You might also like
- Stata Treatment-Effects Reference Manual:: Release 16Document325 pagesStata Treatment-Effects Reference Manual:: Release 16DanielaLlanaNo ratings yet
- PanelDocument93 pagesPaneljjanggu100% (1)
- Stochastic Frontier Analysis StataDocument48 pagesStochastic Frontier Analysis StataAnonymous vI4dpAhc100% (2)
- Leica Pegasus MapFactory BRO enDocument4 pagesLeica Pegasus MapFactory BRO enpancaNo ratings yet
- Lecture 7 VAR, VECM and Multivariate CointegrationDocument53 pagesLecture 7 VAR, VECM and Multivariate CointegrationFixque AXNo ratings yet
- Econometrics of Panel Data ModelsDocument34 pagesEconometrics of Panel Data Modelsarmailgm100% (1)
- TS PartIIDocument50 pagesTS PartIIأبوسوار هندسةNo ratings yet
- Between Within Stata AnalysisDocument3 pagesBetween Within Stata AnalysisMaria PappaNo ratings yet
- Robust Statistics For Outlier Detection (Peter J. Rousseeuw and Mia Hubert)Document8 pagesRobust Statistics For Outlier Detection (Peter J. Rousseeuw and Mia Hubert)Robert PetersonNo ratings yet
- Process Hazard Analysis: Faculty of Chemical Engineering Universiti Teknologi MaraDocument30 pagesProcess Hazard Analysis: Faculty of Chemical Engineering Universiti Teknologi MaraSalihin FhooziNo ratings yet
- Probit Analysis for Concentration and TimeDocument6 pagesProbit Analysis for Concentration and TimeM Isyhaduul IslamNo ratings yet
- Multiple Regression MSDocument35 pagesMultiple Regression MSWaqar AhmadNo ratings yet
- STATA TrainingDocument63 pagesSTATA Trainingmarcarth36100% (1)
- Omitted Variables - Monte Carlo StataDocument12 pagesOmitted Variables - Monte Carlo StataGian SoaveNo ratings yet
- Threshold SlidesDocument6 pagesThreshold SlidesoptoergoNo ratings yet
- Structure Project Topics For Projects 2016Document4 pagesStructure Project Topics For Projects 2016Mariu VornicuNo ratings yet
- Application of VAR Model AnalysisDocument22 pagesApplication of VAR Model AnalysisEason SaintNo ratings yet
- 08s Cpe633 Hw2 SolutionDocument4 pages08s Cpe633 Hw2 Solutionram_7860% (1)
- Forecasting Crude Oil Prices Using EviewsDocument5 pagesForecasting Crude Oil Prices Using EviewsNaba Kr MedhiNo ratings yet
- FORECASTING TIME SERIES WITH ARMA AND ARIMA MODELSDocument35 pagesFORECASTING TIME SERIES WITH ARMA AND ARIMA MODELSMochammad Adji FirmansyahNo ratings yet
- Factor Analysis Using SPSS: ExampleDocument14 pagesFactor Analysis Using SPSS: ExampleGovindamal ThangiahNo ratings yet
- Problems MaintenanceDocument15 pagesProblems MaintenanceHajra AamirNo ratings yet
- Lecture 7 VARDocument34 pagesLecture 7 VAREason SaintNo ratings yet
- Econometrics I: Introduction to Models, Methods, and ApplicationsDocument22 pagesEconometrics I: Introduction to Models, Methods, and ApplicationsTrang NguyenNo ratings yet
- Nonlinear Programming and Process OptimizationDocument224 pagesNonlinear Programming and Process OptimizationLina Angarita HerreraNo ratings yet
- Favar PackageDocument2 pagesFavar PackageTrevor ChimombeNo ratings yet
- Proc Arima ProcedureDocument122 pagesProc Arima ProcedureBikash BhandariNo ratings yet
- Application of Smooth Transition Autoregressive (STAR) Models For Exchange RateDocument10 pagesApplication of Smooth Transition Autoregressive (STAR) Models For Exchange Ratedecker4449No ratings yet
- Useful Stata CommandsDocument48 pagesUseful Stata CommandsumerfaridNo ratings yet
- Forecasting Time Series With R - DataikuDocument16 pagesForecasting Time Series With R - DataikuMax GrecoNo ratings yet
- Unbalanced Panel Data PDFDocument51 pagesUnbalanced Panel Data PDFrbmalasaNo ratings yet
- EEA Stata Training ManualDocument85 pagesEEA Stata Training ManualGetachew A. Abegaz100% (2)
- Calculating The Probability of Failure On Demand (PFD) of Complex Structures by Means of Markov ModelsDocument5 pagesCalculating The Probability of Failure On Demand (PFD) of Complex Structures by Means of Markov ModelsfoamtrailerNo ratings yet
- ARDL Model - Hossain Academy Note PDFDocument5 pagesARDL Model - Hossain Academy Note PDFabdulraufhcc100% (1)
- 08s Cpe633 Test1 SolutionDocument3 pages08s Cpe633 Test1 Solutionram_786No ratings yet
- Panel Data Models: Dynamic Panels and Unit RootsDocument20 pagesPanel Data Models: Dynamic Panels and Unit RootsJeremiahOmwoyoNo ratings yet
- Logistic Regression Survival Analysis Kaplan-MeierDocument13 pagesLogistic Regression Survival Analysis Kaplan-MeiertadeurodriguezpNo ratings yet
- Lahore University of Management Sciences ECON 330 - EconometricsDocument3 pagesLahore University of Management Sciences ECON 330 - EconometricsshyasirNo ratings yet
- Remaining Life Evaluation of Coke DrumsDocument15 pagesRemaining Life Evaluation of Coke DrumsRohit KaleNo ratings yet
- Estimating a VAR Model in GRETLDocument9 pagesEstimating a VAR Model in GRETLkaddour7108No ratings yet
- Favero Applied MacroeconometricsDocument292 pagesFavero Applied MacroeconometricsMithilesh KumarNo ratings yet
- An Introduction To Bayesian VAR (BVAR) Models R-EconometricsDocument16 pagesAn Introduction To Bayesian VAR (BVAR) Models R-EconometricseruygurNo ratings yet
- Time Series STATA Manual PDFDocument544 pagesTime Series STATA Manual PDFPrashant PoddarNo ratings yet
- Efficient PHA of Non-Continuous Operating ModesDocument25 pagesEfficient PHA of Non-Continuous Operating ModesShakirNo ratings yet
- 08s Cpe633 Hw1 SolutionDocument3 pages08s Cpe633 Hw1 Solutionram_786No ratings yet
- About The MS Regress PackageDocument28 pagesAbout The MS Regress PackagegliptakNo ratings yet
- Time Series Analysis With R - Part IDocument23 pagesTime Series Analysis With R - Part Ithcm2011No ratings yet
- Microeconometrics Lecture NotesDocument407 pagesMicroeconometrics Lecture NotesburgguNo ratings yet
- Análisis Multivariante Carlos Véliz CapuñayDocument210 pagesAnálisis Multivariante Carlos Véliz CapuñaySergio AquiseNo ratings yet
- Time Series Group AssignmentDocument2 pagesTime Series Group AssignmentLit Jhun Yeang BenjaminNo ratings yet
- PSM in Stata Using TeffectsDocument6 pagesPSM in Stata Using Teffectsjc224No ratings yet
- MFIN 514 Mod 3Document39 pagesMFIN 514 Mod 3Liam FraleighNo ratings yet
- Econometrics Final Exam InsightsDocument7 pagesEconometrics Final Exam InsightsMeliha PalošNo ratings yet
- Marginal Effects for Continuous VariablesDocument12 pagesMarginal Effects for Continuous Variablesjive_gumelaNo ratings yet
- How Can I Do Mediation Analysis With The Sem Command - Stata FAQDocument19 pagesHow Can I Do Mediation Analysis With The Sem Command - Stata FAQIsmaila YusufNo ratings yet
- CH 14 HandoutDocument6 pagesCH 14 HandoutJntNo ratings yet
- Advanced Stata For Linear ModelsDocument11 pagesAdvanced Stata For Linear ModelsmaryNo ratings yet
- Financial Econometrics Tutorial Exercise 4 SolutionsDocument5 pagesFinancial Econometrics Tutorial Exercise 4 SolutionsParidhee ToshniwalNo ratings yet
- InterpretationDocument8 pagesInterpretationvghNo ratings yet
- Is There Room For Forex Interventions Under Inflation Targeting Framework? Evidence From Mexico and TurkeyDocument33 pagesIs There Room For Forex Interventions Under Inflation Targeting Framework? Evidence From Mexico and TurkeyJosé-Manuel Martin CoronadoNo ratings yet
- R Cheat Sheet 3 PDFDocument2 pagesR Cheat Sheet 3 PDFapakuniNo ratings yet
- NBER w15680Document38 pagesNBER w15680José-Manuel Martin CoronadoNo ratings yet
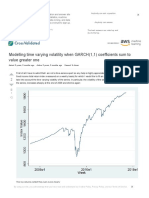
- Maximum Likelihood - Modelling Time Varying Volatility When GARCH (1,1) Coefficients Sum To Value Greater One - Cross ValidatedDocument4 pagesMaximum Likelihood - Modelling Time Varying Volatility When GARCH (1,1) Coefficients Sum To Value Greater One - Cross ValidatedJosé-Manuel Martin CoronadoNo ratings yet
- 7 Types of Classification Algorithms - Analytics India MagazineDocument17 pages7 Types of Classification Algorithms - Analytics India MagazineJosé-Manuel Martin CoronadoNo ratings yet
- 1 Conversion PDFDocument22 pages1 Conversion PDFDaniela MachadoNo ratings yet
- Price CapsDocument133 pagesPrice CapsJosé-Manuel Martin CoronadoNo ratings yet
- Empirical Industrial Organization: A Progress Report: Liran Einav and Jonathan LevinDocument21 pagesEmpirical Industrial Organization: A Progress Report: Liran Einav and Jonathan LevinJosé-Manuel Martin CoronadoNo ratings yet
- BBVA Credit Risk Quantification ModelsDocument2 pagesBBVA Credit Risk Quantification ModelsJosé-Manuel Martin CoronadoNo ratings yet
- Do Older Adults With Parent(s) Alive Experience Higher Psychological Pain and Suicidal Ideation? A Cross-Sectional Study in ChinaDocument11 pagesDo Older Adults With Parent(s) Alive Experience Higher Psychological Pain and Suicidal Ideation? A Cross-Sectional Study in ChinaJosé-Manuel Martin CoronadoNo ratings yet
- Structural Analysis of Competitive Behavior: New Empirical Industrial Organization Methods in MarketingDocument26 pagesStructural Analysis of Competitive Behavior: New Empirical Industrial Organization Methods in MarketingJosé-Manuel Martin CoronadoNo ratings yet
- EViews 5 Users GuideDocument990 pagesEViews 5 Users GuideJosé-Manuel Martin CoronadoNo ratings yet
- Nixon, Measuring Calibration in Deep LearningDocument14 pagesNixon, Measuring Calibration in Deep LearningJosé-Manuel Martin CoronadoNo ratings yet
- w23930 PDFDocument44 pagesw23930 PDFJosé-Manuel Martin CoronadoNo ratings yet
- GIS 14a - Purging Natural Gas Installation Volumes Between 0.03 m3 To 1.0 m3 - Energy Safe VictoriaDocument11 pagesGIS 14a - Purging Natural Gas Installation Volumes Between 0.03 m3 To 1.0 m3 - Energy Safe VictoriaArash FatehnezhadNo ratings yet
- Ryobi 18 Volt Impact Wrench Model Number P261 Repair SheetDocument4 pagesRyobi 18 Volt Impact Wrench Model Number P261 Repair SheetRicardo Ran Pos100% (1)
- Perspective, Secne Design, and Basic AnimationDocument17 pagesPerspective, Secne Design, and Basic AnimationShehnaz ObeidatNo ratings yet
- 6 - StringsDocument19 pages6 - Stringsaljazi mNo ratings yet
- Basic Firefighting LectureDocument88 pagesBasic Firefighting LectureBfp Region Vii SanJoseNo ratings yet
- OXIMATE SDN BHD product list and contact detailsDocument3 pagesOXIMATE SDN BHD product list and contact detailsWANNo ratings yet
- Row Based+vs+Column Based+DatabasesDocument17 pagesRow Based+vs+Column Based+DatabasesbimoNo ratings yet
- C-Zone SDN BHD: WWW - Czone.myDocument2 pagesC-Zone SDN BHD: WWW - Czone.myFirman SyahNo ratings yet
- HPA4 Service ManualDocument7 pagesHPA4 Service ManualMarcelo ArayaNo ratings yet
- Bess-Sm-3q90041-Qams-003 Method of Statement - Cable Termination PDFDocument5 pagesBess-Sm-3q90041-Qams-003 Method of Statement - Cable Termination PDFChristian BulaongNo ratings yet
- Novent Microfluidics: Installation GuideDocument24 pagesNovent Microfluidics: Installation GuidetalebNo ratings yet
- 2. CHUYÊN ĐỀ 2 (LỖI SAI + VIẾT CÂU)Document4 pages2. CHUYÊN ĐỀ 2 (LỖI SAI + VIẾT CÂU)farm 3 chi di0% (1)
- Networks Pre Connection Attacks PDFDocument15 pagesNetworks Pre Connection Attacks PDFaniket kasturiNo ratings yet
- Civil Engineering PG StudiesDocument8 pagesCivil Engineering PG StudiesnitintkattiNo ratings yet
- Name Synopsis Description: Curl (Options) (URL... )Document35 pagesName Synopsis Description: Curl (Options) (URL... )yo goloNo ratings yet
- Luanshya Technical College SCADA Scan IntervalDocument5 pagesLuanshya Technical College SCADA Scan IntervalAlfred K ChilufyaNo ratings yet
- A Colony of Blue-Green Algae Can Power A Computer For Six MonthsDocument4 pagesA Colony of Blue-Green Algae Can Power A Computer For Six MonthsDr Hart IncorporatedNo ratings yet
- Testing and Sampling Parameters for Boiler Water FeedDocument17 pagesTesting and Sampling Parameters for Boiler Water FeedGuruNo ratings yet
- CCFMDocument8 pagesCCFMnagarjunaNo ratings yet
- Specification For 11/0.433 KV Distribution Transformers, Dry Type (Cast Resin), Ground Mounted For Indoor ApplicationsDocument10 pagesSpecification For 11/0.433 KV Distribution Transformers, Dry Type (Cast Resin), Ground Mounted For Indoor ApplicationsIhab Shawkiه8No ratings yet
- AIRPORTS AUTHORITY OF INDIA I CardDocument2 pagesAIRPORTS AUTHORITY OF INDIA I Cardkallul5551350100% (1)
- Lecture - Week - 3 - Software MetricsDocument29 pagesLecture - Week - 3 - Software MetricsManlNo ratings yet
- SUNSTAR - Latest Philippine Community News, Cebuano Stories, Bisaya News and Information - SUNSTARDocument23 pagesSUNSTAR - Latest Philippine Community News, Cebuano Stories, Bisaya News and Information - SUNSTARJOHN LUKE VIANNEYNo ratings yet
- Properties of The Operations On IntegersDocument23 pagesProperties of The Operations On Integersimee marayagNo ratings yet
- Diagrama y Manual de Servicio Genius - swn51 - 1000Document18 pagesDiagrama y Manual de Servicio Genius - swn51 - 1000Asmeri RuizNo ratings yet
- MV SkidDocument2 pagesMV SkidNikolaNo ratings yet
- T Rec L.156 201803 I!!pdf eDocument16 pagesT Rec L.156 201803 I!!pdf eluxofNo ratings yet
- Sharp CD E700 CD E77Document60 pagesSharp CD E700 CD E77Randy LeonNo ratings yet
- CES 2020 Summary: by Frank Egle, I/EZ-I (Slide 1-46), Dr. Harald Altinger I/EF-XS (Slide 47-50)Document50 pagesCES 2020 Summary: by Frank Egle, I/EZ-I (Slide 1-46), Dr. Harald Altinger I/EF-XS (Slide 47-50)mazuedNo ratings yet
- 8051 Atmel DatasheetDocument12 pages8051 Atmel Datasheetpranav_c22100% (3)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 4.5 out of 5 stars4.5/5 (20)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceFrom EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)