo ratings yet
- Chap 16 SMDocument88 pagesChap 16 SMzenrocNo ratings yet
- Compound Subjects and PredicatesDocument110 pagesCompound Subjects and Predicatesakanksha09No ratings yet
- Acoustis in Performance HallDocument7 pagesAcoustis in Performance HallGanesan SolomonNo ratings yet
- Acoustic and Auditory Phonetics The Adaptive DesigDocument15 pagesAcoustic and Auditory Phonetics The Adaptive DesigSparrow WingsNo ratings yet
- Talking Heads Speech ProductionDocument3 pagesTalking Heads Speech ProductionNurhazreen KadirNo ratings yet
- Bjrkner JVoice 08Document9 pagesBjrkner JVoice 08Laura RakauskaitėNo ratings yet
- Bjrkner JVoice 08Document9 pagesBjrkner JVoice 08Mariana RobledoNo ratings yet
- A Theoretical TromboneDocument8 pagesA Theoretical Trombonethomas.patteson6837No ratings yet
- 01 Lissajous Curves Experiment ManualDocument3 pages01 Lissajous Curves Experiment ManualDeo CaviteNo ratings yet
- SLAWSON - The Color of SoundDocument11 pagesSLAWSON - The Color of SoundEmmaNo ratings yet
- Toymodel JSV HALDocument18 pagesToymodel JSV HALJean VictorNo ratings yet
- B&K LoudspeakerDocument16 pagesB&K LoudspeakerAnthony HubbardNo ratings yet
- Acoustic Signals and Hearing: A Time-Envelope and Phase Spectral ApproachFrom EverandAcoustic Signals and Hearing: A Time-Envelope and Phase Spectral ApproachNo ratings yet
- 1 s2.0 S0892199715001587 MainDocument9 pages1 s2.0 S0892199715001587 MainTiago BicalhoNo ratings yet
- Sound and Hearing (Chapter 16)Document64 pagesSound and Hearing (Chapter 16)Robert Tawanda Mutasa100% (1)
- Superposition and Standing Waves: Conceptual ProblemsDocument88 pagesSuperposition and Standing Waves: Conceptual ProblemsnallilathaNo ratings yet
- Acoustic PhoneticsDocument19 pagesAcoustic PhoneticsRihane El Alaoui100% (1)
- Lecture 1-7: Source-Filter ModelDocument6 pagesLecture 1-7: Source-Filter ModelhadaspeeryNo ratings yet
- VowelsDocument110 pagesVowelsamirNo ratings yet
- PHYSICS 1030L Laboratory Measuring The S PDFDocument10 pagesPHYSICS 1030L Laboratory Measuring The S PDFJuan Correa RNo ratings yet
- Clarinet AcousticsDocument8 pagesClarinet AcousticsalexzandrousNo ratings yet
- 2234 1 PDFDocument11 pages2234 1 PDFAlejandra MoraNo ratings yet
- Notes WK 1 1Document12 pagesNotes WK 1 1HarshalNo ratings yet
- Acoustic Monopoles Dipoles QuadrupolesDocument5 pagesAcoustic Monopoles Dipoles QuadrupolesidownloadbooksforstuNo ratings yet
- The Physics of MusicDocument12 pagesThe Physics of Musicgdarrko100% (1)
- Resonance StrategiesDocument11 pagesResonance Strategiesdeyse canvaNo ratings yet
- Sound: Physical PropertiesDocument36 pagesSound: Physical Propertiesvalerio.garibayNo ratings yet
- Head Joint Embouchure Hole and Filtering PDFDocument4 pagesHead Joint Embouchure Hole and Filtering PDFericdanoNo ratings yet
- Nolinear Source Filter / Fuente Filtro No LinealDocument17 pagesNolinear Source Filter / Fuente Filtro No LinealHugo RomeroNo ratings yet
- Acoustic Phonetics - The Handbook of Phonetic Sciences - Blackwell Reference OnlineDocument32 pagesAcoustic Phonetics - The Handbook of Phonetic Sciences - Blackwell Reference OnlineMădălina Lungu100% (1)
- Head Joint Embouchure Hole and Filtering Effects oDocument5 pagesHead Joint Embouchure Hole and Filtering Effects oadrianoucamNo ratings yet
- Acoustic Monopoles Dipoles and Quadrupoles An ExpeDocument6 pagesAcoustic Monopoles Dipoles and Quadrupoles An ExpeDokumentasi FPA XVINo ratings yet
- Trombone Lipping ArticleDocument12 pagesTrombone Lipping ArticleAlec BeattieNo ratings yet
- Fluids: Fluids in Music: The Mathematics of Pan's FlutesDocument6 pagesFluids: Fluids in Music: The Mathematics of Pan's FlutesIsabella RodriguezNo ratings yet
- Investigation of The Effect of Obstacle Placed Near The Human Glottis On The Resultant Sound PressureDocument8 pagesInvestigation of The Effect of Obstacle Placed Near The Human Glottis On The Resultant Sound PressureDarrenNo ratings yet
- Acoustic Theory of Speech ProductionDocument57 pagesAcoustic Theory of Speech ProductionMiza MariyamNo ratings yet
- The Mathematics of Musical InstrumentsDocument11 pagesThe Mathematics of Musical InstrumentsadamrouNo ratings yet
- Physics of Wind Chimes-KimBDocument20 pagesPhysics of Wind Chimes-KimBatiggy05No ratings yet
- Yasui 2015Document12 pagesYasui 2015Artz Joe'sNo ratings yet
- Acoustic Interactions of The Voice Source With The Lower Vocal Tract TITZE STORY 1997Document10 pagesAcoustic Interactions of The Voice Source With The Lower Vocal Tract TITZE STORY 1997Aude JihelNo ratings yet
- 3.4 The Source-Filter Model of Speech Production: Figure 2.31: Saggital Cross Section of The Vocal TractDocument4 pages3.4 The Source-Filter Model of Speech Production: Figure 2.31: Saggital Cross Section of The Vocal TractMirjana NenadovicNo ratings yet
- Schroeder Quadratic Residue DiffusorsDocument6 pagesSchroeder Quadratic Residue DiffusorsadwausNo ratings yet
- Sound Reproduction Systems Using Variable-Directivity LoudspeakersDocument11 pagesSound Reproduction Systems Using Variable-Directivity LoudspeakersAbelardo AlvarezNo ratings yet
- Speech Coding With Wavelet Packet Excitation Signal CompressionDocument8 pagesSpeech Coding With Wavelet Packet Excitation Signal CompressionptknNo ratings yet
- Acoustics of Cross Fingerings in The Shakuhachi: September 2014Document7 pagesAcoustics of Cross Fingerings in The Shakuhachi: September 2014Luiz RobertoNo ratings yet
- Influence of The Neck Shape For Helmholtz Resonators. Mercier Et AlDocument13 pagesInfluence of The Neck Shape For Helmholtz Resonators. Mercier Et AlkarelNo ratings yet
- Human Voice Polar Patterns Opea Singer and SpeakersDocument14 pagesHuman Voice Polar Patterns Opea Singer and SpeakersFederico Nahuel CacavelosNo ratings yet
- Play Guitar: Exploration and Analysis of Harmonic PossibilitiesFrom EverandPlay Guitar: Exploration and Analysis of Harmonic PossibilitiesNo ratings yet
- Engineering Management 2 C Assignment QuestionsDocument3 pagesEngineering Management 2 C Assignment Questionsabhinav kumarNo ratings yet
- 2 3 DNSDocument14 pages2 3 DNSabhinav kumarNo ratings yet
- EM AssignmentDocument27 pagesEM Assignmentabhinav kumarNo ratings yet
- Assignment 2 DIP 2019Document9 pagesAssignment 2 DIP 2019abhinav kumarNo ratings yet
- UE16EC451DDocument3 pagesUE16EC451Dabhinav kumarNo ratings yet
- Engineering Management Assignment 2 (UE16EC451D) : NAME: Abhinav Kumar Class: 8th Sem Sec.: A USN/SRN: 01FB16EEC007Document55 pagesEngineering Management Assignment 2 (UE16EC451D) : NAME: Abhinav Kumar Class: 8th Sem Sec.: A USN/SRN: 01FB16EEC007abhinav kumarNo ratings yet
- CODE ArduinoDocument11 pagesCODE Arduinoabhinav kumarNo ratings yet
- Project Submissions - InstructionsDocument3 pagesProject Submissions - Instructionsabhinav kumarNo ratings yet
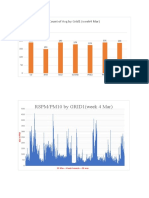
- RSPM/PM10 by GRID1 (Week 4 Mar)Document14 pagesRSPM/PM10 by GRID1 (Week 4 Mar)abhinav kumarNo ratings yet
- MQ 4Document2 pagesMQ 4api-3850017100% (1)
- AbhinavDocument48 pagesAbhinavabhinav kumarNo ratings yet
- Lec - 3-4 Speech ProceesingDocument48 pagesLec - 3-4 Speech Proceesingabhinav kumarNo ratings yet
- Speech Processing: at Least TWO Questions From Each PartDocument1 pageSpeech Processing: at Least TWO Questions From Each Partabhinav kumarNo ratings yet
- Lec - 1-2 Speech ProcessingDocument21 pagesLec - 1-2 Speech Processingabhinav kumarNo ratings yet
- Logic DesignDocument80 pagesLogic Designabhinav kumarNo ratings yet
- Kijrary: Speech ProcessingDocument1 pageKijrary: Speech Processingabhinav kumarNo ratings yet
- Engineering Mechanics 316 Laboratory 109 Earth-Engineering Sciences Building Semester: Fall Year 2017Document6 pagesEngineering Mechanics 316 Laboratory 109 Earth-Engineering Sciences Building Semester: Fall Year 2017Logan SchulerNo ratings yet
- Doubling Time and Half LifeDocument2 pagesDoubling Time and Half Lifedrissdragon7100% (1)
- Enthalpimetric TitulationDocument3 pagesEnthalpimetric TitulationAlessandra Stangherlin OliveiraNo ratings yet
- Mobrey Vertical Magnetic Level SwitchDocument24 pagesMobrey Vertical Magnetic Level SwitchVishnu Viswanadan VNo ratings yet
- Scanner Cobra en 201507Document2 pagesScanner Cobra en 201507Shahbaz KhanNo ratings yet
- Chapter No 3 GASES TEXTBOOK EXERCISEDocument21 pagesChapter No 3 GASES TEXTBOOK EXERCISErehmanNo ratings yet
- Crowd Synchrony On The Millennium Bridge: Nature December 2005Document3 pagesCrowd Synchrony On The Millennium Bridge: Nature December 2005Tito MudanyeNo ratings yet
- ∫…Δi… M……b˜M…‰ §……§…… +®…Æ˙…¥…i…" ¥…t… (…"'ˆ: ¥…Y……x… ¥…t…∂……J……Document17 pages∫…Δi… M……b˜M…‰ §……§…… +®…Æ˙…¥…i…" ¥…t… (…"'ˆ: ¥…Y……x… ¥…t…∂……J……YocobSamandrewsNo ratings yet
- GPH 201Document158 pagesGPH 201ضوسرNo ratings yet
- The Quantum RobinDocument3 pagesThe Quantum RobinpresuraNo ratings yet
- Latitude and Longitude:: Finding Locations On Planet EarthDocument21 pagesLatitude and Longitude:: Finding Locations On Planet EarthAmazing Top HDNo ratings yet
- PV Elite Webinar 001Document23 pagesPV Elite Webinar 001MEC_GuiNo ratings yet
- Spreadsheets To BS 8110: Single Column BaseDocument25 pagesSpreadsheets To BS 8110: Single Column BaseIr Ahmad AfiqNo ratings yet
- 1Document9 pages1Andre YunusNo ratings yet
- Ek Thesis 2003 05 12 Final 2Document121 pagesEk Thesis 2003 05 12 Final 2tomdelfoNo ratings yet
- MatrixDocument3 pagesMatrixeminasalNo ratings yet
- 4 Bending of PlatesDocument16 pages4 Bending of PlatessudarshanNo ratings yet
- Hardtop F15Document4 pagesHardtop F15Biju_PottayilNo ratings yet
- Thermodynamics & Heat Engines: Basic ConceptsDocument28 pagesThermodynamics & Heat Engines: Basic ConceptsTHEOPHILUS ATO FLETCHERNo ratings yet
- 06 Instrument Transformer#Document6 pages06 Instrument Transformer#aimizaNo ratings yet
- Fulltext01 Matlab Code For Elasticity y Plasticity PDFDocument115 pagesFulltext01 Matlab Code For Elasticity y Plasticity PDFRory Cristian Cordero RojoNo ratings yet
- Atomic Energy Will Have Been Made Available To A Single Source by Iris Pear, PHDDocument1 pageAtomic Energy Will Have Been Made Available To A Single Source by Iris Pear, PHDChristoph BartneckNo ratings yet
- Alex Wouden SlidesDocument41 pagesAlex Wouden Slidesnjsmith5No ratings yet
- Robert D. Blevins - Flow-Induced Vibration (2001, Krieger Pub Co) PDFDocument254 pagesRobert D. Blevins - Flow-Induced Vibration (2001, Krieger Pub Co) PDFDang Dinh DongNo ratings yet
- Lecture 04 Atomic ArrangementsDocument22 pagesLecture 04 Atomic Arrangementsantoine demeireNo ratings yet
- Trapezoidal RuleDocument4 pagesTrapezoidal Ruleapi-150547803No ratings yet
- Five Types of Same Level FallsDocument1 pageFive Types of Same Level FallsNORMAN ANDRE LOPEZ BECERRANo ratings yet
- Masel Catalog - Lab SuppliesDocument18 pagesMasel Catalog - Lab SuppliesOrtho OrganizersNo ratings yet
- Division First Periodical Test Math IVDocument6 pagesDivision First Periodical Test Math IVMyra Ramirez RamosNo ratings yet
- ME 8391 Engineering Thermodynamics Workbook - UNIT 1Document154 pagesME 8391 Engineering Thermodynamics Workbook - UNIT 1BIBIN CHIDAMBARANATHANNo ratings yet