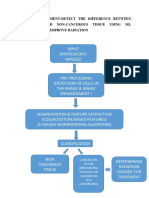
You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Sugar Free Shopping ListDocument4 pagesSugar Free Shopping Listhsquiers100% (3)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- OB 2.5 Intrapartum AssessmentDocument9 pagesOB 2.5 Intrapartum AssessmentisahNo ratings yet
- Internal Audit Ratings GuideDocument19 pagesInternal Audit Ratings Guidesanranist2100% (3)
- Position Paper TopicsDocument2 pagesPosition Paper TopicskinodecuirNo ratings yet
- 28 CryptorchidismDocument23 pages28 CryptorchidismFaisal Ibn MushtaqNo ratings yet
- Stock Market Analysis Using Supervised Machine LearningDocument3 pagesStock Market Analysis Using Supervised Machine LearningKeerthi GuruNo ratings yet
- Detection of Faults in Flying Wireless SensorDocument3 pagesDetection of Faults in Flying Wireless SensorKeerthi GuruNo ratings yet
- Neighbor Based Cluster Location Aware Routing For Maximum Packet Delivery in WSNDocument18 pagesNeighbor Based Cluster Location Aware Routing For Maximum Packet Delivery in WSNKeerthi GuruNo ratings yet
- Improved Fault Diagnosis in Wireless Sensor Networks Using Deep Learning TechniqueDocument4 pagesImproved Fault Diagnosis in Wireless Sensor Networks Using Deep Learning TechniqueKeerthi GuruNo ratings yet
- Crude Oil Price Forecasting Using ARIMA ModelDocument3 pagesCrude Oil Price Forecasting Using ARIMA ModelKeerthi GuruNo ratings yet
- Predicting Fake Online Reviews Using Machine LearningDocument5 pagesPredicting Fake Online Reviews Using Machine LearningKeerthi GuruNo ratings yet
- Kiruthiga - Australian PatentDocument2 pagesKiruthiga - Australian PatentKeerthi GuruNo ratings yet
- Survey On The Localization With Secured Routing in WSNDocument7 pagesSurvey On The Localization With Secured Routing in WSNKeerthi GuruNo ratings yet
- An Adaptive Signal Strength Based Localization Approach For Wireless Sensor NetworksDocument10 pagesAn Adaptive Signal Strength Based Localization Approach For Wireless Sensor NetworksKeerthi GuruNo ratings yet
- Reducing Energy Consumption in Wireless Sensor NetworksDocument6 pagesReducing Energy Consumption in Wireless Sensor NetworksKeerthi GuruNo ratings yet
- Multi Criteria Architecture For Wireless Sensor NetworksDocument5 pagesMulti Criteria Architecture For Wireless Sensor NetworksKeerthi GuruNo ratings yet
- Session PlanDocument2 pagesSession PlanKeerthi GuruNo ratings yet
- Reducing Energy Consumption in Wireless Sensor NetworksDocument6 pagesReducing Energy Consumption in Wireless Sensor NetworksKeerthi GuruNo ratings yet
- AbstractDocument1 pageAbstractKeerthi GuruNo ratings yet
- Che ADocument3 pagesChe AKeerthi GuruNo ratings yet
- Che ADocument3 pagesChe AKeerthi GuruNo ratings yet
- C PRGM Lab PrefaceDocument1 pageC PRGM Lab PrefaceKeerthi GuruNo ratings yet
- MATHSBDocument2 pagesMATHSBKeerthi GuruNo ratings yet
- Survey On The Localization With Secured Routing in WSNDocument7 pagesSurvey On The Localization With Secured Routing in WSNKeerthi GuruNo ratings yet
- PROJECTDocument3 pagesPROJECTKeerthi GuruNo ratings yet
- PROJECTDocument3 pagesPROJECTKeerthi GuruNo ratings yet
- MATHSADocument3 pagesMATHSAKeerthi GuruNo ratings yet
- SPOCchangerequestletter PDFDocument1 pageSPOCchangerequestletter PDFKeerthi GuruNo ratings yet
- PHD Regulations 2012 PDFDocument15 pagesPHD Regulations 2012 PDFNithin JoseNo ratings yet
- Faculty Norms AICTEDocument9 pagesFaculty Norms AICTEftpeerNo ratings yet
- DBMS Lab ManualDocument16 pagesDBMS Lab ManualKeerthi GuruNo ratings yet
- A03 - Mr. Pradeep Kumar Tripathi - FPSC George Town 18/1A, A.N. Jha Marg Georgetown, Allahabad, UpDocument6 pagesA03 - Mr. Pradeep Kumar Tripathi - FPSC George Town 18/1A, A.N. Jha Marg Georgetown, Allahabad, UpSanjay GuptaNo ratings yet
- Konsolidasi WelmiDocument72 pagesKonsolidasi WelmiWelmi Sulfatri IshakNo ratings yet
- Good Practice Review - 8 - Revised2 PDFDocument323 pagesGood Practice Review - 8 - Revised2 PDFsteppevosNo ratings yet
- Bajaj Allianz General Insurance Company LTD.: Declaration by The InsuredDocument1 pageBajaj Allianz General Insurance Company LTD.: Declaration by The InsuredArtiNo ratings yet
- Uts Ganjil Bahasa Inggris Kelas 9Document11 pagesUts Ganjil Bahasa Inggris Kelas 9Ketua EE 2021 AndrianoNo ratings yet
- Gases Toxicos Irritantes PDFDocument6 pagesGases Toxicos Irritantes PDFLUIS ANDRES JUAREZ CALLENo ratings yet
- Spring Term Core A Formative AssessmentDocument9 pagesSpring Term Core A Formative Assessmentdiscord.tazzNo ratings yet
- Tienchi Ginseng Panax Notoginseng San Qircljo PDFDocument4 pagesTienchi Ginseng Panax Notoginseng San Qircljo PDFTobiasenHolgersen89No ratings yet
- Therapeutic PhlebotomyDocument2 pagesTherapeutic PhlebotomyAimee Howle BuchananNo ratings yet
- Liver Vascular Anatomy - A RefresherDocument10 pagesLiver Vascular Anatomy - A Refresherilham nugrohoNo ratings yet
- Suplemento 1Document56 pagesSuplemento 1Dessirhe LaraNo ratings yet
- Antifoam Oh Conz - GHS EngDocument11 pagesAntifoam Oh Conz - GHS EngOUSMAN SEIDNo ratings yet
- Art Comparison Essay ExampleDocument5 pagesArt Comparison Essay Exampleflrzcpaeg100% (2)
- Sattvika Dite-YakubDocument6 pagesSattvika Dite-Yakubyakubjacob100% (1)
- Plasma Metanephrine Test: Patient Information FactsheetDocument2 pagesPlasma Metanephrine Test: Patient Information FactsheetDamigart PremiumNo ratings yet
- A Decade of Dementia Care Training Learning Needs PDFDocument10 pagesA Decade of Dementia Care Training Learning Needs PDFYovana Pachón PovedaNo ratings yet
- AIA IHS Clinics With TCM - Generic (120613)Document43 pagesAIA IHS Clinics With TCM - Generic (120613)junkaiiiNo ratings yet
- Vyankatesh City-IIDocument17 pagesVyankatesh City-IIapi-27095887No ratings yet
- Intercostal Chest DrainageDocument6 pagesIntercostal Chest DrainageNovalis CrazyNo ratings yet
- Periodontal Accelerated Osteogenic OrthodonticsDocument6 pagesPeriodontal Accelerated Osteogenic Orthodonticsyui cherryNo ratings yet
- CrimPro Cases (Rule 116)Document45 pagesCrimPro Cases (Rule 116)elvinperiaNo ratings yet
- WCLC2017 Abstract Book WebDocument700 pagesWCLC2017 Abstract Book Webdavid.yb.wangNo ratings yet
- Hizon Interview Group 2Document3 pagesHizon Interview Group 2Dan HizonNo ratings yet
- YMCA Program Guide - 2016Document44 pagesYMCA Program Guide - 2016Pickens County YMCANo ratings yet