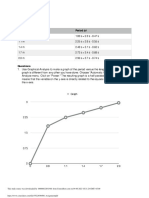
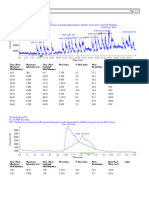
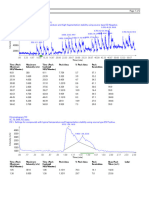
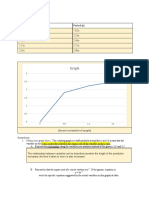
You might also like
- IIBCC 2022 - Cellulose Refining For Fibre Cement Part 2 Length Reduction and Other Effects of RefiningDocument15 pagesIIBCC 2022 - Cellulose Refining For Fibre Cement Part 2 Length Reduction and Other Effects of RefiningjuaanxpoonceNo ratings yet
- Exercise 3: Quantitative DateDocument7 pagesExercise 3: Quantitative Dateanne ropNo ratings yet
- The Lost Art of Nomography Ron DoerflerDocument38 pagesThe Lost Art of Nomography Ron DoerflerRaymond Carlson100% (1)
- MDM4U - Handling Data Activities-Notes and SolutionsDocument2 pagesMDM4U - Handling Data Activities-Notes and SolutionsRawle WayneNo ratings yet
- Turtle Geometry The Computer As A Medium For ExploDocument56 pagesTurtle Geometry The Computer As A Medium For ExploclasesistemasgcaNo ratings yet
- New Resistivity-Logging Tool Helps Resolve Problems of Anisotropy, Shoulder-Bed EffectsDocument3 pagesNew Resistivity-Logging Tool Helps Resolve Problems of Anisotropy, Shoulder-Bed EffectsAmr HegazyNo ratings yet
- PNG University of Technology Mathematics & Computer Science DepartmentDocument15 pagesPNG University of Technology Mathematics & Computer Science DepartmentGeckoNo ratings yet
- Contour Lines - Intro - ToomeyDocument16 pagesContour Lines - Intro - ToomeyLooser PakerNo ratings yet
- This Study Resource WasDocument6 pagesThis Study Resource WasKimberly Claire AtienzaNo ratings yet
- Peculiarities of Morphometric Changes in Rat's Lungs WithinDocument1 pagePeculiarities of Morphometric Changes in Rat's Lungs WithinТеслик Тетяна ПетрівнаNo ratings yet
- 6.01 Assignment PDFDocument2 pages6.01 Assignment PDFjackson combassNo ratings yet
- Chapter9 EXDocument5 pagesChapter9 EXMohammad TammamNo ratings yet
- 1-E-08-26 SM Sivasankaran ADocument10 pages1-E-08-26 SM Sivasankaran AAnirudh RamkumarNo ratings yet
- SLG 6.6.3 Analysis and Interpretation of DataDocument11 pagesSLG 6.6.3 Analysis and Interpretation of DataAllan DizonNo ratings yet
- Water/Oil Emulsions With Controlled Droplet Sizes For In-Vitro Selection ExperimentsDocument4 pagesWater/Oil Emulsions With Controlled Droplet Sizes For In-Vitro Selection ExperimentsWorapol YingyuenNo ratings yet
- Chapter 2 VISUAL PRESENTATION OF DATADocument14 pagesChapter 2 VISUAL PRESENTATION OF DATAIsraelNo ratings yet
- Technological Institute of The PhilippinesDocument6 pagesTechnological Institute of The Philippinesmoona LoaNo ratings yet
- Regular Diet: Men WomenDocument6 pagesRegular Diet: Men WomenCZARINA JANE ACHUMBRE PACTURANNo ratings yet
- Regular Diet: Men WomenDocument6 pagesRegular Diet: Men WomenCZARINA JANE ACHUMBRE PACTURANNo ratings yet
- SC T5 SMX FC5Document3 pagesSC T5 SMX FC5Sebastián Alberto Campos MillaNo ratings yet
- Vibrations SsDocument14 pagesVibrations SsOmar HaibaNo ratings yet
- Chapter 9Document15 pagesChapter 9Fanny Sylvia C.No ratings yet
- Tonmoy Kumar Saha - WSUV ID 011578904: L WT RDocument9 pagesTonmoy Kumar Saha - WSUV ID 011578904: L WT RRiheen AhsanNo ratings yet
- LAMPIRANDocument39 pagesLAMPIRANip037530No ratings yet
- Frequency Bar Chart: Semester Frequency Relative Frequency Relative Frequency (Method)Document4 pagesFrequency Bar Chart: Semester Frequency Relative Frequency Relative Frequency (Method)vinoedhnaidu_rajagopalNo ratings yet
- SC T0 SMX FC5Document2 pagesSC T0 SMX FC5Sebastián Alberto Campos MillaNo ratings yet
- Distribution Models Transcript (With Images)Document7 pagesDistribution Models Transcript (With Images)Peter HuangNo ratings yet
- Measurements For The Beer Foam Experiment: Download The Video HereDocument2 pagesMeasurements For The Beer Foam Experiment: Download The Video HereSheryl OsorioNo ratings yet
- CorrelationDocument9 pagesCorrelationTahmidur FahimNo ratings yet
- Nama: Matriapsi Yoel Talan Nim: 20180303036 Tugas Pertemuan 13 BiostatistikDocument14 pagesNama: Matriapsi Yoel Talan Nim: 20180303036 Tugas Pertemuan 13 Biostatistikyan kify mohiNo ratings yet
- Snell's Law: A Lesson From The LaboratoryDocument3 pagesSnell's Law: A Lesson From The LaboratoryLeon MathaiosNo ratings yet
- Weibull Ortega GurumendiDocument8 pagesWeibull Ortega GurumendiYaritza maribel ortega anzulesNo ratings yet
- Ib1 Lab Sow Part One 2021-2022Document6 pagesIb1 Lab Sow Part One 2021-2022Rahil JadhaniNo ratings yet
- Anexo 3Document8 pagesAnexo 3Lendy Parra100% (1)
- Seismic Refraction LabDocument8 pagesSeismic Refraction Labmemo alfaisal100% (1)
- Data Analysis and Calculations: Mlss G L MG LDocument12 pagesData Analysis and Calculations: Mlss G L MG LcenbanaNo ratings yet
- Krebs M., Shaheen A. Expander Families and Cayley Graphs. A Beginner's GuideDocument283 pagesKrebs M., Shaheen A. Expander Families and Cayley Graphs. A Beginner's GuideIustin Surubaru100% (1)
- The 7 QC Tools - English (19 Pages)Document19 pagesThe 7 QC Tools - English (19 Pages)Subodh RanjanNo ratings yet
- Am 2540: Strength of Materials Laboratory: 2. Measurement of Bending Stress Using Strain GaugeDocument4 pagesAm 2540: Strength of Materials Laboratory: 2. Measurement of Bending Stress Using Strain GaugeAditya KoutharapuNo ratings yet
- Unit Operations of Chemical Engineering - 1581788Document20 pagesUnit Operations of Chemical Engineering - 1581788aleen8483No ratings yet
- Understanding Basic Statistics International Metric Edition 7th Edition Brase Solutions ManualDocument36 pagesUnderstanding Basic Statistics International Metric Edition 7th Edition Brase Solutions Manualleesharpjkoyte100% (23)
- 6.01 Pendulum Lab TemplateDocument3 pages6.01 Pendulum Lab Templatejackson combassNo ratings yet
- BAI 4 ResultDocument2 pagesBAI 4 ResultLê Nguyễn Hoàng NhiNo ratings yet
- Automatic Facial Landmark Tracking in Video SequenDocument15 pagesAutomatic Facial Landmark Tracking in Video Sequenkhanhdu1609No ratings yet
- Chapter 1Document24 pagesChapter 1Pei PeiNo ratings yet
- AEC 51 Quiz 2 Xavier-Ateneo Mathematics Department Nov 8,2021 Name: Czarina Jane A. PacturanDocument2 pagesAEC 51 Quiz 2 Xavier-Ateneo Mathematics Department Nov 8,2021 Name: Czarina Jane A. PacturanCZARINA JANE ACHUMBRE PACTURANNo ratings yet
- 4th Periodical Exam PROSTAT (Grade 11)Document274 pages4th Periodical Exam PROSTAT (Grade 11)Kejiah Grace LaborteNo ratings yet
- SD ch-4Document14 pagesSD ch-4Estrategia FocalizadaNo ratings yet
- Pendulum Experiment (Fiver Work)Document3 pagesPendulum Experiment (Fiver Work)Shayan FarrukhNo ratings yet
- Pendulum Experiment: Trial Length of String (Centimeters) Time (Seconds)Document3 pagesPendulum Experiment: Trial Length of String (Centimeters) Time (Seconds)Shayan FarrukhNo ratings yet
- Residuals in The Extended Growth Curve ModelDocument18 pagesResiduals in The Extended Growth Curve ModelRaúl AponteNo ratings yet
- Particle Size Distribution ReportDocument6 pagesParticle Size Distribution ReportPeter KamauNo ratings yet
- 7.06 Radioactivity Dating LabDocument2 pages7.06 Radioactivity Dating Labjackson combassNo ratings yet
- Assg1 200501Document7 pagesAssg1 200501SHARIFAH NURIN ZAHIRAH BINTI SYED ZAINAL ABIDINNo ratings yet
- Dwnload Full Understanding Basic Statistics Enhanced 7th Edition Brase Solutions Manual PDFDocument36 pagesDwnload Full Understanding Basic Statistics Enhanced 7th Edition Brase Solutions Manual PDFpondoptionv5100% (8)
- OUTPUTDocument5 pagesOUTPUTAysahhNo ratings yet
- M) Is Revealed in The Diffraction Pat-: 366 Figure 15.2. Single-Crystal (A-C) Diffraction Patterns (Right)Document8 pagesM) Is Revealed in The Diffraction Pat-: 366 Figure 15.2. Single-Crystal (A-C) Diffraction Patterns (Right)assefaNo ratings yet
- M) Is Revealed in The Diffraction Pat-: 366 Figure 15.2. Single-Crystal (A-C) Diffraction Patterns (Right)Document8 pagesM) Is Revealed in The Diffraction Pat-: 366 Figure 15.2. Single-Crystal (A-C) Diffraction Patterns (Right)assefaNo ratings yet
- Physics Project-1Document21 pagesPhysics Project-1Yashwanth RameshNo ratings yet
- 2 Correlation and Linear Regression PDFDocument26 pages2 Correlation and Linear Regression PDFwhmimbsNo ratings yet
- Biochemical Plan Production InformationDocument1 pageBiochemical Plan Production InformationWillian MexNo ratings yet
- 1 Factorial Experiments PDFDocument35 pages1 Factorial Experiments PDFwhmimbsNo ratings yet
- Lab 3Document2 pagesLab 3whmimbsNo ratings yet
- " Hysil " Calcium Silicate Insulation Blocks & Pipes-SpecificationsDocument1 page" Hysil " Calcium Silicate Insulation Blocks & Pipes-SpecificationsJCSNo ratings yet
- CH 12 ISC Class 11 CommerceDocument2 pagesCH 12 ISC Class 11 Commercekrish sharmaNo ratings yet
- 50 Q&A Zinc Sulfate Tablets - Nov2016 PDFDocument5 pages50 Q&A Zinc Sulfate Tablets - Nov2016 PDFSunil Murkikar (GM - PMI Quality Operations)No ratings yet
- Anthropology and The Changing WorldDocument12 pagesAnthropology and The Changing Worldbilal1710No ratings yet
- Vedic Maths Edited 2Document9 pagesVedic Maths Edited 2sriram ANo ratings yet
- Spectrum-NET Overview Oct 2 No NDADocument12 pagesSpectrum-NET Overview Oct 2 No NDAuxun100% (1)
- DUNE IMPERIUM Rules - 2020 - 10 - 26Document20 pagesDUNE IMPERIUM Rules - 2020 - 10 - 26Zoltan A. FeketeNo ratings yet
- Pajarillo, Villanada&Ruedas - Food SafetyDocument13 pagesPajarillo, Villanada&Ruedas - Food SafetyMary Yole Apple DeclaroNo ratings yet
- Lecture 1Document30 pagesLecture 1J CNo ratings yet
- Lesson 6 Geometric SequenceDocument10 pagesLesson 6 Geometric SequenceTuesday WednesdayNo ratings yet
- Unit Ii Lesson3 - 4 - The Global Interstate SystemDocument15 pagesUnit Ii Lesson3 - 4 - The Global Interstate SystemIvy Lorenze Calingasan CortezNo ratings yet
- Strength Based Student ProfileDocument1 pageStrength Based Student Profileapi-544895801No ratings yet
- Prototype of Cansat With Auto-Gyro Payload For Small Satellite EducationDocument7 pagesPrototype of Cansat With Auto-Gyro Payload For Small Satellite EducationPusapati Saketh Varma ed21b048No ratings yet
- Enrichment material for the 12th grade -استردادDocument13 pagesEnrichment material for the 12th grade -استردادnananaimNo ratings yet
- Page 2 Positive Psychology Page 3 Jan D. Sinnott Editor Positive Psychology Advances in ...Document358 pagesPage 2 Positive Psychology Page 3 Jan D. Sinnott Editor Positive Psychology Advances in ...Javed67% (3)
- Biology Lab ReportDocument13 pagesBiology Lab Reportapi-390838152No ratings yet
- Plate Tectonics Gizmo Form PDFDocument5 pagesPlate Tectonics Gizmo Form PDFJorge Cota85% (13)
- Physical Science 22.1 Colors and LightDocument19 pagesPhysical Science 22.1 Colors and LightChristine Grace B. AquinoNo ratings yet
- GURPS Magick: Voodoo-Style Magic For The Middle AgesDocument23 pagesGURPS Magick: Voodoo-Style Magic For The Middle Agesmmonaco100% (1)
- Allen Leader Unit Test 5 (17 September) QuestionDocument48 pagesAllen Leader Unit Test 5 (17 September) Questionprakashsinghsatya448No ratings yet
- 7 Gastroenteritis Nursing Care Plans - NurseslabsDocument8 pages7 Gastroenteritis Nursing Care Plans - NurseslabsHikaru Takishima91% (23)
- Registered Aquaculture FarmDocument10 pagesRegistered Aquaculture FarmLee AydenNo ratings yet
- Pazzaglia 2013Document34 pagesPazzaglia 2013João Carlos CerqueiraNo ratings yet
- Savage Worlds - Ravaged Earth - Revised Second Edition PDFDocument322 pagesSavage Worlds - Ravaged Earth - Revised Second Edition PDFsoth100% (3)
- DC-40 CrystalDocument4 pagesDC-40 Crystaljavier govantesNo ratings yet
- Contoh RPP Berbahasa Inggris Mapel Bahasa Inggris SMA Kelas 12 Sem 1 Materi ExplanationDocument9 pagesContoh RPP Berbahasa Inggris Mapel Bahasa Inggris SMA Kelas 12 Sem 1 Materi ExplanationOLiph Nya ALpha0% (2)
- Sheet 2 - Solution - EE218Document10 pagesSheet 2 - Solution - EE218NouraNo ratings yet
- StarsWithoutNumberRevised Character Sheet Form FillableDocument2 pagesStarsWithoutNumberRevised Character Sheet Form FillablejemcutterNo ratings yet
- Design and Installation of Plastic Syphonic Roof Drainage SystemsDocument7 pagesDesign and Installation of Plastic Syphonic Roof Drainage SystemsAndresBenitezNo ratings yet
- VersaLink C405 Service ManualDocument858 pagesVersaLink C405 Service ManualAlex Rodriguez BarronNo ratings yet
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Calculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusFrom EverandCalculus Made Easy: Being a Very-Simplest Introduction to Those Beautiful Methods of Reckoning Which are Generally Called by the Terrifying Names of the Differential Calculus and the Integral CalculusRating: 4.5 out of 5 stars4.5/5 (2)
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Math Workshop, Grade K: A Framework for Guided Math and Independent PracticeFrom EverandMath Workshop, Grade K: A Framework for Guided Math and Independent PracticeRating: 5 out of 5 stars5/5 (1)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryFrom EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNo ratings yet
- Geometric Patterns from Patchwork Quilts: And how to draw themFrom EverandGeometric Patterns from Patchwork Quilts: And how to draw themRating: 5 out of 5 stars5/5 (1)
- Classroom-Ready Number Talks for Third, Fourth and Fifth Grade Teachers: 1,000 Interactive Math Activities that Promote Conceptual Understanding and Computational FluencyFrom EverandClassroom-Ready Number Talks for Third, Fourth and Fifth Grade Teachers: 1,000 Interactive Math Activities that Promote Conceptual Understanding and Computational FluencyNo ratings yet
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)