You might also like
- Radial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksFrom EverandRadial Basis Networks: Fundamentals and Applications for The Activation Functions of Artificial Neural NetworksNo ratings yet
- 2018 Interspeech DihardDocument5 pages2018 Interspeech DihardCool NameNo ratings yet
- Feature Analysis and Extraction For Audio Automatic ClassificationDocument6 pagesFeature Analysis and Extraction For Audio Automatic Classificationks09anoopNo ratings yet
- Survey On Speech Imitation Using Machine Learning: Rahul Kumar, Jaybrata Chakraborty and Bappaditya ChakrabortyDocument5 pagesSurvey On Speech Imitation Using Machine Learning: Rahul Kumar, Jaybrata Chakraborty and Bappaditya ChakrabortyBappaditya ChakrabortyNo ratings yet
- Paper - Design and Analysis of FIR Filter Using Artificial Neural Network - 2015Document4 pagesPaper - Design and Analysis of FIR Filter Using Artificial Neural Network - 2015Armando CajahuaringaNo ratings yet
- SPDetect Paper3570Document4 pagesSPDetect Paper3570alo1611No ratings yet
- Dehak Et Al. - Language Recognition Via I-Vectors and DimensionalDocument4 pagesDehak Et Al. - Language Recognition Via I-Vectors and DimensionalNicolas ShuNo ratings yet
- Features of Wavelet Packet Decomposition and Discrete Wavelet Transform For Malayalam Speech RecognitionDocument4 pagesFeatures of Wavelet Packet Decomposition and Discrete Wavelet Transform For Malayalam Speech RecognitionMaher Khalaf HussienNo ratings yet
- Feature Parameter Extraction From Wavelet Sub-Band Analysis For The Recognition of Isolated Malayalam Spoken WordsDocument4 pagesFeature Parameter Extraction From Wavelet Sub-Band Analysis For The Recognition of Isolated Malayalam Spoken Wordsvol1no1No ratings yet
- Classifier Based Text Mining For Radial Basis FunctionDocument6 pagesClassifier Based Text Mining For Radial Basis FunctionEdinilson VidaNo ratings yet
- Pce Based Path Computation Algorithm Selection Framework For The Next Generation SdonDocument13 pagesPce Based Path Computation Algorithm Selection Framework For The Next Generation SdonBrian Smith GarcíaNo ratings yet
- Practical Characteristics of Neural Network and Conventional Pattern ClassifiersDocument10 pagesPractical Characteristics of Neural Network and Conventional Pattern ClassifiersKousalyaNo ratings yet
- A New Approach For Persian Speech RecognitionDocument6 pagesA New Approach For Persian Speech RecognitionSana IsamNo ratings yet
- 11of20 - Model Selection For Ranking SVM Using Regularization PathDocument15 pages11of20 - Model Selection For Ranking SVM Using Regularization PathBranko NikolicNo ratings yet
- Radial Basis Function in Neural Network For Clustering DataDocument8 pagesRadial Basis Function in Neural Network For Clustering DataARVINDNo ratings yet
- Hyperparameter Tuning For Deep Learning in Natural Language ProcessingDocument7 pagesHyperparameter Tuning For Deep Learning in Natural Language ProcessingWardhana Halim KusumaNo ratings yet
- Different Type of Feature Selection For Text ClassificationDocument6 pagesDifferent Type of Feature Selection For Text ClassificationseventhsensegroupNo ratings yet
- K-SVD: An Algorithm For Designing Overcomplete Dictionaries For Sparse RepresentationDocument12 pagesK-SVD: An Algorithm For Designing Overcomplete Dictionaries For Sparse RepresentationSourish SarkarNo ratings yet
- Alwahab 2018Document5 pagesAlwahab 2018Nemilyn Angeles FadcharNo ratings yet
- 2010 - Improving Arabic Text Categorization Using Neural Network With SVDDocument7 pages2010 - Improving Arabic Text Categorization Using Neural Network With SVDrvasiliouNo ratings yet
- On Learning To Identify Genders From Raw Speech Signal Using CnnsDocument5 pagesOn Learning To Identify Genders From Raw Speech Signal Using CnnsharisbinziaNo ratings yet
- Else Vier Neur Da QRDocument7 pagesElse Vier Neur Da QRkhaledNo ratings yet
- Isolated Speech Recognition Using Artificial Neural NetworksDocument5 pagesIsolated Speech Recognition Using Artificial Neural Networksmdkzt7ehkybettcngos3No ratings yet
- Deep Learning for Speech Emotion Recognition Achieves 96.97% AccuracyDocument5 pagesDeep Learning for Speech Emotion Recognition Achieves 96.97% AccuracyHari HaranNo ratings yet
- An Improved TS Algorithm For Loss-Minimum Reconfiguration in Large-Scale Distribution SystemsDocument10 pagesAn Improved TS Algorithm For Loss-Minimum Reconfiguration in Large-Scale Distribution Systemsapi-3697505No ratings yet
- Modeling The Intonation of DiscourseDocument10 pagesModeling The Intonation of DiscourseNelson Sousa Jr.No ratings yet
- Sattelite CommunicationsDocument5 pagesSattelite Communicationskavita gangwarNo ratings yet
- Multilayer Perceptron Architecture OptimizationDocument5 pagesMultilayer Perceptron Architecture OptimizationaliceNo ratings yet
- Multilayer Perceptron PDFDocument5 pagesMultilayer Perceptron PDFAquacypressNo ratings yet
- 2020-Auto-Tuning Spectral Clustering For Speaker Diarization Using Normalized Maximum EigengapDocument5 pages2020-Auto-Tuning Spectral Clustering For Speaker Diarization Using Normalized Maximum EigengapMohammed NabilNo ratings yet
- An Audio Classification Approach Using Feature Extraction Neural Network Classification ApprochDocument6 pagesAn Audio Classification Approach Using Feature Extraction Neural Network Classification Approchks09anoopNo ratings yet
- Data Mining Techniques in Coginitive Radio Network For Smart Home EnvironmentDocument7 pagesData Mining Techniques in Coginitive Radio Network For Smart Home Environmentdr mbaluNo ratings yet
- Mcgarry Tait Werm Ter Macintyre 1999Document6 pagesMcgarry Tait Werm Ter Macintyre 1999ashenafiNo ratings yet
- Automatic Text Summarization Using: Hybrid Fuzzy GA-GPDocument7 pagesAutomatic Text Summarization Using: Hybrid Fuzzy GA-GPSona AgarwalNo ratings yet
- Ar 6Document2 pagesAr 6houda khaterNo ratings yet
- Hop Field 2086Document10 pagesHop Field 2086cliffordNo ratings yet
- Optimal Hyperparameters For Deep LSTM-Networks For Sequence Labeling TasksDocument34 pagesOptimal Hyperparameters For Deep LSTM-Networks For Sequence Labeling TasksWardhana Halim KusumaNo ratings yet
- 2019-BUT System Description For DIHARDDocument5 pages2019-BUT System Description For DIHARDMohammed NabilNo ratings yet
- ssw9 PS2-13 WuDocument6 pagesssw9 PS2-13 Wujavilm500No ratings yet
- Optimal Hyperparameters For Deep LSTM-Networks For Sequence Labeling TasksDocument34 pagesOptimal Hyperparameters For Deep LSTM-Networks For Sequence Labeling TasksWardhana Halim KusumaNo ratings yet
- K-SVD: An Algorithm For Designing Overcomplete Dictionaries For Sparse RepresentationDocument12 pagesK-SVD: An Algorithm For Designing Overcomplete Dictionaries For Sparse RepresentationGalal NadimNo ratings yet
- Front-End Factor Analysis For Speaker VerificationDocument12 pagesFront-End Factor Analysis For Speaker VerificationthyagosmesmeNo ratings yet
- Isolated Word Recognition Using LPC & Vector Quantization: M. K. Linga Murthy, G.L.N. MurthyDocument4 pagesIsolated Word Recognition Using LPC & Vector Quantization: M. K. Linga Murthy, G.L.N. MurthymauricetappaNo ratings yet
- Adaptive Cooperative Fuzzy Logic Controller: Justin Ammerlaan David WrightDocument9 pagesAdaptive Cooperative Fuzzy Logic Controller: Justin Ammerlaan David Wrightmenilanjan89nLNo ratings yet
- Thesis On Speaker Recognition SystemDocument4 pagesThesis On Speaker Recognition Systemafbtegwly100% (1)
- Malaysian Journal of Computer ScienceDocument14 pagesMalaysian Journal of Computer ScienceAadil MuklhtarNo ratings yet
- Voice Analysis Using Short Time Fourier Transform and Cross Correlation MethodsDocument6 pagesVoice Analysis Using Short Time Fourier Transform and Cross Correlation MethodsprasadNo ratings yet
- Classifying audio signals using SVM and neural networksDocument7 pagesClassifying audio signals using SVM and neural networkspurple raNo ratings yet
- Deep Speech - Scaling Up End-To-End Speech RecognitionDocument12 pagesDeep Speech - Scaling Up End-To-End Speech RecognitionSubhankar ChakrabortyNo ratings yet
- Towards Emotion Independent Languageidentification System: by Priyam Jain, Krishna Gurugubelli, Anil Kumar VuppalaDocument6 pagesTowards Emotion Independent Languageidentification System: by Priyam Jain, Krishna Gurugubelli, Anil Kumar VuppalaSamay PatelNo ratings yet
- Application of Microphone Array For Speech Coding in Noisy EnvironmentDocument5 pagesApplication of Microphone Array For Speech Coding in Noisy Environmentscribd1235207No ratings yet
- SeminarskiDocument10 pagesSeminarskiDimitrije Mita PešićNo ratings yet
- Artificial Neural Networks For Solving Ordinary and Partial Differential EquationsDocument14 pagesArtificial Neural Networks For Solving Ordinary and Partial Differential EquationsKeshav BajpaiNo ratings yet
- Bag of Tricks For Text ClassificationDocument5 pagesBag of Tricks For Text ClassificationRahul JainNo ratings yet
- Sequential State-Space Filters For Speech EnhancementDocument4 pagesSequential State-Space Filters For Speech EnhancementMark MoralesNo ratings yet
- Extracting Interpretable Features For Time Series An - 2023 - Expert Systems WitDocument11 pagesExtracting Interpretable Features For Time Series An - 2023 - Expert Systems WitDilip SinghNo ratings yet
- Algorithm For Devanagari CharacterDocument6 pagesAlgorithm For Devanagari CharacterVamsikrishna PanugantiNo ratings yet
- Transformer Neural Network: BY Tharun E 1MS18CS127 Under The Guidance of Ganeshayya ShidagantiDocument17 pagesTransformer Neural Network: BY Tharun E 1MS18CS127 Under The Guidance of Ganeshayya ShidagantiRiddhi SinghalNo ratings yet
- Modeling and I Vector and JFADocument11 pagesModeling and I Vector and JFAVishakha DikshitNo ratings yet
- Fault Detection in Industrial Plant Using - Nearest Neighbors With Random Subspace MethodDocument6 pagesFault Detection in Industrial Plant Using - Nearest Neighbors With Random Subspace MethodsachinNo ratings yet
- Industrial VisitDocument1 pageIndustrial VisitBharath ykNo ratings yet
- Notification 376Document2 pagesNotification 376Bharath ykNo ratings yet
- Environment, Development and Sustainability Volume issue 2020 [doi 10.1007_s10668-019-00583-2] Vendoti, Suresh; Muralidhar, M.; Kiranmayi, R. -- Techno-economic analysis of off-grid solar_wind_biogaDocument22 pagesEnvironment, Development and Sustainability Volume issue 2020 [doi 10.1007_s10668-019-00583-2] Vendoti, Suresh; Muralidhar, M.; Kiranmayi, R. -- Techno-economic analysis of off-grid solar_wind_biogaBharath ykNo ratings yet
- Distance Relay CharacteristicsDocument2 pagesDistance Relay CharacteristicsBharath ykNo ratings yet
- Invitation: The National Institute of EngineeringDocument3 pagesInvitation: The National Institute of EngineeringBharath ykNo ratings yet
- ReimbursementDocument1 pageReimbursementBharath ykNo ratings yet
- Department of Electrical and Electronics EngineeringDocument2 pagesDepartment of Electrical and Electronics EngineeringBharath ykNo ratings yet
- The Department of Electrical and Electronics Engineering: NIE IEEE Power and Energy Society Student Branch ChapterDocument1 pageThe Department of Electrical and Electronics Engineering: NIE IEEE Power and Energy Society Student Branch ChapterBharath ykNo ratings yet
- TEQIP-III Visit DataDocument4 pagesTEQIP-III Visit DataBharath ykNo ratings yet
- Wavelet Neural Networks for Dynamical SystemsDocument90 pagesWavelet Neural Networks for Dynamical SystemsReza GhanavatiNo ratings yet
- TEQIP-III Visit DataDocument4 pagesTEQIP-III Visit DataBharath ykNo ratings yet
- REC BandaDocument2 pagesREC BandaBharath ykNo ratings yet
- A Fast and Accurate Online Sequential Learning Algorithm For Feedforward NetworksDocument14 pagesA Fast and Accurate Online Sequential Learning Algorithm For Feedforward NetworksBharath ykNo ratings yet
- Power Quality Signal Classification Using Convolutional Neural NetworkDocument10 pagesPower Quality Signal Classification Using Convolutional Neural NetworkBharath ykNo ratings yet
- Wind ANNDocument33 pagesWind ANNBharath ykNo ratings yet
- Short-Term Wind Speed Forecasting by An Adaptive Network-Based Fuzzy Inference System (ANFIS) : An Attempt Towards An..Document11 pagesShort-Term Wind Speed Forecasting by An Adaptive Network-Based Fuzzy Inference System (ANFIS) : An Attempt Towards An..Bharath ykNo ratings yet
- Induction Generator Control Using ANFISDocument9 pagesInduction Generator Control Using ANFISBharath ykNo ratings yet
- Fuzzy DefDocument8 pagesFuzzy DefBharath ykNo ratings yet
- Machine Learning Based Sample Extraction For Automatic Speech Recognition Using Dialectal Assamese Speech Speech..Document16 pagesMachine Learning Based Sample Extraction For Automatic Speech Recognition Using Dialectal Assamese Speech Speech..Bharath ykNo ratings yet
- Introduction To Radial Basis Neural NetworksDocument7 pagesIntroduction To Radial Basis Neural NetworksBadari Narayan PNo ratings yet
- Choosing Basis Functions and Shape Parameters For Radial Basis Function MethodsDocument20 pagesChoosing Basis Functions and Shape Parameters For Radial Basis Function MethodsBharath ykNo ratings yet
- Medium-Term Electrical Load Forecasting of Konya Region Using ANFIS, Regression Model and ANNDocument6 pagesMedium-Term Electrical Load Forecasting of Konya Region Using ANFIS, Regression Model and ANNBharath ykNo ratings yet
- Test Admission Ticket (TAT) Je (Electrical)Document2 pagesTest Admission Ticket (TAT) Je (Electrical)Bharath ykNo ratings yet
- Analysis of Minimal Radial Basis Function Network Algorithm For Real-Time Identification of Nonlinear Dynamic SystemsDocument22 pagesAnalysis of Minimal Radial Basis Function Network Algorithm For Real-Time Identification of Nonlinear Dynamic SystemsBharath ykNo ratings yet
- Fault Diagnosis of Power Distribution System Using Interval Type-2 Fuzzy Data MiningDocument13 pagesFault Diagnosis of Power Distribution System Using Interval Type-2 Fuzzy Data MiningBharath ykNo ratings yet
- Hydrologic Applications of MRAN AlgorithmDocument7 pagesHydrologic Applications of MRAN AlgorithmBharath ykNo ratings yet
- Development of Fuzzy Type-2 Reliability Models For Power System Reliability Evaluation Problems and Preventive Maintenance SuggestionsDocument12 pagesDevelopment of Fuzzy Type-2 Reliability Models For Power System Reliability Evaluation Problems and Preventive Maintenance SuggestionsBharath ykNo ratings yet
- Research Article: Type-2 Fuzzy Logic Controller of A Doubly Fed Induction MachineDocument11 pagesResearch Article: Type-2 Fuzzy Logic Controller of A Doubly Fed Induction MachineBharath ykNo ratings yet
- Bharath123 4Document1 pageBharath123 4Bharath ykNo ratings yet
- Bloock Diagram Reduction SummaryDocument10 pagesBloock Diagram Reduction SummaryLakshay KhichiNo ratings yet
- Critical Book Review Seminar on ELTDocument4 pagesCritical Book Review Seminar on ELTLiza GunawanNo ratings yet
- Question Bank Topic 1 Economic Thinking and Choice in A World of ScarcityDocument19 pagesQuestion Bank Topic 1 Economic Thinking and Choice in A World of ScarcityHide Yasu NakajimaNo ratings yet
- SAP & ERP Introduction: Centralized ApplicationsDocument6 pagesSAP & ERP Introduction: Centralized ApplicationsMesumNo ratings yet
- Understanding the Interdisciplinary Field of Cognitive ScienceDocument10 pagesUnderstanding the Interdisciplinary Field of Cognitive ScienceDoris TănaseNo ratings yet
- Organization Theory and Design Canadian 2Nd Edition Daft Solutions Manual Full Chapter PDFDocument35 pagesOrganization Theory and Design Canadian 2Nd Edition Daft Solutions Manual Full Chapter PDFadeliahuy9m5u97100% (7)
- Gallery of FloraDocument26 pagesGallery of FloraRenezel Joy PatriarcaNo ratings yet
- Grameen Phone SWOT Analysis of Mobile OperatorDocument20 pagesGrameen Phone SWOT Analysis of Mobile Operatorsifat21No ratings yet
- BSBPMG522 assessment tasksDocument30 pagesBSBPMG522 assessment tasksPokemon Legend0% (1)
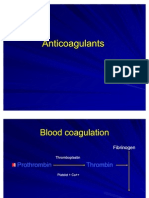
- AnticoagulantsDocument19 pagesAnticoagulantsOsama ZbedaNo ratings yet
- Nursing Care PlanDocument12 pagesNursing Care Planzsazsageorge86% (21)
- Four Theories of the Press - Libertarian vs AuthoritarianDocument8 pagesFour Theories of the Press - Libertarian vs Authoritarianআলটাফ হুছেইনNo ratings yet
- Reaction KineticsDocument37 pagesReaction KineticsDaisyNo ratings yet
- Analyzing Customer Support at eSewa FonepayDocument50 pagesAnalyzing Customer Support at eSewa FonepayGrishma DangolNo ratings yet
- History of Anglo Saxon Literature English Assignment NUML National University of Modern LanguagesDocument15 pagesHistory of Anglo Saxon Literature English Assignment NUML National University of Modern LanguagesMaanNo ratings yet
- Padeye Deign.Document14 pagesPadeye Deign.Bolarinwa100% (3)
- Digital Image Processing: Relationships of PixelDocument49 pagesDigital Image Processing: Relationships of PixelAiNo ratings yet
- G.R. No. 202976 February 19PEOPLE OF THE PHILIPPINES, Plaintiff - Appellee, MERVIN GAHI, Accused-AppellantDocument13 pagesG.R. No. 202976 February 19PEOPLE OF THE PHILIPPINES, Plaintiff - Appellee, MERVIN GAHI, Accused-AppellantjbandNo ratings yet
- Sorting Lesson PlanDocument4 pagesSorting Lesson PlanStasha DuttNo ratings yet
- Review Article: Neurophysiological Effects of Meditation Based On Evoked and Event Related Potential RecordingsDocument12 pagesReview Article: Neurophysiological Effects of Meditation Based On Evoked and Event Related Potential RecordingsSreeraj Guruvayoor SNo ratings yet
- Modeling methanol synthesis from CO2-rich syngasDocument72 pagesModeling methanol synthesis from CO2-rich syngasshanku_biet75% (4)
- Kepler's Celestial MusicDocument24 pagesKepler's Celestial Musicfranciscoacfreitas100% (1)
- Curriculum Vitae: About MyselfDocument5 pagesCurriculum Vitae: About MyselfRahat Singh KachhwahaNo ratings yet
- Sample Reflective SummaryDocument3 pagesSample Reflective SummaryRicksen TamNo ratings yet
- Use of Imagery in Look Back in AngerDocument3 pagesUse of Imagery in Look Back in AngerArindam SenNo ratings yet
- SCA No. 8220-R - Petitioner's MemorandumDocument9 pagesSCA No. 8220-R - Petitioner's MemorandumElizerNo ratings yet
- Understanding Application ReasoningDocument42 pagesUnderstanding Application ReasoningadeNo ratings yet
- Communicating in Teams and OrganizationsDocument6 pagesCommunicating in Teams and Organizationserielle mejicoNo ratings yet
- Case Study Walking The WalkDocument3 pagesCase Study Walking The Walk9899 Mariam Akter Marketing100% (1)
- Flouris-2010-Prediction of VO2maxDocument4 pagesFlouris-2010-Prediction of VO2maxBumbum AtaunNo ratings yet






























































![Environment, Development and Sustainability Volume issue 2020 [doi 10.1007_s10668-019-00583-2] Vendoti, Suresh; Muralidhar, M.; Kiranmayi, R. -- Techno-economic analysis of off-grid solar_wind_bioga](https://imgv2-2-f.scribdassets.com/img/document/504558596/149x198/94ab1df31d/1710543010?v=1)