You might also like
- Getting Started With Geit - RESDocument52 pagesGetting Started With Geit - RESnicolepetrescu100% (2)
- Enhancing Customer Satisfaction & PLN Efficiency Through Smart Utility & DigitalizationDocument20 pagesEnhancing Customer Satisfaction & PLN Efficiency Through Smart Utility & DigitalizationSyarif HidayatNo ratings yet
- Lecture 7 Characterizing Network Traffic by Rab Nawaz JadoonDocument13 pagesLecture 7 Characterizing Network Traffic by Rab Nawaz Jadoonyasar khanNo ratings yet
- Lecture 8 Characterizing Network Traffic Part II by Rab Nawaz JadoonDocument29 pagesLecture 8 Characterizing Network Traffic Part II by Rab Nawaz Jadoonyasar khanNo ratings yet
- ETCW03Document3 pagesETCW03Editor IJAERDNo ratings yet
- Session 3.9.1Document11 pagesSession 3.9.1dhurgadeviNo ratings yet
- Data Handling & Analytics: Unit 5Document18 pagesData Handling & Analytics: Unit 5Arun K KNo ratings yet
- Intrusion Detection in Cloud Computing Environment Using Neural NetworkDocument5 pagesIntrusion Detection in Cloud Computing Environment Using Neural NetworksamNo ratings yet
- Extrahop Product Overview 2015Document2 pagesExtrahop Product Overview 2015Taher JalloulNo ratings yet
- Bigdata Unit-IiDocument33 pagesBigdata Unit-Ii4241 DAYANA SRI VARSHANo ratings yet
- MSC449 PrintDocument2 pagesMSC449 PrintBangla INFO.No ratings yet
- File000000 1302989981Document20 pagesFile000000 1302989981黄伟No ratings yet
- Low-Latency Multi-Threaded Ensemble Learning For Dynamic Big Data StreamsDocument10 pagesLow-Latency Multi-Threaded Ensemble Learning For Dynamic Big Data StreamsashinantonyNo ratings yet
- DBT Unit4 PDFDocument152 pagesDBT Unit4 PDFChaitanya MadhavNo ratings yet
- Parallel Computing Based Distribution Network - Reliability Evaluation Technology ResearchDocument6 pagesParallel Computing Based Distribution Network - Reliability Evaluation Technology ResearchSudiharyantoLikaNo ratings yet
- HCIP-IoT Developer V2.5 Training MaterialDocument416 pagesHCIP-IoT Developer V2.5 Training MaterialDavid LevicNo ratings yet
- Low Latency Apache SparkDocument5 pagesLow Latency Apache SparkAndres BenavidesNo ratings yet
- M1 - Introduction To Processing Streaming DataDocument16 pagesM1 - Introduction To Processing Streaming DataEdgar SanchezNo ratings yet
- S4: Distributed Stream Computing PlatformDocument8 pagesS4: Distributed Stream Computing PlatformOtávio CarvalhoNo ratings yet
- Scheduling Algorithms For Efficient Execution of Stream Workflow Applications in Multicloud EnvironmentsDocument14 pagesScheduling Algorithms For Efficient Execution of Stream Workflow Applications in Multicloud EnvironmentsBM MithunNo ratings yet
- Discovery Protocol SIC - 2014 1 Art3Document8 pagesDiscovery Protocol SIC - 2014 1 Art3darek RaceNo ratings yet
- Top of Form Search Bottom of FormDocument19 pagesTop of Form Search Bottom of FormNaga RajuNo ratings yet
- of Data ReplicationDocument24 pagesof Data Replicationexon1123No ratings yet
- Introduction To Wireless Sensor Networks: Networking AspectsDocument43 pagesIntroduction To Wireless Sensor Networks: Networking AspectsShambhu RamNo ratings yet
- Indexing The Things ..: V.R.Siddhartha Engineering College VijayawadaDocument17 pagesIndexing The Things ..: V.R.Siddhartha Engineering College VijayawadamycatalystsNo ratings yet
- Cactus Project & Collaborative WorkingDocument11 pagesCactus Project & Collaborative WorkingAnkit SinghNo ratings yet
- Internal 3 AnswerDocument10 pagesInternal 3 AnswerTKKNo ratings yet
- Big Data Processing: Jiaul PaikDocument47 pagesBig Data Processing: Jiaul PaikMomin SuburNo ratings yet
- Slide1Document15 pagesSlide1api-3845765100% (2)
- End Term ReportDocument26 pagesEnd Term ReportMohit AkerkarNo ratings yet
- Unit 2Document10 pagesUnit 2Yatin6004No ratings yet
- Rupa 4th SemDocument3 pagesRupa 4th SemSANDHYA RANI N 218002114No ratings yet
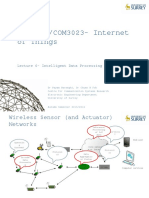
- EEEM048/COM3023-Internet of Things: Lecture 6 - Intelligent Data ProcessingDocument40 pagesEEEM048/COM3023-Internet of Things: Lecture 6 - Intelligent Data ProcessingPV sushmithaNo ratings yet
- High-Performance IoT Streaming Data Prediction System Using SparkDocument8 pagesHigh-Performance IoT Streaming Data Prediction System Using SparkBlyss BMNo ratings yet
- An Effective and Secure Routing System Using Intelligent Water Drop ApproachDocument9 pagesAn Effective and Secure Routing System Using Intelligent Water Drop ApproachPraveen KumarNo ratings yet
- Exploiting Dynamic Resource Allocation For Efficient Parallel Data Processing in The Cloud AbstractDocument6 pagesExploiting Dynamic Resource Allocation For Efficient Parallel Data Processing in The Cloud AbstractLoki ChNo ratings yet
- Week5 IoT SoftwareDocument37 pagesWeek5 IoT SoftwareHector TiboNo ratings yet
- SPIDER ASystemforScalableParallelDistributedEvaluationoflarge ScaleRDFDataDocument5 pagesSPIDER ASystemforScalableParallelDistributedEvaluationoflarge ScaleRDFDataKishore Kumar RaviChandranNo ratings yet
- 1703 06376 PDFDocument5 pages1703 06376 PDFRoger Dante Ripas MamaniNo ratings yet
- 1703 06376 PDFDocument5 pages1703 06376 PDFRoger Dante Ripas MamaniNo ratings yet
- ResumeDocument2 pagesResumecendhuNo ratings yet
- Big Data and Analytics: Getting Started With Arcgis: Mike Park Erik HoelDocument34 pagesBig Data and Analytics: Getting Started With Arcgis: Mike Park Erik Hoelnagesh nangiNo ratings yet
- CPE 445-Internet of Things - Chapter 7Document39 pagesCPE 445-Internet of Things - Chapter 7fa20-bce-046No ratings yet
- Searching The Internet of ThingsDocument24 pagesSearching The Internet of ThingsjeyalakshmiNo ratings yet
- Adaptive ClusteringDocument11 pagesAdaptive ClusteringjyothiNo ratings yet
- Fpga Implementation of A License Plate Recognition Soc Using Automatically Generated Streaming AcceleratorsDocument8 pagesFpga Implementation of A License Plate Recognition Soc Using Automatically Generated Streaming AcceleratorsMuhammad Awais Bin AltafNo ratings yet
- Resume - Gandhi (Full Time)Document1 pageResume - Gandhi (Full Time)Prit GalaNo ratings yet
- An Embedded System For Collection and Real-Time Classification of A Tactile DatasetDocument12 pagesAn Embedded System For Collection and Real-Time Classification of A Tactile DatasetChaitanya ParaleNo ratings yet
- ECS781P 2 CloudNetworkingDocument59 pagesECS781P 2 CloudNetworkingYen-Kai ChengNo ratings yet
- Midterm 94130 PDFDocument7 pagesMidterm 94130 PDFprasannnaNo ratings yet
- Module IIDocument22 pagesModule IIjohnsonjoshal5No ratings yet
- Instrumentation and Measurement: M.Prasad Naidu MSC Medical Biochemistry, PH.D Research ScholarDocument22 pagesInstrumentation and Measurement: M.Prasad Naidu MSC Medical Biochemistry, PH.D Research ScholarDr. M. Prasad NaiduNo ratings yet
- Portal Presentation MaterialDocument80 pagesPortal Presentation MaterialRitik MaheshwariNo ratings yet
- QoS-enabled ANFIS Dead Reckoning Algorithm For DisDocument11 pagesQoS-enabled ANFIS Dead Reckoning Algorithm For DisacevalloNo ratings yet
- Data Processing For Large Database Using Mapreduce Approach Using ApsoDocument59 pagesData Processing For Large Database Using Mapreduce Approach Using ApsosumankumarNo ratings yet
- Apache Iotdb: Time-Series Database For Internet of ThingsDocument4 pagesApache Iotdb: Time-Series Database For Internet of ThingsCosmic DustNo ratings yet
- Network Design ToolsDocument13 pagesNetwork Design ToolsUmang SomeshwarNo ratings yet
- BDA UNIT-2 (Final)Document27 pagesBDA UNIT-2 (Final)Sai HareenNo ratings yet
- Desarrollo Basado en Modelos de Aplicaciones Intensivas de Datos Sobre Recursos de La NubeDocument32 pagesDesarrollo Basado en Modelos de Aplicaciones Intensivas de Datos Sobre Recursos de La NubeDaniela BaezNo ratings yet
- ABSTRACT Exploiting DynamicDocument5 pagesABSTRACT Exploiting DynamicfeliejuNo ratings yet
- U4S9Document18 pagesU4S9shubham gupta (RA1911004010290)No ratings yet
- Pipelined Processor Farms: Structured Design for Embedded Parallel SystemsFrom EverandPipelined Processor Farms: Structured Design for Embedded Parallel SystemsNo ratings yet
- 174-Article Text-1125-1-10-20121226Document103 pages174-Article Text-1125-1-10-20121226Bin FuzilNo ratings yet
- Use Case 10 Míllion Smart Meter OSS - Summit - Japan - 3Document51 pagesUse Case 10 Míllion Smart Meter OSS - Summit - Japan - 3bushraNazirNo ratings yet
- Usecase IMP Paper-09Document4 pagesUsecase IMP Paper-09bushraNazirNo ratings yet
- Benchmarking Processing Engines: DistributedDocument16 pagesBenchmarking Processing Engines: DistributedbushraNazirNo ratings yet
- Pattern INTRODocument11 pagesPattern INTRObushraNazirNo ratings yet
- Analysis of Real Time Stream Processing Systems Considering LatencyDocument7 pagesAnalysis of Real Time Stream Processing Systems Considering LatencybushraNazirNo ratings yet
- Benchmarking Cloud Serving Systems With YCSBDocument12 pagesBenchmarking Cloud Serving Systems With YCSBbushraNazirNo ratings yet
- DB BMDocument4 pagesDB BMbushraNazirNo ratings yet
- Analysis of Real Time Stream Processing Systems Considering LatencyDocument7 pagesAnalysis of Real Time Stream Processing Systems Considering LatencybushraNazirNo ratings yet
- (Instructor Version) : Packet Tracer - Connect and Monitor Iot DevicesDocument7 pages(Instructor Version) : Packet Tracer - Connect and Monitor Iot DevicesHayNo ratings yet
- Automation Ai Smart Neural ManufacturingDocument38 pagesAutomation Ai Smart Neural ManufacturingLUIS ALBERTO MEZA GOMEZNo ratings yet
- Designing With AR and VRDocument30 pagesDesigning With AR and VRPigmy LeeNo ratings yet
- AWS Summit Online ASEAN Recap 2020 - Agenda at A GlanceDocument2 pagesAWS Summit Online ASEAN Recap 2020 - Agenda at A GlancebehanchodNo ratings yet
- Calculos PropostaDocument4 pagesCalculos PropostaMiguel CavacoNo ratings yet
- NB-IoT White Paper - NokiaDocument18 pagesNB-IoT White Paper - NokiaDJRashDownload100% (1)
- Improving Manufacturing Performance With Big Data: Architect's Guide and Reference Architecture IntroductionDocument23 pagesImproving Manufacturing Performance With Big Data: Architect's Guide and Reference Architecture IntroductionOzioma IhekwoabaNo ratings yet
- Digital Twin TechnologyDocument10 pagesDigital Twin TechnologyNIkhil Raj BNo ratings yet
- P.C.P.November 2015Document132 pagesP.C.P.November 2015ste123456789No ratings yet
- 4 Emerging TechnologiesDocument22 pages4 Emerging TechnologiesES BirnurNo ratings yet
- UNIT 4 - 2 - Challenges in IoTDocument29 pagesUNIT 4 - 2 - Challenges in IoTRitesh ShuklaNo ratings yet
- Practicals On Iot Solutions On Cisco Packet TracerDocument72 pagesPracticals On Iot Solutions On Cisco Packet TracerHortence SiuNo ratings yet
- Internet of Things - Principles and ParadigmsDocument53 pagesInternet of Things - Principles and Paradigmsalbert aponteNo ratings yet
- Alarm PDFDocument14 pagesAlarm PDFMuhammad NomanNo ratings yet
- "Internet of Things (Iot) ": A Microproject Report ONDocument17 pages"Internet of Things (Iot) ": A Microproject Report ONYogesh Kadam96% (25)
- Dec2015 PredictionsDocument107 pagesDec2015 Predictionskuldeep2424No ratings yet
- Smart Home Design For Electronic Devices Monitoring Based Wireless Gateway Network Using Cisco Packet TracerDocument24 pagesSmart Home Design For Electronic Devices Monitoring Based Wireless Gateway Network Using Cisco Packet Tracervicky100% (1)
- Design and Implementation of Smart Home Using Cisco Packet Tracer Simulator 7.2Document21 pagesDesign and Implementation of Smart Home Using Cisco Packet Tracer Simulator 7.2Hari kumar ReddyNo ratings yet
- (NATO Science For Peace and Security Series B - Physics and Biophysics) Plamen Petkov, Dumitru Tsiulyanu, Cyril Popov, Wilhelm Kulisch - Advanced NDocument499 pages(NATO Science For Peace and Security Series B - Physics and Biophysics) Plamen Petkov, Dumitru Tsiulyanu, Cyril Popov, Wilhelm Kulisch - Advanced NTalita SouzaNo ratings yet
- Automotion PDFDocument44 pagesAutomotion PDFNatalia100% (1)
- Palm Oil Traceability Blockchain Meets Supply ChainDocument38 pagesPalm Oil Traceability Blockchain Meets Supply ChainJohn AcidNo ratings yet
- AISCIENCES - Data Science Cookbook - V0Document244 pagesAISCIENCES - Data Science Cookbook - V0KayNo ratings yet
- Report On Iot InternshipDocument35 pagesReport On Iot InternshipSainadh AnaganiNo ratings yet
- HitekNOFAL - Company ProfileDocument88 pagesHitekNOFAL - Company ProfileKAREEEMNo ratings yet
- DQN-Based Optimization Framework For Secure Sharded Blockchain SystemsDocument15 pagesDQN-Based Optimization Framework For Secure Sharded Blockchain SystemsCông Nguyễn ThànhNo ratings yet
- Ege Ai Statement 2018Document24 pagesEge Ai Statement 2018Pablo Ramírez RivasNo ratings yet
- 19-08-28 Continental Opposition To Avanci's Motion To Transfer VenueDocument32 pages19-08-28 Continental Opposition To Avanci's Motion To Transfer VenueFlorian MuellerNo ratings yet
- 5G Course MaterialDocument15 pages5G Course MaterialRao ENo ratings yet