You might also like
- Modular Forms and Special Cycles on Shimura Curves. (AM-161)From EverandModular Forms and Special Cycles on Shimura Curves. (AM-161)No ratings yet
- Answers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesFrom EverandAnswers to Selected Problems in Multivariable Calculus with Linear Algebra and SeriesRating: 1.5 out of 5 stars1.5/5 (2)
- Source DF Adj Ss Adj Ms F-Value P-Value SigDocument7 pagesSource DF Adj Ss Adj Ms F-Value P-Value SigDiana Yesica Muñoz CisnerosNo ratings yet
- Final Exam: DISC 333 (Part 2)Document11 pagesFinal Exam: DISC 333 (Part 2)Ahsan IshtiaqNo ratings yet
- La Matrice Des Effets N°.essai S A B C D A.B A.C A.D B.C B.D C.DDocument4 pagesLa Matrice Des Effets N°.essai S A B C D A.B A.C A.D B.C B.D C.DDounia SaidiNo ratings yet
- MATLAB ReconciliationDocument8 pagesMATLAB ReconciliationAllan PaoloNo ratings yet
- Assignment 1 Sol 2022Document4 pagesAssignment 1 Sol 2022Inès ChougraniNo ratings yet
- Lab Wk1soln PDFDocument14 pagesLab Wk1soln PDFPeper12345No ratings yet
- Part (12) - Error AnalysisDocument22 pagesPart (12) - Error Analysisأحمد الحريريNo ratings yet
- Chapter 06 Design and Analysis of Experiments Solutions ManualDocument22 pagesChapter 06 Design and Analysis of Experiments Solutions Manualnurcholis helljogjaNo ratings yet
- HKMO Solution FinalDocument248 pagesHKMO Solution FinalDevin Wong0% (2)
- QE - Endsem2022 - Online ExamDocument6 pagesQE - Endsem2022 - Online Exambrahma2deen2chaudharNo ratings yet
- R06 Time-Series Analysis - AnswersDocument56 pagesR06 Time-Series Analysis - AnswersShashwat DesaiNo ratings yet
- Gujarat Technological UniversityDocument2 pagesGujarat Technological UniversityhemalNo ratings yet
- LSDDocument7 pagesLSDkasuwedaNo ratings yet
- 18s Cpe221 Sample Test1 SolutionDocument3 pages18s Cpe221 Sample Test1 SolutionKyra LathonNo ratings yet
- Solution - Sample Test: MULTIPLE CHOICE: Answer KeyDocument4 pagesSolution - Sample Test: MULTIPLE CHOICE: Answer KeyaaxdhpNo ratings yet
- Engineering ManagementDocument4 pagesEngineering ManagementPHILIPANTHONY MASILANGNo ratings yet
- Partial AnswersDocument14 pagesPartial AnswersRavi SinghNo ratings yet
- Addin Hayu - K1RIII - Klasifikasi Bakteri Secara Kimiawi Berdasarkan Data DNA Fingerprinting (Protein)Document5 pagesAddin Hayu - K1RIII - Klasifikasi Bakteri Secara Kimiawi Berdasarkan Data DNA Fingerprinting (Protein)Addin Hayu PNo ratings yet
- No 6Document10 pagesNo 6Fauziah Karina WNo ratings yet
- Groups Count Sum Average Variance: Perlakuan Mortalitas (Hari) C 2,09 B 2,205 G 2,396 E 2,645 D 2,695 F 2,984 A 4,46Document2 pagesGroups Count Sum Average Variance: Perlakuan Mortalitas (Hari) C 2,09 B 2,205 G 2,396 E 2,645 D 2,695 F 2,984 A 4,46Giat Elin MarleniNo ratings yet
- CH2-3-Gantt ChartDocument10 pagesCH2-3-Gantt ChartMohammad HameedNo ratings yet
- Basic StatDocument5 pagesBasic StatJeanelyn RodegerioNo ratings yet
- Summer Final ExaminationsDocument12 pagesSummer Final Examinationsjessica untalascoNo ratings yet
- MSA University - Maintenance Planning and Control Final Exam 2009Document3 pagesMSA University - Maintenance Planning and Control Final Exam 2009Good GuyNo ratings yet
- Sources of ErrorDocument22 pagesSources of ErrorHiraya HaeldrichNo ratings yet
- Sources of ErrorDocument28 pagesSources of ErrorShivam PatilNo ratings yet
- SQCT Assignment 1Document9 pagesSQCT Assignment 1Prem JhaNo ratings yet
- 1 PDFDocument14 pages1 PDFNadia Al HabsiNo ratings yet
- Rank CorrelationDocument4 pagesRank CorrelationNikitha GeorgeNo ratings yet
- Psikometri 12 - Azzahra Riang Kinanti - 20732010010Document14 pagesPsikometri 12 - Azzahra Riang Kinanti - 20732010010azzahraarkNo ratings yet
- Matlab Assignment: INSTR F243: Signal & SystemsDocument10 pagesMatlab Assignment: INSTR F243: Signal & SystemsRaj AryanNo ratings yet
- Assignment MatlabDocument10 pagesAssignment MatlabRaj AryanNo ratings yet
- Gujarat Technological UniversityDocument3 pagesGujarat Technological Universityyashesh vaidyaNo ratings yet
- TA112. BQA F.L Solution CMA September 2022 Exam.Document6 pagesTA112. BQA F.L Solution CMA September 2022 Exam.Mohammed Javed UddinNo ratings yet
- Regression: Standardized CoefficientsDocument8 pagesRegression: Standardized CoefficientsgedleNo ratings yet
- Stat 401B Exam 2 Key F15Document10 pagesStat 401B Exam 2 Key F15juanEs2374pNo ratings yet
- Zero and Negative ExponentsDocument2 pagesZero and Negative ExponentsJing CardozoNo ratings yet
- Stat 401B Exam 2 F15Document10 pagesStat 401B Exam 2 F15juanEs2374pNo ratings yet
- Geometric Nonlinearity: Chapter NineDocument27 pagesGeometric Nonlinearity: Chapter NineWeight lossNo ratings yet
- drz-201602 - Newsletter - Conquering The FE & PE Exams Problems, Solutions & ApplicationsDocument56 pagesdrz-201602 - Newsletter - Conquering The FE & PE Exams Problems, Solutions & ApplicationsalexescNo ratings yet
- Midterm Practice QuestionsDocument14 pagesMidterm Practice QuestionsbrsbyrmNo ratings yet
- Stat 401B Exam 2 Key F16Document10 pagesStat 401B Exam 2 Key F16juanEs2374pNo ratings yet
- Exercises: C A+B D A-B E A B F A. BDocument9 pagesExercises: C A+B D A-B E A B F A. BDen CelestraNo ratings yet
- Test Bank For Precalculus A Right Triangle Approach 5Th Edition Beecher Penna Bittinger 0321969553 978032196955 Full Chapter PDFDocument36 pagesTest Bank For Precalculus A Right Triangle Approach 5Th Edition Beecher Penna Bittinger 0321969553 978032196955 Full Chapter PDFscott.manning559100% (12)
- 2350 wksht06 PDFDocument1 page2350 wksht06 PDFTony LeeNo ratings yet
- Mathcad - Example 8Document20 pagesMathcad - Example 8cutefrenzyNo ratings yet
- Revision Test 1 Sem 1 2022Document10 pagesRevision Test 1 Sem 1 2022HannahNo ratings yet
- Solutions To Practice Problems For Part VI: Regression StatisticsDocument40 pagesSolutions To Practice Problems For Part VI: Regression Statisticsshannon caseyNo ratings yet
- No 1Document7 pagesNo 1Fauziah Karina WNo ratings yet
- Themultipleregressionmodel: I I1 I2 I3Document16 pagesThemultipleregressionmodel: I I1 I2 I3Mon LuffyNo ratings yet
- Stat 212: Business Statistics IiDocument9 pagesStat 212: Business Statistics IiyousafNo ratings yet
- Operation ReasearchDocument10 pagesOperation ReasearchGuluNo ratings yet
- Tutorial 3Document6 pagesTutorial 3Snehita NNo ratings yet
- Grade 8 Assignment MemoDocument6 pagesGrade 8 Assignment MemoSibongileNo ratings yet
- Unit 02 Textbook Chapte 2 Full SolutionDocument65 pagesUnit 02 Textbook Chapte 2 Full Solutionsam smithNo ratings yet
- Sol HW7Document22 pagesSol HW7Shweta Premanandan100% (2)
- Topic 8: SPC: Mean Value of First Subgroup (Document4 pagesTopic 8: SPC: Mean Value of First Subgroup (Azlie AzizNo ratings yet
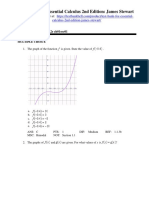
- Test Bank For Essential Calculus 2nd Edition James StewartDocument24 pagesTest Bank For Essential Calculus 2nd Edition James StewartLawrence Walker100% (34)
- Statistics and Probability Module 2Document7 pagesStatistics and Probability Module 2Angela Cuevas Dimaano100% (1)
- Applied Stochastic ProcessesDocument16 pagesApplied Stochastic ProcessesjeremyNo ratings yet
- Statistical Inference: EstimationDocument6 pagesStatistical Inference: EstimationSharlize Veyen RuizNo ratings yet
- Step FOPDT LengkapDocument110 pagesStep FOPDT LengkapRio Ananda PutraNo ratings yet
- Course Project 2020-21Document9 pagesCourse Project 2020-21Dane SinclairNo ratings yet
- Unit 2 Public KeyDocument45 pagesUnit 2 Public KeyAniket ChandaNo ratings yet
- Functions of Random VariablesDocument5 pagesFunctions of Random VariablesMINNIENOSENo ratings yet
- Uncertainty Budget TemplateDocument4 pagesUncertainty Budget TemplateMatthew HaleNo ratings yet
- Basic Calculus ReviewerDocument9 pagesBasic Calculus ReviewerGelo VeeNo ratings yet
- Chapter 10Document8 pagesChapter 10Aldon JimenezNo ratings yet
- Distribusi TemperaturDocument10 pagesDistribusi TemperaturAdri SuryanaNo ratings yet
- Artificial Neural Networks Architecture ApplicationsDocument264 pagesArtificial Neural Networks Architecture ApplicationsRaamses Díaz75% (8)
- Elementary Statistics: Larson FarberDocument25 pagesElementary Statistics: Larson FarberyuliandriansyahNo ratings yet
- Module 4 - Decision TheoryDocument32 pagesModule 4 - Decision TheoryGhillian Mae GuiangNo ratings yet
- Whitepaper QuopiDocument19 pagesWhitepaper Quopiliam veluNo ratings yet
- Multi-Keyword Searchable Encryption System For Distributed Systems in Cloud TechnologyDocument5 pagesMulti-Keyword Searchable Encryption System For Distributed Systems in Cloud TechnologyBaranishankarNo ratings yet
- Experiment 1: Aim: Write Down Two Intelligent Programs For The Tic-Tac Toe Problem. TheoryDocument45 pagesExperiment 1: Aim: Write Down Two Intelligent Programs For The Tic-Tac Toe Problem. Theorychirag yadavNo ratings yet
- KPK N: 1987 Imo Problems/ Problem 1 ProblemDocument3 pagesKPK N: 1987 Imo Problems/ Problem 1 ProblemKhant Si ThuNo ratings yet
- Oel Lab 2Document3 pagesOel Lab 2syazNo ratings yet
- A Mathematical Approach To One Dimensional Burgers' EquationDocument10 pagesA Mathematical Approach To One Dimensional Burgers' EquationzoragiNo ratings yet
- Data Mining Clustering PDFDocument15 pagesData Mining Clustering PDFSwing TradeNo ratings yet
- StackDocument18 pagesStackadiraihajaNo ratings yet
- CSE3999 Technical Answers To Real World Problems Digital Assignment - 7Document19 pagesCSE3999 Technical Answers To Real World Problems Digital Assignment - 7ty juNo ratings yet
- Control of Mobile Robots: Glue Lectures: InstructorDocument28 pagesControl of Mobile Robots: Glue Lectures: Instructoryashar2500No ratings yet
- Data Mining Unit 5Document30 pagesData Mining Unit 5Dr. M. Kathiravan Assistant Professor III - CSENo ratings yet
- 02-knn NotesDocument23 pages02-knn NotesJason BourneNo ratings yet
- Forbidden LatenciesDocument7 pagesForbidden LatenciesAr VindNo ratings yet
- Nonlinear OscillationDocument19 pagesNonlinear OscillationAthul S GovindNo ratings yet
- Ohm's Law For Random Media: Verification and Variations: Shashank GangradeDocument2 pagesOhm's Law For Random Media: Verification and Variations: Shashank GangradeShashank GangradeNo ratings yet
- Top Trading Cycle Project ReportDocument7 pagesTop Trading Cycle Project Reportkartikaybansal8825No ratings yet