You might also like
- Sub-seasonal to Seasonal Prediction: The Gap Between Weather and Climate ForecastingFrom EverandSub-seasonal to Seasonal Prediction: The Gap Between Weather and Climate ForecastingNo ratings yet
- WRF-1d PBL Model DocumentationDocument11 pagesWRF-1d PBL Model DocumentationBalaji ManirathnamNo ratings yet
- Encyclopedia of Atmospheric Sciences Second Edition V1 6 PDFDocument2,874 pagesEncyclopedia of Atmospheric Sciences Second Edition V1 6 PDFcfisicaster88% (8)
- Synoptic MeteorologyDocument40 pagesSynoptic Meteorologyyazqa100% (1)
- OUC Supervisor Information - Environment & Resource Protection ExpertsDocument97 pagesOUC Supervisor Information - Environment & Resource Protection ExpertssimplecobraNo ratings yet
- A Brief Introduction To Atmospheric Dynamics: J. H. Lacasce, UioDocument61 pagesA Brief Introduction To Atmospheric Dynamics: J. H. Lacasce, UioyyasamannNo ratings yet
- Ans HW2Document8 pagesAns HW2Sai Swetha KVNo ratings yet
- Isotope Geology-1-14Document14 pagesIsotope Geology-1-14LuisCruzNo ratings yet
- Mesoscale Modeling of Atmospheric Processes in IndiaDocument92 pagesMesoscale Modeling of Atmospheric Processes in IndiaraodvbNo ratings yet
- Conversion of Units of Temperature PDFDocument7 pagesConversion of Units of Temperature PDFrizal123No ratings yet
- Blunden Et Al. - STATE OF THE CLIMATE IN 2012 Editors PDFDocument258 pagesBlunden Et Al. - STATE OF THE CLIMATE IN 2012 Editors PDFMilton AraujoNo ratings yet
- CCD Noise SourcesDocument14 pagesCCD Noise Sourcesapi-3733788No ratings yet
- Lecture Notes On The Planetary Boundary LayerDocument156 pagesLecture Notes On The Planetary Boundary Layeryahooo82No ratings yet
- ARWUsersGuideV3 WRF ModelDocument411 pagesARWUsersGuideV3 WRF ModelZAXUM E-learning Open sourceNo ratings yet
- Idl Meteo IntroDocument39 pagesIdl Meteo IntrojjanueNo ratings yet
- Setup a Water Quality Model in MIKE SHEDocument32 pagesSetup a Water Quality Model in MIKE SHEQecil GamingNo ratings yet
- 57 - Weather & Climate Sciences E-Books ListDocument62 pages57 - Weather & Climate Sciences E-Books ListPeter RhoadsNo ratings yet
- Fundamentals of Electric Propulsion Ion and Hall ThrustersDocument8 pagesFundamentals of Electric Propulsion Ion and Hall ThrustersCindy0% (1)
- Evolution of Physical Oceanography PDFDocument2 pagesEvolution of Physical Oceanography PDFDevinNo ratings yet
- AF SkewT ManualDocument164 pagesAF SkewT ManualRicardo R de CarvalhoNo ratings yet
- Critical Analysis of The Critique of The Claim of Propeller-Assisted Straight-Downwind Land Sailing Faster Than WindDocument19 pagesCritical Analysis of The Critique of The Claim of Propeller-Assisted Straight-Downwind Land Sailing Faster Than WindFavio Alejandro Herrera ZapataNo ratings yet
- Meteorology10 WeatherintheTropicsDocument49 pagesMeteorology10 WeatherintheTropicsAvtechNo ratings yet
- Quantum Well Intermixing and Its ApplicationsDocument43 pagesQuantum Well Intermixing and Its ApplicationsMalik MalikNo ratings yet
- Weather Forcast System: Case Study By-Gajendra Singh 12 FDocument14 pagesWeather Forcast System: Case Study By-Gajendra Singh 12 FTanishq SainiNo ratings yet
- Tidal CorrectionDocument2 pagesTidal CorrectionInne Puspita SariNo ratings yet
- ARWUsersGuideV3 8Document434 pagesARWUsersGuideV3 8Gourav SahaNo ratings yet
- 近物solution PDFDocument145 pages近物solution PDF劉鴻軒100% (1)
- A Fast Integration Method For Translating-Pulsating Green's Function in Bessho's FormDocument12 pagesA Fast Integration Method For Translating-Pulsating Green's Function in Bessho's FormYuriy KrayniyNo ratings yet
- Isola ObspyDocument24 pagesIsola ObspyAndrea ProsperiNo ratings yet
- ThermoSolutions CHAPTER01Document55 pagesThermoSolutions CHAPTER01Fred EneaNo ratings yet
- Dynamic MeteorologyDocument214 pagesDynamic Meteorologyyyasamann100% (10)
- Taking the Temperature of the Earth: Steps towards Integrated Understanding of Variability and ChangeFrom EverandTaking the Temperature of the Earth: Steps towards Integrated Understanding of Variability and ChangeGlynn HulleyNo ratings yet
- Freivalds' AlgorithmDocument3 pagesFreivalds' AlgorithmLindrit KqikuNo ratings yet
- Radar 2009 A - 1 IntroductionDocument98 pagesRadar 2009 A - 1 IntroductionbgastomoNo ratings yet
- Kidder S. Q. & Haar T. H. - Satellite Meteorology (1995)Document465 pagesKidder S. Q. & Haar T. H. - Satellite Meteorology (1995)celso QueteNo ratings yet
- The Atmosphere: An Introduction To Meteorology, 12: Chapter 6: Air Pressure and WindsDocument42 pagesThe Atmosphere: An Introduction To Meteorology, 12: Chapter 6: Air Pressure and Windscmayorgaga100% (3)
- Comp AeroelasticityDocument28 pagesComp Aeroelasticityபிரபாகரன் ஆறுமுகம்No ratings yet
- The Mediterranean Environment in Ancient HistoryDocument70 pagesThe Mediterranean Environment in Ancient HistoryJordi Teixidor AbelendaNo ratings yet
- FORMULADocument5 pagesFORMULAMehdi KhouadriNo ratings yet
- Makalah Ipa Dasar I Earth and Tata SuryaDocument17 pagesMakalah Ipa Dasar I Earth and Tata SuryaAnil YusufNo ratings yet
- 1-Bioclimatic Landscape Design in Arid ClimateDocument6 pages1-Bioclimatic Landscape Design in Arid ClimatevabsNo ratings yet
- Engineering MathematicsDocument1 pageEngineering MathematicsNymicy100% (1)
- FluidDocument3 pagesFluidthegiver_lawNo ratings yet
- An Introduction To Atmospheric Modeling PDFDocument336 pagesAn Introduction To Atmospheric Modeling PDFyanethsanchezNo ratings yet
- Hydo RepoDocument7 pagesHydo RepoGrs205100% (1)
- Furevik - (Exercise) Atmosphere Ocean DynamicDocument69 pagesFurevik - (Exercise) Atmosphere Ocean Dynamicraiz123No ratings yet
- Eddy Covariance LI-CORDocument345 pagesEddy Covariance LI-CORbiodaviNo ratings yet
- Hagen-Rubens RelationDocument1 pageHagen-Rubens RelationNewtonNo ratings yet
- Fluid Kinematics Lecture: Velocity Fields, Acceleration, and Reynolds Transport TheoremDocument43 pagesFluid Kinematics Lecture: Velocity Fields, Acceleration, and Reynolds Transport TheoremArnold Thamrin van LutteranNo ratings yet
- Matlab IntroDocument145 pagesMatlab IntroAlejandro JRNo ratings yet
- UCLA Astronomy 3 Practice ExamDocument7 pagesUCLA Astronomy 3 Practice ExamSharon XuNo ratings yet
- BeachHazards RipCurrents0712Document4 pagesBeachHazards RipCurrents0712JessicaNo ratings yet
- UDSM Statistics and Probability For Non-MajorsDocument148 pagesUDSM Statistics and Probability For Non-MajorsMaswiNo ratings yet
- Chapter 5Document102 pagesChapter 5antutuNo ratings yet
- Grid Vs Spectral ModelsDocument12 pagesGrid Vs Spectral ModelsAndy BollenbacherNo ratings yet
- Orbital Mechanics 2e ErrataDocument2 pagesOrbital Mechanics 2e Erratarayan_isaacNo ratings yet
- Water 12 02339Document21 pagesWater 12 02339Bikas C. BhattaraiNo ratings yet
- Water: Aquatic Insects and Benthic Diatoms: A History of Biotic Relationships in Freshwater EcosystemsDocument14 pagesWater: Aquatic Insects and Benthic Diatoms: A History of Biotic Relationships in Freshwater EcosystemsBikas C. BhattaraiNo ratings yet
- Science Emission ReductionDocument11 pagesScience Emission Reductionbrayan7uribeNo ratings yet
- Water: Simulation of Water-Use Efficiency of Crops Under Different Irrigation StrategiesDocument16 pagesWater: Simulation of Water-Use Efficiency of Crops Under Different Irrigation StrategiesBikas C. BhattaraiNo ratings yet
- Visualize Climate Data with PythonDocument20 pagesVisualize Climate Data with PythonBikas C. BhattaraiNo ratings yet
- Getting Your Hands-On Climate Data - IntroductionDocument14 pagesGetting Your Hands-On Climate Data - IntroductionBikas C. BhattaraiNo ratings yet
- Surface Hydrology: GEO2010 Spring 2017Document8 pagesSurface Hydrology: GEO2010 Spring 2017Bikas C. BhattaraiNo ratings yet
- GEO 2010 Surface Hydrology Spring 2017 Exercise 1 Date: 2017-01-16Document7 pagesGEO 2010 Surface Hydrology Spring 2017 Exercise 1 Date: 2017-01-16Bikas C. BhattaraiNo ratings yet
- GEO 2010 Surface Hydrology Spring 2017 Exercise 1 Date: 2017-01-16Document7 pagesGEO 2010 Surface Hydrology Spring 2017 Exercise 1 Date: 2017-01-16Bikas C. BhattaraiNo ratings yet
- Solution To Exercise 2: Probability DistributionsDocument10 pagesSolution To Exercise 2: Probability DistributionsBikas C. BhattaraiNo ratings yet
- Exercise 6: Time Series Analysis and Stochastic ModellingDocument18 pagesExercise 6: Time Series Analysis and Stochastic ModellingBikas C. BhattaraiNo ratings yet
- Solution To Exercise 2: Probability DistributionsDocument10 pagesSolution To Exercise 2: Probability DistributionsBikas C. BhattaraiNo ratings yet
- GEO 2010 Surface Hydrology Spring 2017 Exercise 1 Date: 2017-01-16Document7 pagesGEO 2010 Surface Hydrology Spring 2017 Exercise 1 Date: 2017-01-16Bikas C. BhattaraiNo ratings yet
- Linear Regression Analysis of Temperature DataDocument15 pagesLinear Regression Analysis of Temperature DataBikas C. BhattaraiNo ratings yet
- Black Carbon Aerosols Over The Himalayas - Direct and Surface Albedo Forcing - Nair - Tellus BDocument11 pagesBlack Carbon Aerosols Over The Himalayas - Direct and Surface Albedo Forcing - Nair - Tellus BBikas C. BhattaraiNo ratings yet
- Validation of Aqua-MODIS C051 and C006 ODocument14 pagesValidation of Aqua-MODIS C051 and C006 OBikas C. BhattaraiNo ratings yet
- Hydrology D 19 00079 PDFDocument25 pagesHydrology D 19 00079 PDFBikas C. BhattaraiNo ratings yet
- Black Carbon in HimalayasDocument7 pagesBlack Carbon in HimalayasBikas C. BhattaraiNo ratings yet
- Astm D 4417Document4 pagesAstm D 4417Javier Celada0% (1)
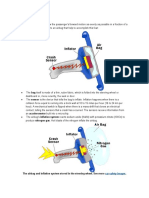
- Airbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreDocument5 pagesAirbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreShivankur HingeNo ratings yet
- Rectangle StabbingDocument49 pagesRectangle StabbingApurba DasNo ratings yet
- Performance Evaluation of Root Crop HarvestersDocument15 pagesPerformance Evaluation of Root Crop HarvestersIJERDNo ratings yet
- Teaching Methods in The PhilippinesDocument2 pagesTeaching Methods in The PhilippinesTonee Marie Gabriel60% (5)
- Portable USB ChargerDocument13 pagesPortable USB ChargerParmar KundanNo ratings yet
- Biokimia - DR - Maehan Hardjo M.biomed PHDDocument159 pagesBiokimia - DR - Maehan Hardjo M.biomed PHDHerryNo ratings yet
- CS6002 1 MS Coursework Year 2012/13Document4 pagesCS6002 1 MS Coursework Year 2012/13duck19000No ratings yet
- Indigo Vision CatalogDocument117 pagesIndigo Vision CatalogWAEL50% (2)
- Too Early! by Anton Pavlovich ChekhovDocument4 pagesToo Early! by Anton Pavlovich Chekhovapi-19787590No ratings yet
- Arnica The Miracle Remedy - Case RecordsDocument4 pagesArnica The Miracle Remedy - Case Recordskaravi schiniasNo ratings yet
- Update 2.9?new Best Sensitivity + Code & Basic Setting Pubg Mobile 2024?gyro On, 60fps, 5 Fingger. - YoutubeDocument1 pageUpdate 2.9?new Best Sensitivity + Code & Basic Setting Pubg Mobile 2024?gyro On, 60fps, 5 Fingger. - Youtubepiusanthony918No ratings yet
- Gec-Art Art Appreciation: Course Code: Course Title: Course DescriptionsDocument14 pagesGec-Art Art Appreciation: Course Code: Course Title: Course Descriptionspoleene de leonNo ratings yet
- MS Excel Word Powerpoint MCQsDocument64 pagesMS Excel Word Powerpoint MCQsNASAR IQBALNo ratings yet
- DriveDebug User ManualDocument80 pagesDriveDebug User ManualFan CharlesNo ratings yet
- Training Report PRASADDocument32 pagesTraining Report PRASADshekharazad_suman85% (13)
- 12 Orpic Safety Rules Managers May 17 RevDocument36 pages12 Orpic Safety Rules Managers May 17 RevGordon Longforgan100% (3)
- Bohemian Flower Face Mask by Maya KuzmanDocument8 pagesBohemian Flower Face Mask by Maya KuzmanDorca MoralesNo ratings yet
- 4-7 The Law of Sines and The Law of Cosines PDFDocument40 pages4-7 The Law of Sines and The Law of Cosines PDFApple Vidal100% (1)
- Panasonic SA-HT878Document82 pagesPanasonic SA-HT878immortalwombatNo ratings yet
- Cooling Tower FundamentalsDocument17 pagesCooling Tower FundamentalsGaurav RathoreNo ratings yet
- Root Cause Analysis: Identifying Factors Behind Patient Safety IncidentsDocument5 pagesRoot Cause Analysis: Identifying Factors Behind Patient Safety IncidentsPrabhas_Das7No ratings yet
- Chapter 08-Borrowing Costs-Tutorial AnswersDocument4 pagesChapter 08-Borrowing Costs-Tutorial AnswersMayomi JayasooriyaNo ratings yet
- Operational Readiness Guide - 2017Document36 pagesOperational Readiness Guide - 2017albertocm18100% (2)
- CopyofCopyofMaldeepSingh Jawanda ResumeDocument2 pagesCopyofCopyofMaldeepSingh Jawanda Resumebob nioNo ratings yet
- IEEE802.11b/g High Power Wireless AP/Bridge Quick Start GuideDocument59 pagesIEEE802.11b/g High Power Wireless AP/Bridge Quick Start GuideonehotminuteNo ratings yet
- Gender Support Plan PDFDocument4 pagesGender Support Plan PDFGender SpectrumNo ratings yet
- Samples For Loanshyd-1Document3 pagesSamples For Loanshyd-1dpkraja100% (1)
- Hierarchical Afaan Oromoo News Text ClassificationDocument11 pagesHierarchical Afaan Oromoo News Text ClassificationendaleNo ratings yet
- Enzyme KineticsDocument13 pagesEnzyme KineticsMohib100% (1)