You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
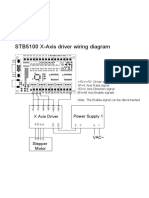
- STB5100 Electric Wiring Diagram 1 - 5Document5 pagesSTB5100 Electric Wiring Diagram 1 - 5PauloTexaNo ratings yet
- Sue Wright Editor Language and The State Revitalization and Revival in Israel and Eire 1996Document78 pagesSue Wright Editor Language and The State Revitalization and Revival in Israel and Eire 1996javadNo ratings yet
- Scope and Sequence 2014 Journeys gr4Document15 pagesScope and Sequence 2014 Journeys gr4api-347346936No ratings yet
- Chapter TwoDocument81 pagesChapter TwoTigist AlemuNo ratings yet
- Chapter ThreeDocument27 pagesChapter ThreeTigist AlemuNo ratings yet
- Chapter FourDocument30 pagesChapter FourTigist AlemuNo ratings yet
- Server Side Chapter OneDocument108 pagesServer Side Chapter OneTigist AlemuNo ratings yet
- Compiler Construction: Principles and Practice Kenneth C. LoudenDocument42 pagesCompiler Construction: Principles and Practice Kenneth C. LoudenTigist AlemuNo ratings yet
- Network Rail - Railway Accident Report Writing GuidanceDocument23 pagesNetwork Rail - Railway Accident Report Writing GuidanceIrwan JoeNo ratings yet
- Mock Interview Rubric 002 1Document1 pageMock Interview Rubric 002 1api-532105563No ratings yet
- Identifying Factors Influencing Students' Motivation and Engagement in Online CoursesDocument11 pagesIdentifying Factors Influencing Students' Motivation and Engagement in Online CoursesNoor SalmanNo ratings yet
- 001 2012 4 b-3Document114 pages001 2012 4 b-3dikahunguNo ratings yet
- 3.2 - Spent Activity - Living Paycheck To PaycheckDocument3 pages3.2 - Spent Activity - Living Paycheck To PaycheckKathryn BourneNo ratings yet
- The Six LokasDocument3 pagesThe Six Lokasunsuiboddhi100% (2)
- Study Plan SampleDocument1 pageStudy Plan SampleSumaiya AkterNo ratings yet
- Definition of EssayDocument3 pagesDefinition of EssayJan Mikel RiparipNo ratings yet
- 8611 - Assignment 2-ALI FAIZUR REHMAN-0000087678 PDFDocument15 pages8611 - Assignment 2-ALI FAIZUR REHMAN-0000087678 PDFAli Faizur RehmanNo ratings yet
- Lecture Notes On Syntactic ProcessingDocument14 pagesLecture Notes On Syntactic ProcessingAkilaNo ratings yet
- 2016 - Locus of Control in Maltreated Children. Roazzi, Attili, Di Pentima & ToniDocument11 pages2016 - Locus of Control in Maltreated Children. Roazzi, Attili, Di Pentima & ToniAntonio RoazziNo ratings yet
- Difficult Emotions Self Help Booklet Indigo DayaDocument12 pagesDifficult Emotions Self Help Booklet Indigo Dayaapi-360754295100% (3)
- Passive Voice TableDocument3 pagesPassive Voice TableBanyas AmbaraNo ratings yet
- 12 Ways To Master The Engine Room Watch KeepingDocument15 pages12 Ways To Master The Engine Room Watch KeepingNabu NabuangNo ratings yet
- Vision For Teachers Portfolio Ed7902Document5 pagesVision For Teachers Portfolio Ed7902api-95458460No ratings yet
- Eng11 Mod4 v1 - OralCommunicationActivitiesDocument28 pagesEng11 Mod4 v1 - OralCommunicationActivitiesENRICONo ratings yet
- Conditional Sentence: - Abror, - Ardhya, - Ardinata, - Billy, - Michael, - NicolasDocument8 pagesConditional Sentence: - Abror, - Ardhya, - Ardinata, - Billy, - Michael, - NicolasAbrorashilsirNo ratings yet
- CBT For Psychosis Process-Orientated Therapies and The Third Wave (Caroline Cupitt (Editor) ) (Z-Library)Document190 pagesCBT For Psychosis Process-Orientated Therapies and The Third Wave (Caroline Cupitt (Editor) ) (Z-Library)Néstor X. PortalatínNo ratings yet
- Chapter 1 - PerceptionsDocument94 pagesChapter 1 - Perceptionsjaime ballesterosNo ratings yet
- 1983 Levelt MonitoringDocument64 pages1983 Levelt MonitoringMichell GadelhaNo ratings yet
- Sexual Self-ImageDocument15 pagesSexual Self-ImageJovy Pelonio100% (2)
- Internal Assessment Criteria IODocument3 pagesInternal Assessment Criteria IORaghavNo ratings yet
- EappDocument10 pagesEappChristine DionesNo ratings yet
- American Stories "The Murders in The Rue Morgue," Part One by Edgar Allan PoeDocument17 pagesAmerican Stories "The Murders in The Rue Morgue," Part One by Edgar Allan PoeRonald MateoNo ratings yet
- DrillsDocument8 pagesDrillsMuhammad Saleem Sattar100% (2)
- DLL - All Subjects 2 - Q3 - W7 - D2Document8 pagesDLL - All Subjects 2 - Q3 - W7 - D2Regie Luceño ProvidoNo ratings yet
- Agam BenDocument15 pagesAgam Benanimalisms100% (1)