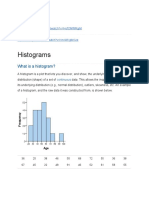
You might also like
- Image Histogram: Unveiling Visual Insights, Exploring the Depths of Image Histograms in Computer VisionFrom EverandImage Histogram: Unveiling Visual Insights, Exploring the Depths of Image Histograms in Computer VisionNo ratings yet
- Staistics - Continous DataDocument20 pagesStaistics - Continous DataDr See Kin HaiNo ratings yet
- 3 Data Description and Measures of Central TenndencyDocument72 pages3 Data Description and Measures of Central TenndencyOlivier MakengoNo ratings yet
- Basic StatisticsDocument23 pagesBasic StatisticsZAKAYO NJONYNo ratings yet
- Business Statistics: Shalabh Singh Room No: 231 Shalabhsingh@iim Raipur - Ac.inDocument30 pagesBusiness Statistics: Shalabh Singh Room No: 231 Shalabhsingh@iim Raipur - Ac.inDipak Kumar PatelNo ratings yet
- Summation FD MCTDocument77 pagesSummation FD MCTDaven DoradoNo ratings yet
- Bio-Statistics: School of Bio-Science and Engineering, 2016Document134 pagesBio-Statistics: School of Bio-Science and Engineering, 2016jagriti kalyaniNo ratings yet
- Lecture MAterial 2Document23 pagesLecture MAterial 2Christine RNo ratings yet
- Descriptive Statistics: Definition 10.2.1Document16 pagesDescriptive Statistics: Definition 10.2.1anipa mwaleNo ratings yet
- Chapter2 Collection Organization and Presentation of DataDocument47 pagesChapter2 Collection Organization and Presentation of DataMerv Derek Camado67% (6)
- Lecture 2. Exploratory Data AnalysisDocument28 pagesLecture 2. Exploratory Data AnalysisPrarthana PNo ratings yet
- Frequency Distribution Lecture 2 3Document11 pagesFrequency Distribution Lecture 2 3rafid RafuuNo ratings yet
- ACFrOgCLhIGeDgB2WhO2JO48tloZ8E rlj1-F 622LEA08XeUMCxl0syYf7HFFbqBbMYWBnDPgYh9F4QJmNJtvKVKHbz7pxfnqX2P8gOEtOFF 2tSMAPUEito ayTMU5jS3MjFiTn-YJWnV1YMeFDocument31 pagesACFrOgCLhIGeDgB2WhO2JO48tloZ8E rlj1-F 622LEA08XeUMCxl0syYf7HFFbqBbMYWBnDPgYh9F4QJmNJtvKVKHbz7pxfnqX2P8gOEtOFF 2tSMAPUEito ayTMU5jS3MjFiTn-YJWnV1YMeFADARSH CNo ratings yet
- CH 07Document45 pagesCH 07sukhmandhawan88No ratings yet
- Organization and Presentation of Data: Graphs: What Is The Difference Between A Bar Chart and A Histogram?Document4 pagesOrganization and Presentation of Data: Graphs: What Is The Difference Between A Bar Chart and A Histogram?Joni Czarina AmoraNo ratings yet
- Sampling Distribution of the Mean ExplainedDocument26 pagesSampling Distribution of the Mean ExplainedVarsha PeriwalNo ratings yet
- Statistics Chapter 1 SummaryDocument53 pagesStatistics Chapter 1 SummaryKevin AlexanderNo ratings yet
- 4 Numerical Methods For Describing DataDocument50 pages4 Numerical Methods For Describing DataKrung KrungNo ratings yet
- Statistics Notes Part 1Document26 pagesStatistics Notes Part 1Lukong LouisNo ratings yet
- 2035 CH2 NotesDocument42 pages2035 CH2 Noteskejacob629No ratings yet
- PRESENT DATA EFFECTIVELYDocument55 pagesPRESENT DATA EFFECTIVELYNImra ShahNo ratings yet
- ES 01 Central and DispersionDocument21 pagesES 01 Central and DispersionTaimoor Hassan KhanNo ratings yet
- Elementary StatisticsDocument73 pagesElementary StatisticsDeepak GoyalNo ratings yet
- HistogramDocument12 pagesHistogramamelia99No ratings yet
- STAT606 Class03Document18 pagesSTAT606 Class03codebreaker911No ratings yet
- Devore Ch. 1 Navidi Ch. 1Document16 pagesDevore Ch. 1 Navidi Ch. 1chinchouNo ratings yet
- Stats Lecture 07. Sample DistributionDocument36 pagesStats Lecture 07. Sample DistributionShair Muhammad hazaraNo ratings yet
- Graphical Representation of DataDocument36 pagesGraphical Representation of DataNihal AhmadNo ratings yet
- Biostat Lecture 3-1Document162 pagesBiostat Lecture 3-1ODAA TUBENo ratings yet
- Biostatistics Research Methods SummaryDocument54 pagesBiostatistics Research Methods Summaryhadin khanNo ratings yet
- SCI2010 - Week 4Document5 pagesSCI2010 - Week 4Luk Ee RenNo ratings yet
- Displaying and Describing Quantitative DataDocument49 pagesDisplaying and Describing Quantitative DataJosh PotashNo ratings yet
- Organizing Data EDADocument20 pagesOrganizing Data EDADan PadillaNo ratings yet
- SAT - Lec2 - Descriptive StatisticsDocument60 pagesSAT - Lec2 - Descriptive StatisticsKhanh Nguyen VanNo ratings yet
- Stats Class 2Document26 pagesStats Class 2Indar SoochitNo ratings yet
- Frequency Distribution: A Frequency Distribution Is Constructed For Three Main ReasonsDocument15 pagesFrequency Distribution: A Frequency Distribution Is Constructed For Three Main ReasonsBhawna JoshiNo ratings yet
- Statistics Modul III CavabDocument41 pagesStatistics Modul III CavabHikmət RüstəmovNo ratings yet
- Statistical Inferences Past PaperDocument7 pagesStatistical Inferences Past PaperMubarakNo ratings yet
- Chapter 3Document19 pagesChapter 3Ahmad baderNo ratings yet
- Basics of Statistics - 1 PDFDocument58 pagesBasics of Statistics - 1 PDFRajat ShettyNo ratings yet
- Unit 2Document11 pagesUnit 2Ragha RamojuNo ratings yet
- Course: Biostatistics: Haramaya University, ChmsDocument49 pagesCourse: Biostatistics: Haramaya University, ChmsRida Awwal100% (1)
- Chapter 4 Statistics - Descriptive Statistics, Normal Distribution, and ProbabilityDocument85 pagesChapter 4 Statistics - Descriptive Statistics, Normal Distribution, and Probabilityvincentch96No ratings yet
- Understanding HistogramsDocument4 pagesUnderstanding HistogramsJohn JensenNo ratings yet
- Welcome To The: Scatter PlotsDocument42 pagesWelcome To The: Scatter PlotsRajVedricVarias100% (1)
- Notes 4 Visualizing Data RJMurden 2021Document48 pagesNotes 4 Visualizing Data RJMurden 2021BenNo ratings yet
- Nasdaq Losers October 2008 Performance DataDocument18 pagesNasdaq Losers October 2008 Performance DataSudip SahaNo ratings yet
- Histogram: For The Histograms Used in Digital Image Processing, See andDocument8 pagesHistogram: For The Histograms Used in Digital Image Processing, See andsuccesskandhanNo ratings yet
- Frequency Distribution and GraphsDocument28 pagesFrequency Distribution and GraphsManish KumarNo ratings yet
- Understanding and Presenting DataDocument26 pagesUnderstanding and Presenting DataZC47No ratings yet
- Lecture Notes 2 Data Organization and PresentationDocument26 pagesLecture Notes 2 Data Organization and PresentationEnock T MuchinakoNo ratings yet
- Mata Kuliah Statistik Dasar: Ukuran Penyebaran Data Dan Penyajian DataDocument16 pagesMata Kuliah Statistik Dasar: Ukuran Penyebaran Data Dan Penyajian DataSanJuniorNo ratings yet
- CS3332 Probability Course OverviewDocument11 pagesCS3332 Probability Course OverviewJazyrin M. PullanNo ratings yet
- Mathematical Statistics: Instructor: Dr. Deshi YeDocument42 pagesMathematical Statistics: Instructor: Dr. Deshi YeAhmed Kadem ArabNo ratings yet
- Point Pattern Analysis With Past: Øyvind Hammer, Natural History Museum, University of Oslo, 2011-01-03Document7 pagesPoint Pattern Analysis With Past: Øyvind Hammer, Natural History Museum, University of Oslo, 2011-01-03Emil TengwarNo ratings yet
- Statistics and ProbabilityDocument253 pagesStatistics and Probabilityanirudhsaxena865No ratings yet
- Statistics and ProbabilityDocument196 pagesStatistics and ProbabilitySiddharth GuptaNo ratings yet
- Research Methods Lesson NotesDocument35 pagesResearch Methods Lesson NotesCarol SoiNo ratings yet
- Statistical Analysis With Software Application - Week2Document76 pagesStatistical Analysis With Software Application - Week2Danny WeeNo ratings yet
- student application4Document14 pagesstudent application4sunil kumarNo ratings yet
- Ardl1Document166 pagesArdl1sunil kumarNo ratings yet
- for students14Document9 pagesfor students14sunil kumarNo ratings yet
- Corporate Sustainability in Bangladeshi Banks: Proactive or Reactive Ethical Behavior?Document18 pagesCorporate Sustainability in Bangladeshi Banks: Proactive or Reactive Ethical Behavior?sunil kumarNo ratings yet
- Bangla 4Document11 pagesBangla 4sunil kumarNo ratings yet
- Input Specific2Document40 pagesInput Specific2sunil kumarNo ratings yet
- Bangla 2Document10 pagesBangla 2sunil kumarNo ratings yet
- Bangla 5Document15 pagesBangla 5sunil kumarNo ratings yet
- Input SpecificDocument24 pagesInput Specificsunil kumarNo ratings yet
- Bangla 3Document9 pagesBangla 3sunil kumarNo ratings yet
- An Application of Window Data Envelopment Analysis Methodology With Double Frontier in The Performance Assessment of Shiraz University CollegesDocument14 pagesAn Application of Window Data Envelopment Analysis Methodology With Double Frontier in The Performance Assessment of Shiraz University Collegessunil kumarNo ratings yet
- Eviews Johansen3 PDFDocument5 pagesEviews Johansen3 PDFsunil kumarNo ratings yet
- A New Network Data Envelopment Analysis Models To Measure The Efficiency of Natural Gas Supply ChainDocument26 pagesA New Network Data Envelopment Analysis Models To Measure The Efficiency of Natural Gas Supply Chainsunil kumarNo ratings yet
- Input Specific5Document8 pagesInput Specific5sunil kumarNo ratings yet
- Pergamon: Computers Ops ResDocument6 pagesPergamon: Computers Ops Ressunil kumarNo ratings yet
- SUPER EFFICIENCY DATA ANALYSIS MODELSDocument7 pagesSUPER EFFICIENCY DATA ANALYSIS MODELSsunil kumarNo ratings yet
- Solving DEA Models in Spreadsheets and Modeling Languages: Uy VXDocument5 pagesSolving DEA Models in Spreadsheets and Modeling Languages: Uy VXsunil kumarNo ratings yet
- Revisiting Nexus Between Economic Growth and Electricity in IndiaDocument8 pagesRevisiting Nexus Between Economic Growth and Electricity in Indiasunil kumarNo ratings yet
- Elect 28Document6 pagesElect 28sunil kumarNo ratings yet
- Can Electricity Consumption Be Useful in Predicting Nigerian Economic Growth? Evidence From Error Correction ModelDocument16 pagesCan Electricity Consumption Be Useful in Predicting Nigerian Economic Growth? Evidence From Error Correction Modelsunil kumarNo ratings yet
- Cointegration Bank Pak2Document20 pagesCointegration Bank Pak2sunil kumarNo ratings yet
- Eviews Johansen3 PDFDocument5 pagesEviews Johansen3 PDFsunil kumarNo ratings yet
- Joe Zhu Insuarnce ReviewDocument13 pagesJoe Zhu Insuarnce Reviewsunil kumarNo ratings yet
- Elect 30Document16 pagesElect 30sunil kumarNo ratings yet
- Dynamic Analysis of The Relationship Between Stock Prices and Macroeconomic Variables: An Empirical Study of Pakistan Stock ExchangeDocument18 pagesDynamic Analysis of The Relationship Between Stock Prices and Macroeconomic Variables: An Empirical Study of Pakistan Stock Exchangesunil kumarNo ratings yet
- Cointegration Bank PakDocument11 pagesCointegration Bank Paksunil kumarNo ratings yet
- Lecture1 - Index Numbers For Productivity MeasurementDocument13 pagesLecture1 - Index Numbers For Productivity Measurementsunil kumarNo ratings yet
- IJPPM - Best SubsetsDocument29 pagesIJPPM - Best Subsetssunil kumarNo ratings yet
- Applied Economics LettersDocument6 pagesApplied Economics Letterssunil kumarNo ratings yet
- 3.0MP 4G Smart All Time Color Bullet Cam 8075Document2 pages3.0MP 4G Smart All Time Color Bullet Cam 8075IshakhaNo ratings yet
- Final MTech ProjectDocument30 pagesFinal MTech ProjectArunSharmaNo ratings yet
- Programme EnergyDocument9 pagesProgramme EnergyAbdulazizNo ratings yet
- Xist PDFDocument2 pagesXist PDFAgustin Gago LopezNo ratings yet
- The Law of DemandDocument13 pagesThe Law of DemandAngelique MancillaNo ratings yet
- India's Fertilizer IndustryDocument15 pagesIndia's Fertilizer Industrydevika20No ratings yet
- Sri Bhavishya Educational AcademyDocument4 pagesSri Bhavishya Educational AcademyAnonymous A6Jnef04No ratings yet
- Interpersonal Skills RubricDocument1 pageInterpersonal Skills RubricJason Stammen100% (1)
- Macroeconomics: University of Economics Ho Chi Minh CityDocument193 pagesMacroeconomics: University of Economics Ho Chi Minh CityNguyễn Văn GiápNo ratings yet
- Basic French ConversationDocument7 pagesBasic French Conversationeszti kozmaNo ratings yet
- PHY3201Document3 pagesPHY3201Ting Woei LuenNo ratings yet
- Flyer Radar Based Floating Roof Monitoring Flyer Rosemount en 586140Document2 pagesFlyer Radar Based Floating Roof Monitoring Flyer Rosemount en 586140Patricio UretaNo ratings yet
- Slip-System Cal PDFDocument13 pagesSlip-System Cal PDFVanaja JadapalliNo ratings yet
- Aci 306.1Document5 pagesAci 306.1safak kahramanNo ratings yet
- 1814 d01 PDFDocument20 pages1814 d01 PDFteletrabbiesNo ratings yet
- Conference Flyer ChosenDocument4 pagesConference Flyer ChosenOluwatobi OgunfoworaNo ratings yet
- Karl-Fischer TitrationDocument19 pagesKarl-Fischer TitrationSomnath BanerjeeNo ratings yet
- Jenkins Lab Guide: 172-172, 5th Floor Old Mahabalipuram Road (Above Axis Bank-PTC Bus Stop) Thuraipakkam Chennai 600097Document45 pagesJenkins Lab Guide: 172-172, 5th Floor Old Mahabalipuram Road (Above Axis Bank-PTC Bus Stop) Thuraipakkam Chennai 600097thecoinmaniac hodlNo ratings yet
- The Philosophy of Composition (1846)Document20 pagesThe Philosophy of Composition (1846)Denise CoronelNo ratings yet
- What does high frequency mean for TIG weldingDocument14 pagesWhat does high frequency mean for TIG weldingUmaibalanNo ratings yet
- Management The Essentials Australia 4th Edition Robbins Test BankDocument29 pagesManagement The Essentials Australia 4th Edition Robbins Test Bankfidelmanhangmhr100% (38)
- Madhwacharya ' S Lineage - "GURU CHARITE"Document136 pagesMadhwacharya ' S Lineage - "GURU CHARITE"Srivatsa100% (4)
- Understanding Customer Loyaltyfor Retail StoreandtheinfluencingfactorsDocument15 pagesUnderstanding Customer Loyaltyfor Retail StoreandtheinfluencingfactorsTanmay PaulNo ratings yet
- 302340KWDocument22 pages302340KWValarmathiNo ratings yet
- XETEC 4g300 / 4g600Document6 pagesXETEC 4g300 / 4g600Harun ARIKNo ratings yet
- Electrode ChemDocument17 pagesElectrode Chemapi-372366467% (3)
- ADP Pink Diamond Investment Guide 2023Document47 pagesADP Pink Diamond Investment Guide 2023sarahNo ratings yet
- Guidelines For Submitting An Article To Gesta: General InformationDocument1 pageGuidelines For Submitting An Article To Gesta: General InformationneddyteddyNo ratings yet
- Edu Mphil SyllabusDocument27 pagesEdu Mphil Syllabussollu786_889163149No ratings yet
- Salary Survey (Hong Kong) - 2022Document7 pagesSalary Survey (Hong Kong) - 2022Nathan SmithNo ratings yet