You might also like
- ProbabilityDocument552 pagesProbabilitypulkit100% (2)
- Numerical Optimization - Solutions ManualDocument75 pagesNumerical Optimization - Solutions ManualGugo Man73% (11)
- Introduction To The Theory of Functional Differential Equations Methods and Applications Contemporary Mathematics and Its Applications Book Series)Document324 pagesIntroduction To The Theory of Functional Differential Equations Methods and Applications Contemporary Mathematics and Its Applications Book Series)Hanh Nguyen100% (1)
- Finding The NTH Term of SequenceDocument27 pagesFinding The NTH Term of SequenceKartikeya ShuklaNo ratings yet
- UntitledDocument555 pagesUntitledAppleDugarNo ratings yet
- Applied Functional Analysis Applications To Mathematical PhysicsDocument503 pagesApplied Functional Analysis Applications To Mathematical PhysicsDietethique100% (7)
- Cramers Rule 3 by 3 NotesDocument4 pagesCramers Rule 3 by 3 NotesSaherNo ratings yet
- Goldblatt - Topoi, The Categorical Analysis of LogicDocument569 pagesGoldblatt - Topoi, The Categorical Analysis of LogicWilfred Hulsbergen100% (2)
- DSP Lab Manual 5 Semester Electronics and Communication EngineeringDocument147 pagesDSP Lab Manual 5 Semester Electronics and Communication Engineeringrupa_123No ratings yet
- Bergh & Löfström - Interpolation Spaces An IntroductionDocument217 pagesBergh & Löfström - Interpolation Spaces An IntroductionGustavo FigueiredoNo ratings yet
- L 0009605557 PDFDocument30 pagesL 0009605557 PDFNUR AHMAD ABRORINo ratings yet
- Estimation and Control Problems For Stochastic Partial Differential EquationsDocument191 pagesEstimation and Control Problems For Stochastic Partial Differential EquationsLeonardo DanielliNo ratings yet
- Solving Nonlinear Equations using Newton & Quasi-Newton MethodsDocument29 pagesSolving Nonlinear Equations using Newton & Quasi-Newton MethodsMaths HubNo ratings yet
- The Evolution of Isaac Newton's Numerical MethodDocument34 pagesThe Evolution of Isaac Newton's Numerical MethodVarshant DharNo ratings yet
- Numerical Methods For Differential Equations and ApplicationsDocument14 pagesNumerical Methods For Differential Equations and ApplicationsStefanoNo ratings yet
- LRR SpectralDocument78 pagesLRR SpectralGodwin LarryNo ratings yet
- Support Vector Machines Theory and Applications Conference PaperDocument7 pagesSupport Vector Machines Theory and Applications Conference PaperPrince GurajenaNo ratings yet
- Fuzzy Differential Equations With Riemann-Liouville Generalized Fractional Integrable ImpulsesDocument27 pagesFuzzy Differential Equations With Riemann-Liouville Generalized Fractional Integrable ImpulsesHo Nhat NamNo ratings yet
- A Modified Newton Method For Solving Non-Linear Algebraic EquationsDocument10 pagesA Modified Newton Method For Solving Non-Linear Algebraic Equationslu casNo ratings yet
- Lecture3 NonlinearEquations PDFDocument53 pagesLecture3 NonlinearEquations PDFschen_newyorkNo ratings yet
- CoelloCoello1999 Article AComprehensiveSurveyOfEvolutioDocument40 pagesCoelloCoello1999 Article AComprehensiveSurveyOfEvolutioLucasNo ratings yet
- A Method With Inertial Extrapolation Step For Convex Constrained Monotone EquationsDocument25 pagesA Method With Inertial Extrapolation Step For Convex Constrained Monotone EquationsCarlos TavaresNo ratings yet
- Mathematics: On A Bi-Parametric Family of Fourth Order Composite Newton-Jarratt Methods For Nonlinear SystemsDocument27 pagesMathematics: On A Bi-Parametric Family of Fourth Order Composite Newton-Jarratt Methods For Nonlinear SystemsAlberto Magreñán RuizNo ratings yet
- Homogeneization Periodic Guy Bonnet IJSS 2016Document47 pagesHomogeneization Periodic Guy Bonnet IJSS 2016auslenderNo ratings yet
- Unit 4stretching TechniqueDocument9 pagesUnit 4stretching TechniqueYuvraj Singh RanaNo ratings yet
- Mandelstam-Papalexi - Report On Recent Research On Nonlinear Oscillations - 1935Document54 pagesMandelstam-Papalexi - Report On Recent Research On Nonlinear Oscillations - 1935JohnNo ratings yet
- A Modified Newton's Method For Solving Nonlinear Programing ProblemsDocument15 pagesA Modified Newton's Method For Solving Nonlinear Programing Problemsjhon jairo portillaNo ratings yet
- Uncertainty Principle For Measurable Sets and SignDocument11 pagesUncertainty Principle For Measurable Sets and Signayoub ayoubbNo ratings yet
- An Embedded 6 (5) Pair of Explicit Runge-Kutta Method For Periodic IVPsDocument18 pagesAn Embedded 6 (5) Pair of Explicit Runge-Kutta Method For Periodic IVPsMomentod'InerziaNo ratings yet
- Solving Initial Value Problem Using Runge-Kutta 6 TH Order MethodDocument10 pagesSolving Initial Value Problem Using Runge-Kutta 6 TH Order Methodhusmech80_339926141No ratings yet
- Design of Experiment Methods in Manufacturing: Basics and Practical ApplicationsDocument55 pagesDesign of Experiment Methods in Manufacturing: Basics and Practical ApplicationsMeditation ChannelNo ratings yet
- Seasonality Time-SeriesDocument33 pagesSeasonality Time-SeriesHaNo ratings yet
- Review of Linear Systems T Kailath 1980Document3 pagesReview of Linear Systems T Kailath 1980alflorezveNo ratings yet
- On The Convergence of Derivative-Free Methods For Unconstrained Optimization - Conn, Scheinberg, Toin (1997)Document26 pagesOn The Convergence of Derivative-Free Methods For Unconstrained Optimization - Conn, Scheinberg, Toin (1997)Emerson ButynNo ratings yet
- 6.c. MAT498-ProjectBachelors. Differential.Document42 pages6.c. MAT498-ProjectBachelors. Differential.Cindy NoveriaaNo ratings yet
- Overview of Some Solved NP-complete Problems in Graph TheoryDocument11 pagesOverview of Some Solved NP-complete Problems in Graph TheoryAndika Dwi NugrahaNo ratings yet
- 4 FEM - Lect2Document113 pages4 FEM - Lect2sandeepNo ratings yet
- Fyp CorrectionDocument53 pagesFyp Correction2021826386No ratings yet
- Non-Derivative Optimization: Mathematics or HeuristicsDocument52 pagesNon-Derivative Optimization: Mathematics or HeuristicsEdwin Quispe CondoriNo ratings yet
- An Introduction To Semilinear Evolution Equations Thierry Cazenave Alain Haraux Yvan Martel PDFDocument198 pagesAn Introduction To Semilinear Evolution Equations Thierry Cazenave Alain Haraux Yvan Martel PDFCristobal Valenzuela MusuraNo ratings yet
- CIRRELT-2014-64 (1)Document30 pagesCIRRELT-2014-64 (1)Basheer W. ShaheenNo ratings yet
- Optimal Design of Geometrically Nonlinear Structures Using Topology OptimizationDocument12 pagesOptimal Design of Geometrically Nonlinear Structures Using Topology OptimizationErkan SahinNo ratings yet
- Bookabstracts FinalDocument13 pagesBookabstracts Finalapi-240446772No ratings yet
- A Bayesian Approach For Multiple Response SurfaceDocument21 pagesA Bayesian Approach For Multiple Response SurfaceAngel GarciaNo ratings yet
- Pheromone UpdateDocument16 pagesPheromone UpdateSrijan SehgalNo ratings yet
- Gourgoulhon. 3+1 Formalism PDFDocument303 pagesGourgoulhon. 3+1 Formalism PDFDavid PrietoNo ratings yet
- RK4Document18 pagesRK4Mohammed AbbasNo ratings yet
- Entropy and Information in A Fractional Order Model of Anomalous DiffusionDocument6 pagesEntropy and Information in A Fractional Order Model of Anomalous DiffusionqbpzqczpNo ratings yet
- Springer Studia Logica: An International Journal For Symbolic LogicDocument27 pagesSpringer Studia Logica: An International Journal For Symbolic LogicPandu DoradlaNo ratings yet
- CV: Sergei V. KozyrevDocument5 pagesCV: Sergei V. KozyrevLuis MigueloNo ratings yet
- The Finite Element Methods - Wiley Encyclopedia of Computer Science and EngineeringDocument13 pagesThe Finite Element Methods - Wiley Encyclopedia of Computer Science and Engineeringrosa alacoteNo ratings yet
- Fourier Analysis and Wave Packets: Project PHYSNET Physics Bldg. Michigan State University East Lansing, MIDocument4 pagesFourier Analysis and Wave Packets: Project PHYSNET Physics Bldg. Michigan State University East Lansing, MIEpic WinNo ratings yet
- Conditional stability for backward parabolic operators with Osgood continuous coefficientsDocument33 pagesConditional stability for backward parabolic operators with Osgood continuous coefficientsVioleta RuizNo ratings yet
- Handbook of Research On Machine Learning Applications and TrendsDocument34 pagesHandbook of Research On Machine Learning Applications and TrendsAbdelkrim KefifNo ratings yet
- Connected Set Cover Problem and Its Applications: June 2006Document13 pagesConnected Set Cover Problem and Its Applications: June 2006Danna OsorioNo ratings yet
- Moments and Central Limit Theorems For Some Multivariate Poisson FunctionalsDocument19 pagesMoments and Central Limit Theorems For Some Multivariate Poisson FunctionalsAbhishek TilvaNo ratings yet
- Evolutionary Multi-Objective Optimization in Materials ScienceDocument21 pagesEvolutionary Multi-Objective Optimization in Materials SciencevadivelbookNo ratings yet
- An Introduction To Statistical Learning From A Reg PDFDocument25 pagesAn Introduction To Statistical Learning From A Reg PDFJawadNo ratings yet
- Survey of Direct Transcription For Low-Thrust SpacDocument17 pagesSurvey of Direct Transcription For Low-Thrust SpacX YNo ratings yet
- Functional Analysis: March 2010Document99 pagesFunctional Analysis: March 2010VarobNo ratings yet
- 07SQUJS-AK FinalMATH070213 PDFDocument12 pages07SQUJS-AK FinalMATH070213 PDFMistlemagicNo ratings yet
- A Brief Description of The Levenberg-Marquardt AlgDocument7 pagesA Brief Description of The Levenberg-Marquardt AlgMistlemagicNo ratings yet
- Channel Boosted CNN Using Transfer Learning Boosts Churn PredictionDocument24 pagesChannel Boosted CNN Using Transfer Learning Boosts Churn PredictionMistlemagicNo ratings yet
- CBAM: Lightweight Convolutional Block Attention ModuleDocument17 pagesCBAM: Lightweight Convolutional Block Attention ModuleMistlemagicNo ratings yet
- Concurrent Spatial and Channel Squeeze & Excitation' in Fully Convolutional NetworksDocument8 pagesConcurrent Spatial and Channel Squeeze & Excitation' in Fully Convolutional NetworksMistlemagicNo ratings yet
- Best Practices For Convolutional Neural Networks ADocument7 pagesBest Practices For Convolutional Neural Networks AMistlemagicNo ratings yet
- Deeplearningbfci 170626220653Document59 pagesDeeplearningbfci 170626220653asfNo ratings yet
- Applications of The Conjugate Gradient Method in oDocument10 pagesApplications of The Conjugate Gradient Method in oMistlemagicNo ratings yet
- Learning Transferable Architectures For Scalable Image RecognitionDocument14 pagesLearning Transferable Architectures For Scalable Image RecognitionMistlemagicNo ratings yet
- Transfer learning using VGG-16 for image classificationDocument9 pagesTransfer learning using VGG-16 for image classificationMistlemagicNo ratings yet
- Squeeze-and-Excitation NetworksDocument13 pagesSqueeze-and-Excitation NetworksMistlemagicNo ratings yet
- Competitive Inner-Imaging Squeeze and Excitation for Residual NetworksDocument17 pagesCompetitive Inner-Imaging Squeeze and Excitation for Residual NetworksMistlemagicNo ratings yet
- Performance Analysis of NASNet OnDocument26 pagesPerformance Analysis of NASNet OnMistlemagicNo ratings yet
- Evaluation of CNN Alexnet and GoogleNet For FruitDocument8 pagesEvaluation of CNN Alexnet and GoogleNet For FruitMistlemagicNo ratings yet
- Identity Mappings in Deep Residual Networks: Resnet-1k-LayersDocument15 pagesIdentity Mappings in Deep Residual Networks: Resnet-1k-LayersSheethal ThampiNo ratings yet
- Very Deep Convolutional Networks For Large-Scale Image RecognitionDocument14 pagesVery Deep Convolutional Networks For Large-Scale Image Recognitionamadeo magnusNo ratings yet
- Squeeze-and-Excitation NetworksDocument13 pagesSqueeze-and-Excitation NetworksMistlemagicNo ratings yet
- CBAM: Convolutional Block Attention ModuleDocument17 pagesCBAM: Convolutional Block Attention ModuleMistlemagicNo ratings yet
- FractalNet Ultra-Deep Neural Networks Without ResidualsDocument11 pagesFractalNet Ultra-Deep Neural Networks Without ResidualsMistlemagicNo ratings yet
- A Survey of The Recent Architectures of Deep Convolutional Neural NetworksDocument70 pagesA Survey of The Recent Architectures of Deep Convolutional Neural NetworksmainakroniNo ratings yet
- UNetDocument8 pagesUNetPawełGolińskiNo ratings yet
- Polynet: A Pursuit of Structural Diversity in Very Deep NetworksDocument9 pagesPolynet: A Pursuit of Structural Diversity in Very Deep NetworksMistlemagicNo ratings yet
- Residual Attention Network For Image ClassificationDocument9 pagesResidual Attention Network For Image ClassificationMistlemagicNo ratings yet
- Densenet PDFDocument9 pagesDensenet PDFhacheemasterNo ratings yet
- UNetDocument8 pagesUNetPawełGolińskiNo ratings yet
- Polynet: A Pursuit of Structural Diversity in Very Deep NetworksDocument9 pagesPolynet: A Pursuit of Structural Diversity in Very Deep NetworksMistlemagicNo ratings yet
- Wide Residual Networks PDFDocument15 pagesWide Residual Networks PDFMistlemagicNo ratings yet
- Deep ResNetDocument9 pagesDeep ResNetAvanish SinghNo ratings yet
- Highway Networks PDFDocument6 pagesHighway Networks PDFApurvaNo ratings yet
- Plane (Geometry) - WikipediaDocument35 pagesPlane (Geometry) - WikipediaNaniNo ratings yet
- CosineDocument10 pagesCosineSohaib AslamNo ratings yet
- Rational Numbers ExplainedDocument74 pagesRational Numbers ExplainedBestowal Infotechs 2018No ratings yet
- Math 1022 - Beginning of Semester ReviewDocument2 pagesMath 1022 - Beginning of Semester ReviewRashid DavisNo ratings yet
- Partial Differential EquationsDocument69 pagesPartial Differential EquationsNitish DebbarmaNo ratings yet
- Sequence and Progression DPPDocument11 pagesSequence and Progression DPPMohini DeviNo ratings yet
- A General Check Digit System Based On Finite GroupsDocument15 pagesA General Check Digit System Based On Finite GroupsMarcel TrindadeNo ratings yet
- Newton Raphson, Secant and Multiple RootsDocument44 pagesNewton Raphson, Secant and Multiple RootsGeorge PrimatoNo ratings yet
- Grade 8 Mathematics Quarter 1Document10 pagesGrade 8 Mathematics Quarter 1Jan MaratasNo ratings yet
- Dan Hamilton - Advanced Integration (2002)Document126 pagesDan Hamilton - Advanced Integration (2002)bersamamembangunegeriNo ratings yet
- Cee 101 Sim PDFDocument135 pagesCee 101 Sim PDFNovelyn AppillanesNo ratings yet
- Assignment Laplace TransformDocument2 pagesAssignment Laplace TransformSatvik YelluriNo ratings yet
- Trig Exam 2 Review F07Document6 pagesTrig Exam 2 Review F07Rodion Romanovich RaskolnikovNo ratings yet
- W8 - Laplace Transform (Part 1)Document46 pagesW8 - Laplace Transform (Part 1)HermyraJ RobertNo ratings yet
- Numerical AnalysisDocument86 pagesNumerical AnalysisJaggy HunkNo ratings yet
- Pythagoras PDFDocument7 pagesPythagoras PDFradulescNo ratings yet
- Math 1 Week 5 Frequently Asked Questions PDFDocument3 pagesMath 1 Week 5 Frequently Asked Questions PDFGirindhra A NairNo ratings yet
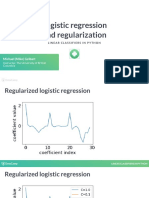
- Logistic Regression and Regularization: Michael (Mike) GelbartDocument19 pagesLogistic Regression and Regularization: Michael (Mike) GelbartNourheneMbarekNo ratings yet
- Problem Set 3 ECO 501Document1 pageProblem Set 3 ECO 501hsalibha7290No ratings yet
- Section 1: Roots and Coefficients: Edexcel AS Further Maths Roots of PolynomialsDocument3 pagesSection 1: Roots and Coefficients: Edexcel AS Further Maths Roots of PolynomialsChung Man HoNo ratings yet
- Metric SpaceDocument36 pagesMetric SpaceABHINAV SIVADASNo ratings yet
- NumericalMethods Part1Document321 pagesNumericalMethods Part1محمد العراقيNo ratings yet
- Rwanda University Module on General and Applied MathematicsDocument166 pagesRwanda University Module on General and Applied MathematicsMasengesho ishimwe PatienceNo ratings yet
- Tugas 2 ArdyllaDocument7 pagesTugas 2 ArdyllaHeri SutiknoNo ratings yet