You might also like
- 2015 Midterm SolutionsDocument7 pages2015 Midterm SolutionsEdith Kua100% (1)
- Shell Plate Guide for Ship DesignersDocument45 pagesShell Plate Guide for Ship DesignersRed Ignacio100% (6)
- SMMD: Normal Distribution ProblemsDocument2 pagesSMMD: Normal Distribution ProblemsSravya Sri0% (10)
- A First Course in Quality EngineeringDocument627 pagesA First Course in Quality EngineeringOmar Alas100% (5)
- SHS Core - Statistics and Probability CGDocument11 pagesSHS Core - Statistics and Probability CGCarol Zamora100% (1)
- Chapter 3 Sampling and Sampling DistributionDocument87 pagesChapter 3 Sampling and Sampling DistributionJames Casison100% (1)
- C07 Fracture Model Generation 2010Document23 pagesC07 Fracture Model Generation 2010Anonymous 4hvWNxu9VNo ratings yet
- Chapter 4Document68 pagesChapter 4Nhatty WeroNo ratings yet
- Measurement Error Models: Frisch Bounds and Attenuation BiasDocument79 pagesMeasurement Error Models: Frisch Bounds and Attenuation BiasTandis AsadiNo ratings yet
- Extensions of The Two-Variable Linear Regression Model: TrueDocument13 pagesExtensions of The Two-Variable Linear Regression Model: TrueshrutiNo ratings yet
- Emet2007 NotesDocument6 pagesEmet2007 NoteskowletNo ratings yet
- Aitken' GLSDocument7 pagesAitken' GLSwlcvorevaNo ratings yet
- Econometrics (EM2008) Specification Error in The The K-Variable ModelDocument31 pagesEconometrics (EM2008) Specification Error in The The K-Variable ModelSelMarie Nutelliina GomezNo ratings yet
- 2019 Moderation SEM AsparouhovDocument46 pages2019 Moderation SEM AsparouhovUsman BaigNo ratings yet
- Heteroskedasticity Tests and GLS EstimatorsDocument21 pagesHeteroskedasticity Tests and GLS EstimatorsnovicasupicnsNo ratings yet
- The Uncertainty of A Result From A Linear CalibrationDocument14 pagesThe Uncertainty of A Result From A Linear CalibrationudsaigakfsNo ratings yet
- 07-BA215Document16 pages07-BA215AlbertoNo ratings yet
- Latent Variable Interactions - Standardization of Random VariablesDocument13 pagesLatent Variable Interactions - Standardization of Random VariablesAntonio Pineda DominguezNo ratings yet
- EconometricsDocument25 pagesEconometricsLynda Mega SaputryNo ratings yet
- 6 Dealing With Model Assumption Violations: 6.1 TransformationsDocument17 pages6 Dealing With Model Assumption Violations: 6.1 TransformationsVikas NehraNo ratings yet
- 7 Multiple Regression 3Document12 pages7 Multiple Regression 3Gladys Gladys MakNo ratings yet
- The Uncertainty of A Result From A Linear CalibrationDocument13 pagesThe Uncertainty of A Result From A Linear Calibrationfra80602No ratings yet
- Classical LinearReg 000Document41 pagesClassical LinearReg 000Umair AyazNo ratings yet
- Econometrics - Review Sheet ' (Main Concepts)Document5 pagesEconometrics - Review Sheet ' (Main Concepts)Choco CheapNo ratings yet
- Lecture Series 1 Linear Random and Fixed Effect Models and Their (Less) Recent ExtensionsDocument62 pagesLecture Series 1 Linear Random and Fixed Effect Models and Their (Less) Recent ExtensionsDaniel Bogiatzis GibbonsNo ratings yet
- Basic Eco No Metrics - GujaratiDocument48 pagesBasic Eco No Metrics - GujaratiFaizan Raza50% (2)
- Published Paper ProjectDocument8 pagesPublished Paper ProjectModupeNo ratings yet
- 1 Causality: POLS571 - Longitudinal Data Analysis September 25, 2001Document6 pages1 Causality: POLS571 - Longitudinal Data Analysis September 25, 2001vignesh87No ratings yet
- Ky FanDocument14 pagesKy FanhungkgNo ratings yet
- 10 Dichotomous or Binary ResponsesDocument74 pages10 Dichotomous or Binary ResponsesEdwin Johny Asnate SalazarNo ratings yet
- 5.04 Principles of Inorganic Chemistry Ii : Mit OpencoursewareDocument8 pages5.04 Principles of Inorganic Chemistry Ii : Mit Opencoursewaresanskarid94No ratings yet
- Artículo - Introduction To Symmetry Methods (P.E. Hydon)Document20 pagesArtículo - Introduction To Symmetry Methods (P.E. Hydon)Pepi MorenoNo ratings yet
- Econometrics ch11Document44 pagesEconometrics ch113rlangNo ratings yet
- 04 Violation of Assumptions AllDocument24 pages04 Violation of Assumptions AllFasiko AsmaroNo ratings yet
- Econometria HeteroelasticidadDocument4 pagesEconometria Heteroelasticidadgorell7No ratings yet
- (Royston P.) A Parametric Model For Ordinal ResponDocument15 pages(Royston P.) A Parametric Model For Ordinal ResponLiliana ForzaniNo ratings yet
- On Some Equivalence Problems For Differential EquationsDocument13 pagesOn Some Equivalence Problems For Differential EquationsPanagiot LoukopoulosNo ratings yet
- ch13 AnsDocument10 pagesch13 AnsTân Dương100% (1)
- Bifurcation Theory Wo ParametersDocument15 pagesBifurcation Theory Wo ParametersJohn StarrettNo ratings yet
- Fixed and Random Model Linear Gndu2020 PDFDocument18 pagesFixed and Random Model Linear Gndu2020 PDFGulshan SharmaNo ratings yet
- 03 - Mich - Solutions To Problem Set 1 - Ao319Document13 pages03 - Mich - Solutions To Problem Set 1 - Ao319albertwing1010No ratings yet
- MIT14 382S17 Lec7Document25 pagesMIT14 382S17 Lec7jarod_kyleNo ratings yet
- Classical Assumptions and HeteroscedasticityDocument32 pagesClassical Assumptions and HeteroscedasticityabdishakurNo ratings yet
- Catic at All PaperDocument13 pagesCatic at All PaperKrzyszto FPNo ratings yet
- Assumption Checking On Linear RegressionDocument65 pagesAssumption Checking On Linear RegressionJohn San JuanNo ratings yet
- econ 335 wooldridge ch 8 heteroskedasticityDocument23 pagesecon 335 wooldridge ch 8 heteroskedasticityminhly12104No ratings yet
- Fixed vs. Random Effects Panel Data Models: Revisiting The Omitted Latent Variables and Individual Heterogeneity ArgumentsDocument20 pagesFixed vs. Random Effects Panel Data Models: Revisiting The Omitted Latent Variables and Individual Heterogeneity ArgumentsJoshua PryorNo ratings yet
- Ecf230 FPD 9 2018 2Document44 pagesEcf230 FPD 9 2018 2George ChuluNo ratings yet
- Ratio DistributionDocument5 pagesRatio DistributionVlk WldNo ratings yet
- The Generalized Variogram 2343Document61 pagesThe Generalized Variogram 2343Andres Alejandro Molina AlvarezNo ratings yet
- Multiple imputation using generalized additive modelsDocument27 pagesMultiple imputation using generalized additive modelseduardoNo ratings yet
- Spatial Econometrics 3Document34 pagesSpatial Econometrics 3Ahmad Aulia Bahrun AmieqNo ratings yet
- Statistical Estimations in Enzyme Kinetics: InvestigationDocument9 pagesStatistical Estimations in Enzyme Kinetics: Investigationhaddig8No ratings yet
- Generalized Least Squares TheoryDocument32 pagesGeneralized Least Squares TheoryAnonymous tsTtieMHDNo ratings yet
- Gauss-Markov TheoremDocument5 pagesGauss-Markov Theoremalanpicard2303No ratings yet
- Second-Order Nonlinear Least Squares Estimation: Liqun WangDocument18 pagesSecond-Order Nonlinear Least Squares Estimation: Liqun WangJyoti GargNo ratings yet
- Ssss PDFDocument50 pagesSsss PDFbitew yirgaNo ratings yet
- Chapter 2: Causal and Noncausal Models: Advanced Econometrics 1Document31 pagesChapter 2: Causal and Noncausal Models: Advanced Econometrics 1Dana7117No ratings yet
- Testing Dynamic Econometric ModelsDocument6 pagesTesting Dynamic Econometric ModelsMaria RoaNo ratings yet
- A Stepwise Approach For High-Dimensional Gaussian Graphical ModelsDocument27 pagesA Stepwise Approach For High-Dimensional Gaussian Graphical ModelsivanmarceNo ratings yet
- Vvedensky D.-Group Theory, Problems and Solutions (2005)Document94 pagesVvedensky D.-Group Theory, Problems and Solutions (2005)egmont7No ratings yet
- GLS TheoryDocument34 pagesGLS TheoryHelmi IswatiNo ratings yet
- Geographically Weighted Regression: Martin Charlton A Stewart FotheringhamDocument17 pagesGeographically Weighted Regression: Martin Charlton A Stewart FotheringhamAgus Salim ArsyadNo ratings yet
- Simple Algebras, Base Change, and the Advanced Theory of the Trace Formula. (AM-120), Volume 120From EverandSimple Algebras, Base Change, and the Advanced Theory of the Trace Formula. (AM-120), Volume 120No ratings yet
- The Development of Debt Markets in Malaysia: BIS Papers No 11Document4 pagesThe Development of Debt Markets in Malaysia: BIS Papers No 11Aditya Agung SatrioNo ratings yet
- Predicting Financial Distress of CompaniesDocument54 pagesPredicting Financial Distress of CompaniesIon BurleaNo ratings yet
- How We Rate Nonfinancial Corporate Entities How We Rate Nonfinancial Corporate EntitiesDocument9 pagesHow We Rate Nonfinancial Corporate Entities How We Rate Nonfinancial Corporate EntitiesAditya Agung SatrioNo ratings yet
- CN, HK, ID, JP, KR, MY, PH, SG, TH, VN 1997-2019 Quarterly Updates Dec-2019 MarketDocument6 pagesCN, HK, ID, JP, KR, MY, PH, SG, TH, VN 1997-2019 Quarterly Updates Dec-2019 MarketAditya Agung SatrioNo ratings yet
- Distressed Firm and Bankruptcy Prediction in An International Context: A Review and Empirical Analysis of Altman's Z-Score ModelDocument48 pagesDistressed Firm and Bankruptcy Prediction in An International Context: A Review and Empirical Analysis of Altman's Z-Score ModelAditya Agung SatrioNo ratings yet
- Methodology: Industry Risk Methodology: Industry Risk: General Criteria: General CriteriaDocument15 pagesMethodology: Industry Risk Methodology: Industry Risk: General Criteria: General CriteriaAditya Agung SatrioNo ratings yet
- Altman 1968Document21 pagesAltman 1968PALASH DHAKARNo ratings yet
- Soal CH 6 Pondah - SoritaDocument8 pagesSoal CH 6 Pondah - SoritaAditya Agung SatrioNo ratings yet
- Bab III Buku Bu IinDocument14 pagesBab III Buku Bu IinAditya Agung SatrioNo ratings yet
- BAb X Buku Bu IInDocument16 pagesBAb X Buku Bu IInAditya Agung SatrioNo ratings yet
- Bab II Buku Bu IinDocument17 pagesBab II Buku Bu IinAditya Agung SatrioNo ratings yet
- BAb V Buku Bu IInDocument6 pagesBAb V Buku Bu IInAditya Agung SatrioNo ratings yet
- Soal Quiz Obligasi Plasma + SellDocument8 pagesSoal Quiz Obligasi Plasma + SellAditya Agung SatrioNo ratings yet
- Chapter 7 Up StreamDocument14 pagesChapter 7 Up StreamAditya Agung SatrioNo ratings yet
- DFD Example 1 Car InsuranceDocument1 pageDFD Example 1 Car InsuranceJamesBjerreNo ratings yet
- True-Or-False - Chapter10 To Chapter20Document11 pagesTrue-Or-False - Chapter10 To Chapter20mymonkeyNo ratings yet
- Account P S at Book Value S at Fair ValueDocument7 pagesAccount P S at Book Value S at Fair ValueAditya Agung SatrioNo ratings yet
- Audit Trail 7BDocument8 pagesAudit Trail 7BAditya Agung SatrioNo ratings yet
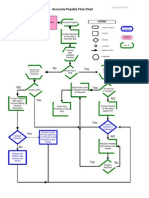
- AP Process FlowDocument1 pageAP Process FlowhoneymandiyanNo ratings yet
- Soal Quiz AdvanceDocument18 pagesSoal Quiz AdvanceAditya Agung SatrioNo ratings yet
- MV Guide People InjuredDocument20 pagesMV Guide People InjuredAditya Agung SatrioNo ratings yet
- Multiple Choice - Chapter10 To Chapter20Document22 pagesMultiple Choice - Chapter10 To Chapter20Aditya Agung SatrioNo ratings yet
- Essay - Chapter10 To Chapter20Document11 pagesEssay - Chapter10 To Chapter20Aditya Agung SatrioNo ratings yet
- 12a. Farooq AbdelBari (2015) - Earnings Management Behaviour of Shariah-Compliant FirmsDocument19 pages12a. Farooq AbdelBari (2015) - Earnings Management Behaviour of Shariah-Compliant FirmsAditya Agung SatrioNo ratings yet
- 9709 s04 QP 7Document4 pages9709 s04 QP 7tess_15No ratings yet
- Probability DistributionDocument32 pagesProbability DistributionUrieNo ratings yet
- Central Limit TheoremDocument16 pagesCentral Limit TheoremkernelexploitNo ratings yet
- Risk Assessment and Pooling - Book 2Document21 pagesRisk Assessment and Pooling - Book 2Ahmed El KhateebNo ratings yet
- 3Document392 pages3Daniel CorreaNo ratings yet
- Linear Transformations If Y Ax + B, Then y A X+B and SDocument2 pagesLinear Transformations If Y Ax + B, Then y A X+B and SmichaelNo ratings yet
- CH-5,6,7,8 and 9Document87 pagesCH-5,6,7,8 and 9Hirpha FayisaNo ratings yet
- Liq Handbook 51-6009 Conductance Data For Commonly Used Chemicals 199408Document36 pagesLiq Handbook 51-6009 Conductance Data For Commonly Used Chemicals 199408Dipmalya BasakNo ratings yet
- Design Considerations for Ultrasonic Signals AcquisitionDocument6 pagesDesign Considerations for Ultrasonic Signals AcquisitionDaiana Correia de LucenaNo ratings yet
- Engineering Seismology Homework: Tripartite Response SpectrumDocument32 pagesEngineering Seismology Homework: Tripartite Response SpectrumNonamex Nonamex NonamexNo ratings yet
- Normal Distribution GuideDocument24 pagesNormal Distribution Guideaybi pearlNo ratings yet
- ps7 SolDocument7 pagesps7 SoljeankoplerNo ratings yet
- 06 Chapter 6Document35 pages06 Chapter 6Vince HernandezNo ratings yet
- Fatigue Reability Ship StructuresDocument303 pagesFatigue Reability Ship StructuresJorge CiprianoNo ratings yet
- Kill MeDocument23 pagesKill MeEmilyNo ratings yet
- Inventory Policy DecisionsDocument28 pagesInventory Policy DecisionsAbhishek PadhyeNo ratings yet
- Z Statistic - Wald Test For Logistic Regression - Cross ValidatedDocument3 pagesZ Statistic - Wald Test For Logistic Regression - Cross ValidatedAdityaNo ratings yet
- Stats 2B03 Test #1 (Version 4) October 26th, 2009Document7 pagesStats 2B03 Test #1 (Version 4) October 26th, 2009examkillerNo ratings yet
- Theoretical Comparisons of Average Normalized GainDocument7 pagesTheoretical Comparisons of Average Normalized GainHikmah YantiNo ratings yet
- Heip, C. & Al. (1998) - Indices of Diversity and Evenness.Document27 pagesHeip, C. & Al. (1998) - Indices of Diversity and Evenness.Carlos Enrique Sánchez OcharanNo ratings yet
- Sampling Run of Mine-MillDocument8 pagesSampling Run of Mine-MillJimmy TorresNo ratings yet
- Important Issues in Tolerance Design of Mechanical Assemblies. Part 1: Tolerance AnalysisDocument23 pagesImportant Issues in Tolerance Design of Mechanical Assemblies. Part 1: Tolerance Analysissai mohanNo ratings yet
- A New Approach to Surface Crown Pillar DesignDocument9 pagesA New Approach to Surface Crown Pillar DesignSANTIAGO NAVIA VÁSQUEZNo ratings yet
- Normal Distribution 2Document33 pagesNormal Distribution 2NIXONNo ratings yet