You might also like
- Pganalyze Advanced+Database+Programming+With+RailsDocument45 pagesPganalyze Advanced+Database+Programming+With+RailsMathieuNo ratings yet
- HCIA-Big Data V2.0 Training MaterialDocument547 pagesHCIA-Big Data V2.0 Training MaterialThiago SiqueiraNo ratings yet
- Hadoop Interview Questions NewDocument9 pagesHadoop Interview Questions NewRupali ShettyNo ratings yet
- Mongo DBDocument13 pagesMongo DBMohit SainiNo ratings yet
- Big Data Huawei CourseDocument23 pagesBig Data Huawei CourseThiago SiqueiraNo ratings yet
- SubtitleDocument2 pagesSubtitleTai NguyenNo ratings yet
- Interview Questions - Hive and QueryingDocument3 pagesInterview Questions - Hive and QueryingJunaid SheikhNo ratings yet
- Big Data Hadoop Interview Questions and AnswersDocument25 pagesBig Data Hadoop Interview Questions and Answersparamreddy2000No ratings yet
- Ibm HadoopDocument4 pagesIbm Hadoop4022 MALISHWARAN MNo ratings yet
- Hbase Research PapersDocument5 pagesHbase Research Papersnoywcfvhf100% (1)
- Hadoop and Java Ques - AnsDocument222 pagesHadoop and Java Ques - AnsraviNo ratings yet
- HBase Essentials Sample ChapterDocument19 pagesHBase Essentials Sample ChapterPackt PublishingNo ratings yet
- HbaseDocument13 pagesHbaseA2 MotivationNo ratings yet
- Apache HIVEDocument105 pagesApache HIVEhemanth kumar p100% (1)
- FileDocument2 pagesFileroopaudtNo ratings yet
- Bda QBDocument18 pagesBda QBtanupandav333No ratings yet
- HBase Design Patterns Sample ChapterDocument16 pagesHBase Design Patterns Sample ChapterPackt PublishingNo ratings yet
- Big Data and Hadoop OverviewDocument17 pagesBig Data and Hadoop OverviewShreekanth Vankamamidi, PMP100% (1)
- Big Data Hadoop Interview Questions and AnswersDocument26 pagesBig Data Hadoop Interview Questions and AnswersCosmicBlueNo ratings yet
- Apache Hive Interview Questions: 1. Define The Difference Between Hive and Hbase?Document10 pagesApache Hive Interview Questions: 1. Define The Difference Between Hive and Hbase?shubham rathodNo ratings yet
- Assignment 6Document12 pagesAssignment 6Pujan PatelNo ratings yet
- Oracle and Hadoop by Gwen ShapiraDocument5 pagesOracle and Hadoop by Gwen ShapiraSaeed MeethalNo ratings yet
- Hadoop TutorialDocument3 pagesHadoop TutorialSundaram yadavNo ratings yet
- Hadoop Data Lake: Hadoop Log Files JsonDocument5 pagesHadoop Data Lake: Hadoop Log Files JsonSrinivas GollanapalliNo ratings yet
- NoSQL DatabaseDocument8 pagesNoSQL Databasejosephowino13101No ratings yet
- Assignment No 01Document34 pagesAssignment No 01aaNo ratings yet
- BDA Unit 5 HIVE HBASEDocument33 pagesBDA Unit 5 HIVE HBASESREEKANTH ARKATNo ratings yet
- A Review Paper On Big Data Database'S: Cassandra, Hbase, HiveDocument6 pagesA Review Paper On Big Data Database'S: Cassandra, Hbase, Hiveshani thakurNo ratings yet
- Hadoop QuestionsDocument14 pagesHadoop QuestionsShreya KasturiaNo ratings yet
- 6 Frequently Asked Hadoop Interview Questions and Answers: Q1.What Is Hadoop?Document8 pages6 Frequently Asked Hadoop Interview Questions and Answers: Q1.What Is Hadoop?Krish DhoomNo ratings yet
- MapreduceDocument15 pagesMapreducemanasaNo ratings yet
- SDL Module-No SQL Module Assignment No. 2: Q1 What Is Hadoop and Need For It? Discuss It's ArchitectureDocument6 pagesSDL Module-No SQL Module Assignment No. 2: Q1 What Is Hadoop and Need For It? Discuss It's ArchitectureasdfasdfNo ratings yet
- DatabasesDocument16 pagesDatabasesIsha PundirNo ratings yet
- HADOOPDocument40 pagesHADOOPsaadiaiftikhar123No ratings yet
- Unit 3Document61 pagesUnit 3Ramstage TestingNo ratings yet
- Implementation of Multi Node Clusters in Column Oriented Database Using HDFSDocument5 pagesImplementation of Multi Node Clusters in Column Oriented Database Using HDFSIJEACS UKNo ratings yet
- Module 2 Hadoop Eco SystemDocument13 pagesModule 2 Hadoop Eco Systemn4519072No ratings yet
- HiveDocument2 pagesHivescribd.unguided000No ratings yet
- Big Data Introduction & EcosystemsDocument4 pagesBig Data Introduction & EcosystemsHarish ChNo ratings yet
- Big Data Unit 5Document18 pagesBig Data Unit 5hemantsinghNo ratings yet
- Java ProjectsDocument5 pagesJava ProjectsvijaykokoluNo ratings yet
- 1 &2 - The Big Data Technology Landscape MyppyDocument25 pages1 &2 - The Big Data Technology Landscape MyppyShushanth munnaNo ratings yet
- Diwakarthapa Hdfs SummaryDocument1 pageDiwakarthapa Hdfs SummaryThewalker ThapaNo ratings yet
- Lec4 MergedDocument84 pagesLec4 MergedArifa KhadriNo ratings yet
- Lec 4Document28 pagesLec 4bhargaviNo ratings yet
- Big Data Tools and Its FrameworkDocument5 pagesBig Data Tools and Its Framework2041020004.smrutitanayaNo ratings yet
- Lecture Notes: Data Ingestion For Structured/Unstructured DataDocument31 pagesLecture Notes: Data Ingestion For Structured/Unstructured DataYuvaraj V, Assistant Professor, BCANo ratings yet
- Big Data & HadoopDocument7 pagesBig Data & HadoopNowshin JerinNo ratings yet
- Big Data & HadoopDocument7 pagesBig Data & HadoopNowshin JerinNo ratings yet
- BDA Unit 2 Q&ADocument14 pagesBDA Unit 2 Q&AviswakranthipalagiriNo ratings yet
- DSBDA ORAL Question BankDocument6 pagesDSBDA ORAL Question BankSUnny100% (1)
- Pig Vs Hive VS Native Map Reduc E: PangoolDocument6 pagesPig Vs Hive VS Native Map Reduc E: PangoolkumarNo ratings yet
- 2023 Assignment AnswersDocument52 pages2023 Assignment AnswershodaimlNo ratings yet
- Introduction To HadoopDocument5 pagesIntroduction To HadoopHanumanthu GouthamiNo ratings yet
- Big Data Hadoop Training 8214944.ppsxDocument52 pagesBig Data Hadoop Training 8214944.ppsxhoukoumatNo ratings yet
- BDA NotesDocument25 pagesBDA Notesmrudula.sbNo ratings yet
- 21ai402 Data Analytics Unit-2Document44 pages21ai402 Data Analytics Unit-2PriyadarshiniNo ratings yet
- NoSQL Databases NotesDocument5 pagesNoSQL Databases NotesAkansha UniyalNo ratings yet
- HadoopDocument6 pagesHadoopVikas SinhaNo ratings yet
- AaxHadoop Interview Questions and AnswersDocument37 pagesAaxHadoop Interview Questions and Answersshubham rathodNo ratings yet
- Compare Hadoop & Spark Criteria Hadoop SparkDocument18 pagesCompare Hadoop & Spark Criteria Hadoop Sparkdasari ramyaNo ratings yet
- Dbms Lab ManualDocument77 pagesDbms Lab ManualSarvesh DharmeNo ratings yet
- Flink: Big Data Huawei CourseDocument22 pagesFlink: Big Data Huawei CourseThiago SiqueiraNo ratings yet
- Spark2x: Big Data Huawei CourseDocument25 pagesSpark2x: Big Data Huawei CourseThiago SiqueiraNo ratings yet
- Streaming: Big Data Huawei CourseDocument19 pagesStreaming: Big Data Huawei CourseThiago SiqueiraNo ratings yet
- Kafka: Big Data Huawei CourseDocument14 pagesKafka: Big Data Huawei CourseThiago SiqueiraNo ratings yet
- Flume: Big Data Huawei CourseDocument13 pagesFlume: Big Data Huawei CourseThiago SiqueiraNo ratings yet
- Big Data Huawei CourseDocument23 pagesBig Data Huawei CourseThiago SiqueiraNo ratings yet
- Resumo MapReduce YARNDocument13 pagesResumo MapReduce YARNThiago SiqueiraNo ratings yet
- Loader: Big Data Huawei CourseDocument11 pagesLoader: Big Data Huawei CourseThiago SiqueiraNo ratings yet
- Big Data Huawei CourseDocument12 pagesBig Data Huawei CourseThiago SiqueiraNo ratings yet
- How-To Trace Oracle Sessions - Alex Zeng's BlogDocument5 pagesHow-To Trace Oracle Sessions - Alex Zeng's Blogalok_mishra4533No ratings yet
- DBMS Unit-6Document35 pagesDBMS Unit-6महेश विजय खेडेकरNo ratings yet
- Project Report CBDocument34 pagesProject Report CBBhargav C BNo ratings yet
- Sqlite - Syntax: Case SensitivityDocument4 pagesSqlite - Syntax: Case SensitivityCervantes Darell KimNo ratings yet
- Elective-I Advanced Database Management Systems: Unit IiiDocument38 pagesElective-I Advanced Database Management Systems: Unit IiiPranil NandeshwarNo ratings yet
- Transaction ManagementDocument26 pagesTransaction ManagementZarnab sarfrazNo ratings yet
- Hadoop and Their EcosystemDocument24 pagesHadoop and Their Ecosystemsunera pathan100% (1)
- Week 1 Day 1: Xampp Installation GuideDocument8 pagesWeek 1 Day 1: Xampp Installation GuideJhon Keneth NamiasNo ratings yet
- Joins in RDBMSDocument24 pagesJoins in RDBMSAnbusaba ShanmugamNo ratings yet
- DBMS Lab ManualDocument23 pagesDBMS Lab Manualedwinarun7273No ratings yet
- Geek InterviewDocument70 pagesGeek Interviewashishpathak1No ratings yet
- Normal FormsDocument19 pagesNormal FormsJebastin RajNo ratings yet
- Database Management SystemsDocument84 pagesDatabase Management SystemsTas MimaNo ratings yet
- Sql-Lab 3 DML PDFDocument4 pagesSql-Lab 3 DML PDFKapil PokhrelNo ratings yet
- MCQ QuesDocument2 pagesMCQ Quesprathapmca888_584971No ratings yet
- Database Programming With PL/SQL 3-4: Practice Activities: Using Transaction Control StatementsDocument3 pagesDatabase Programming With PL/SQL 3-4: Practice Activities: Using Transaction Control StatementsBogdan BicaNo ratings yet
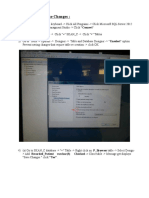
- SKANC Database Changes:: Varchar (3) Checked - Close Table - Message Get DisplaysDocument5 pagesSKANC Database Changes:: Varchar (3) Checked - Close Table - Message Get Displaysابو حميد ابو حميدNo ratings yet
- Dynamodb, Ebs, VPC, Elb Couchdb, Redis: Eclipse, Intellij, Pycharm, Git, SVN, CRM, SplunkDocument1 pageDynamodb, Ebs, VPC, Elb Couchdb, Redis: Eclipse, Intellij, Pycharm, Git, SVN, CRM, SplunkPiyush ChauhanNo ratings yet
- Keys in DBMSDocument4 pagesKeys in DBMSRagav RajNo ratings yet
- The Basics of Oracle ArchitectureDocument5 pagesThe Basics of Oracle Architecturechetanb39No ratings yet
- Unit-3 Dbms Part2Document117 pagesUnit-3 Dbms Part2Guntuku BaleswariNo ratings yet
- ER Diagram For Railway Management System: DetailsDocument7 pagesER Diagram For Railway Management System: DetailsBryanCalixtroNo ratings yet
- How To Convert Relational Data To XML - MelbourneDocument56 pagesHow To Convert Relational Data To XML - Melbournesp40694No ratings yet
- Creating A DatabaseDocument9 pagesCreating A DatabasegmasayNo ratings yet
- Mysql FinalDocument14 pagesMysql FinalNITANT KALRANo ratings yet
- Export 2 ExcelDocument2 pagesExport 2 ExcelSrinivas RaoNo ratings yet
- Final MCQ DTDocument176 pagesFinal MCQ DTBharat SarandaNo ratings yet
- Oracle PracticalDocument11 pagesOracle PracticalPrashantlal0% (1)