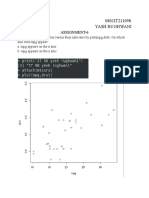
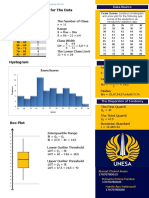
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5811)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (844)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Data Visualization MCQ QuestionsDocument13 pagesData Visualization MCQ QuestionsKapil Singh Bisht50% (2)
- Given That N (P) 28, N (Q) 21 and N (: Modul Topikal Matematik SPM - Cemerlang Peace 6Document7 pagesGiven That N (P) 28, N (Q) 21 and N (: Modul Topikal Matematik SPM - Cemerlang Peace 6Nicholas Lim Chun FungNo ratings yet
- Box PlotDocument4 pagesBox PlotPramod Govind SalunkheNo ratings yet
- Iv. AssignmentDocument4 pagesIv. AssignmentIisha karmela AldayNo ratings yet
- DISCRETE MATH MODULE 5 Venn DiagramDocument11 pagesDISCRETE MATH MODULE 5 Venn DiagramJayNo ratings yet
- Visual VocabDocument10 pagesVisual Vocabnellie_74023951No ratings yet
- Eventos Extremos Mensais de Precipitação para A Região Do Sertão Paraibano (1995 - 2015)Document2 pagesEventos Extremos Mensais de Precipitação para A Região Do Sertão Paraibano (1995 - 2015)Jaricelia SemnaNo ratings yet
- Aas Test Result For The Month of February: Date Measurement Mean LCL (3) UCL (3)Document3 pagesAas Test Result For The Month of February: Date Measurement Mean LCL (3) UCL (3)John P. BandoquilloNo ratings yet
- Common Charts by DhanushDocument7 pagesCommon Charts by DhanushEA0792 Y VenkateshNo ratings yet
- Lesson 2.2.a Stem and Leaf PlotDocument9 pagesLesson 2.2.a Stem and Leaf PlotGian CabayaoNo ratings yet
- Data-Driven Charts and Editable Shapes For PowerpointDocument54 pagesData-Driven Charts and Editable Shapes For PowerpointAlexanderNo ratings yet
- Rajah Ialah Gambar Rajah Venn Yang. Menunjukkan Unsur-Unsur Bagi Set P, Set Q, Dan Set RDocument7 pagesRajah Ialah Gambar Rajah Venn Yang. Menunjukkan Unsur-Unsur Bagi Set P, Set Q, Dan Set Rapizz96No ratings yet
- 9h Stem-Leaf-Level1-1Document2 pages9h Stem-Leaf-Level1-1api-256386911No ratings yet
- Box Plot Answers MMEDocument2 pagesBox Plot Answers MMESabih AzharNo ratings yet
- B4 NotesDocument12 pagesB4 NotesyashNo ratings yet
- Control Chart Example: Date Meas'ent Mean UCL LCLDocument5 pagesControl Chart Example: Date Meas'ent Mean UCL LCLkriteriaNo ratings yet
- Data VisualizationDocument24 pagesData VisualizationJEFFREY WILLIAMS P M 20221013No ratings yet
- 7QC in TamilDocument11 pages7QC in Tamilaimtronele18No ratings yet
- Python 3 Plotting Simple GraphsDocument22 pagesPython 3 Plotting Simple Graphselz0rr0No ratings yet
- Operasi Set: Objective TestDocument6 pagesOperasi Set: Objective TestKymn RzfNo ratings yet
- Box Plot OutliersDocument2 pagesBox Plot Outlierssoumedy curpenNo ratings yet
- Vivek Jain SPM 8th Ed (OCR) - 865Document1 pageVivek Jain SPM 8th Ed (OCR) - 865Farah FarahNo ratings yet
- EWMA Cusum Charts Examples Ch09Document4 pagesEWMA Cusum Charts Examples Ch09cassindromeNo ratings yet
- Data Visualization With PythonDocument19 pagesData Visualization With PythonAakash RanjanNo ratings yet
- FIX Exam ScoresDocument1 pageFIX Exam ScoresAhmad Choirul AnamNo ratings yet
- Safari 7Document1 pageSafari 7prathamkumar8374No ratings yet
- Airport Service TimesDocument19 pagesAirport Service Timesnartha wayneNo ratings yet
- Assignment HistogramDocument4 pagesAssignment HistogramdewNo ratings yet
- Guide To Choosing Charts 1679056579Document1 pageGuide To Choosing Charts 1679056579GemmoTechNo ratings yet
- 3 5 7 MovingAveragesDocument2 pages3 5 7 MovingAveragesMuhammad Nauman KhanNo ratings yet