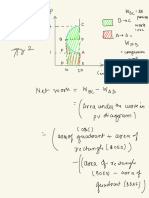
You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5807)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (346)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Business Statistics 1st Edition Donnelly Test Bank 1Document44 pagesBusiness Statistics 1st Edition Donnelly Test Bank 1steven100% (36)
- Psychological AssessmentDocument3 pagesPsychological AssessmentCnfsr Kayce100% (10)
- Dairy Technology 9002 01 07 2008 GBDocument110 pagesDairy Technology 9002 01 07 2008 GBThaVinci100% (1)
- Statistics and Probability: Normal DistributionDocument44 pagesStatistics and Probability: Normal DistributionMhecy Sagandilan100% (1)
- Quarter 4 - Week 1 & 2: Length of Confidence Interval and Appropriate Sample SizeDocument9 pagesQuarter 4 - Week 1 & 2: Length of Confidence Interval and Appropriate Sample SizeJennifer MagangoNo ratings yet
- Astm E2587 - 16 PDFDocument29 pagesAstm E2587 - 16 PDFRavichandran DNo ratings yet
- Optics 2Document3 pagesOptics 2Navneet VermaNo ratings yet
- Prism FormulaDocument2 pagesPrism FormulaNavneet VermaNo ratings yet
- Sol PG 1Document1 pageSol PG 1Navneet VermaNo ratings yet
- Ele Sol pg1Document1 pageEle Sol pg1Navneet VermaNo ratings yet
- AMDocument3 pagesAMNavneet VermaNo ratings yet
- Heat Conduction Through Spherical ConductorDocument2 pagesHeat Conduction Through Spherical ConductorNavneet VermaNo ratings yet
- TRQ-QQ % SBML Yk TL: 3. 31# Aimte) 1 11'Document2 pagesTRQ-QQ % SBML Yk TL: 3. 31# Aimte) 1 11'Navneet VermaNo ratings yet
- MPPSC 2018 Mains Paper5Document8 pagesMPPSC 2018 Mains Paper5Navneet VermaNo ratings yet
- Course 11.pdfind. EnggDocument5 pagesCourse 11.pdfind. EnggNavneet VermaNo ratings yet
- Cam DesignDocument2 pagesCam DesignNavneet VermaNo ratings yet
- Life in The Indian Foreign ServiceDocument4 pagesLife in The Indian Foreign ServiceNavneet VermaNo ratings yet
- Mechanical MeasurementsDocument41 pagesMechanical MeasurementscaptainhassNo ratings yet
- Additional Mathematics F5 Probability DistributionDocument9 pagesAdditional Mathematics F5 Probability DistributionFazlina MustafaNo ratings yet
- Practice Problems For Test 2Document7 pagesPractice Problems For Test 2Islam Abd AlazizNo ratings yet
- CHAPTER III Sampling and Sampling DistributionDocument51 pagesCHAPTER III Sampling and Sampling DistributionMaricris Jagto-calixtoNo ratings yet
- Food For Thought - What You Eat Depends On Your Sex and Eating CompanionsDocument4 pagesFood For Thought - What You Eat Depends On Your Sex and Eating Companionsjworkin0% (1)
- Borehole Surveying PDFDocument129 pagesBorehole Surveying PDFmanikandanNo ratings yet
- Assignment-2: Name: Ahamad Ashique Mozumder ID: 1821474030 Section: 25Document13 pagesAssignment-2: Name: Ahamad Ashique Mozumder ID: 1821474030 Section: 25Salman ShahriarNo ratings yet
- LM9 Stat&probab TasksDocument2 pagesLM9 Stat&probab TaskskhlneNo ratings yet
- Chapter 5: Sampling Distributions & Hypothesis TestingDocument19 pagesChapter 5: Sampling Distributions & Hypothesis TestingAbhishek KushwahaNo ratings yet
- Ch5. Audit Sampling For Tests of Details of BalancesDocument43 pagesCh5. Audit Sampling For Tests of Details of BalancesAli Albaqshi100% (1)
- SPSS Base 10.0 For WindowsDocument6 pagesSPSS Base 10.0 For WindowsKato StratocasterNo ratings yet
- Quality: Prof. Christian TerwieschDocument43 pagesQuality: Prof. Christian TerwieschSabila SanjraniNo ratings yet
- Unit 2Document17 pagesUnit 2Rahul SharmaNo ratings yet
- Reduction of Turnaround Time of In-Patients in A Private Hospital, Chennai A Six Sigma ApproachDocument19 pagesReduction of Turnaround Time of In-Patients in A Private Hospital, Chennai A Six Sigma ApproachchouguleNo ratings yet
- Business Statistics in Practice 8th Edition Bowerman Solutions Manual 1Document26 pagesBusiness Statistics in Practice 8th Edition Bowerman Solutions Manual 1raymond100% (39)
- MATH 7 3RD Alternative Test q4Document2 pagesMATH 7 3RD Alternative Test q4DI AN NENo ratings yet
- Revisiting A 90-Year-Old Debate: The Advantages of The Mean DeviationDocument14 pagesRevisiting A 90-Year-Old Debate: The Advantages of The Mean DeviationlacisagNo ratings yet
- PertDocument25 pagesPertalbatroos earlybirdNo ratings yet
- Eye State Detection Using Image Processing TechniqueDocument6 pagesEye State Detection Using Image Processing TechniqueAJER JOURNALNo ratings yet
- Assignment 5 Probability DistributionDocument1 pageAssignment 5 Probability DistributionSiya SunilNo ratings yet
- CH 3 Statistical EstimationDocument13 pagesCH 3 Statistical EstimationManchilot Tilahun100% (1)
- Measurement Uncertainty DMM Cal Presentation - Slides PDFDocument76 pagesMeasurement Uncertainty DMM Cal Presentation - Slides PDFBogdan IlieNo ratings yet
- Essentials of Business Statistics Communicating With Numbers 1st Edition Jaggia Test Bank DownloadDocument112 pagesEssentials of Business Statistics Communicating With Numbers 1st Edition Jaggia Test Bank DownloadcarrielivingstonocifrtkgnyNo ratings yet
- Lab 1Document15 pagesLab 1Vic SeungNo ratings yet
- 3 Portfolio TheoryDocument23 pages3 Portfolio TheoryESTHERNo ratings yet