You might also like
- The Custom BicycleDocument276 pagesThe Custom BicycleVytautas100% (6)
- NSX 100-630 User ManualDocument152 pagesNSX 100-630 User Manualagra04100% (1)
- Scientology Abridged Dictionary 1973Document21 pagesScientology Abridged Dictionary 1973Cristiano Manzzini100% (2)
- Linux for Beginners: Linux Command Line, Linux Programming and Linux Operating SystemFrom EverandLinux for Beginners: Linux Command Line, Linux Programming and Linux Operating SystemRating: 4.5 out of 5 stars4.5/5 (3)
- Essene Moses Ten CommandmentsDocument4 pagesEssene Moses Ten Commandmentsjeryon91No ratings yet
- Ubuntu Linux Toolbox: 1000+ Commands for Power UsersFrom EverandUbuntu Linux Toolbox: 1000+ Commands for Power UsersRating: 4 out of 5 stars4/5 (1)
- GreDocument77 pagesGrebiomath100% (1)
- Driving A Manual Car For Beginners TipsDocument11 pagesDriving A Manual Car For Beginners TipsAnym de Cièlo100% (1)
- Server and NetworkDocument8 pagesServer and Networkpushp2011No ratings yet
- Linux: A Comprehensive Guide to Linux Operating System and Command LineFrom EverandLinux: A Comprehensive Guide to Linux Operating System and Command LineNo ratings yet
- Introduction To Piping EngineerDocument46 pagesIntroduction To Piping EngineerFebrianto Edy PratamaNo ratings yet
- European Welding New-StandardsDocument39 pagesEuropean Welding New-StandardsJOECOOL67100% (3)
- Introduction To The Linux KernelDocument7 pagesIntroduction To The Linux KernelhuyyNo ratings yet
- Desktop & Technical Support Interview Questions and AnswersDocument64 pagesDesktop & Technical Support Interview Questions and Answersvinaaypalkar80% (46)
- Photovoltaic Principles (NREL) PDFDocument71 pagesPhotovoltaic Principles (NREL) PDFED DK KANo ratings yet
- The Physics of Cycling PDFDocument79 pagesThe Physics of Cycling PDFDiego PolliniNo ratings yet
- ClientsDocument7 pagesClientsLiane PanahacNo ratings yet
- Sun's Network File System (NFS) : SecurityDocument16 pagesSun's Network File System (NFS) : SecurityI srcNo ratings yet
- Sun's NFS: Stateless for Fast Crash RecoveryDocument22 pagesSun's NFS: Stateless for Fast Crash RecoverynvrsaynoNo ratings yet
- SNMR Ia2 Ab PDFDocument20 pagesSNMR Ia2 Ab PDFVaibhav PhadNo ratings yet
- What Is A File System?Document7 pagesWhat Is A File System?ManziniLeeNo ratings yet
- The Styx Architecture For Distributed SystemsDocument8 pagesThe Styx Architecture For Distributed SystemsMilen KrustevNo ratings yet
- Distributed File SystemsDocument14 pagesDistributed File SystemslolllNo ratings yet
- Interview QuestionDocument9 pagesInterview Questionsonupawar8883No ratings yet
- Network File SystemDocument5 pagesNetwork File SystemBallesteros CarlosNo ratings yet
- ClouddafinalDocument8 pagesClouddafinalRahithya AmbarapuNo ratings yet
- ClouddaDocument8 pagesClouddaRahithya AmbarapuNo ratings yet
- Week 1 TutorialDocument12 pagesWeek 1 TutorialRabindra PoudelNo ratings yet
- File ServerDocument3 pagesFile Serversami.yaha100% (1)
- Distributed File SystemsDocument11 pagesDistributed File SystemsSimi SanyaNo ratings yet
- Introduction To SAN and NAS StorageDocument8 pagesIntroduction To SAN and NAS StoragePrashanth ChandranNo ratings yet
- The Berkley College: Practical File of Novel Netware (Practical Software Lab - XII)Document51 pagesThe Berkley College: Practical File of Novel Netware (Practical Software Lab - XII)P.s. DhimanNo ratings yet
- Atc19 KuszmaulDocument18 pagesAtc19 KuszmaulMas HanNo ratings yet
- Desktop Interview Question: 1) What Is LMHOSTS File? 2) What's The Difference Between Local, Global and Universal Groups?Document3 pagesDesktop Interview Question: 1) What Is LMHOSTS File? 2) What's The Difference Between Local, Global and Universal Groups?Mahadevi BiradarNo ratings yet
- 2015KS Singhal-LUSTRE HPC FileSystem Deployment Method PDFDocument27 pages2015KS Singhal-LUSTRE HPC FileSystem Deployment Method PDFSanket PandhareNo ratings yet
- Teknologi Pusat DataDocument9 pagesTeknologi Pusat Datahendroni2210No ratings yet
- Scale and Performance in A Distributed File SystemDocument31 pagesScale and Performance in A Distributed File Systemeinsteniano40000No ratings yet
- RPC Protocol: Remote Procedure CallDocument25 pagesRPC Protocol: Remote Procedure CallPriyanka AherNo ratings yet
- DS UNIT-4 Saqs Laqs (Completed)Document14 pagesDS UNIT-4 Saqs Laqs (Completed)siddumudavath93No ratings yet
- Assignment 1Document9 pagesAssignment 1iansojunior60No ratings yet
- Reliable Distributed SystemsDocument44 pagesReliable Distributed Systemslcm3766lNo ratings yet
- SAN - IAT - 2-Oct 2015 SchemeDocument8 pagesSAN - IAT - 2-Oct 2015 SchemeSOURAV CHATTERJEENo ratings yet
- OS Support for Distributed MiddlewareDocument6 pagesOS Support for Distributed MiddlewareoljiraaNo ratings yet
- Case Study : Linux Operating SystemDocument8 pagesCase Study : Linux Operating SystemRahul PawarNo ratings yet
- MCS-022 Operating System Concepts andDocument29 pagesMCS-022 Operating System Concepts andSumit RanjanNo ratings yet
- Session 1 AnswerDocument3 pagesSession 1 AnswerAdvait GarvNo ratings yet
- Data Structures Unit 5Document9 pagesData Structures Unit 5Animated EngineerNo ratings yet
- Tle-12 q1 Las Css Wk7day1Document2 pagesTle-12 q1 Las Css Wk7day1marivic itongNo ratings yet
- This Linux Certification Training: The Command Used: PR - l60 DraftDocument6 pagesThis Linux Certification Training: The Command Used: PR - l60 DraftSopan sonarNo ratings yet
- Project Report On Network Operating System: Strength To Client/Server ArchitectureDocument23 pagesProject Report On Network Operating System: Strength To Client/Server ArchitectureKavita KarkiNo ratings yet
- Answer Unix QBankDocument12 pagesAnswer Unix QBankSaketNo ratings yet
- Components of A Network Operating SystemDocument15 pagesComponents of A Network Operating Systemgerome_vasNo ratings yet
- Linux Homework on Commands and OS StructureDocument18 pagesLinux Homework on Commands and OS StructureSurendra ChauhanNo ratings yet
- Network Administration ReviewerDocument616 pagesNetwork Administration ReviewerMichael Arthur SantiagoNo ratings yet
- Components of A Network Operating System: Last Update To This HTML Version, August 18, 2006 - JedDocument23 pagesComponents of A Network Operating System: Last Update To This HTML Version, August 18, 2006 - JedSwati HelloNo ratings yet
- Auditing Lustre File System: Texas Tech University Texas, USA Saarefin@ttu - EduDocument5 pagesAuditing Lustre File System: Texas Tech University Texas, USA Saarefin@ttu - EduSanket PandhareNo ratings yet
- FS-OS-Apps: File Systems, Operating Systems and Application SoftwareDocument13 pagesFS-OS-Apps: File Systems, Operating Systems and Application SoftwareNoreen Nyauchi SaraiNo ratings yet
- Two criteria and examples of advanced operating systemsDocument27 pagesTwo criteria and examples of advanced operating systemsdevil angelNo ratings yet
- Introduction to Client/Server ArchitectureDocument21 pagesIntroduction to Client/Server ArchitectureGautam PriyadarshiNo ratings yet
- Research PaperDocument11 pagesResearch Papersaurabh singh gahlotNo ratings yet
- Presentation ON Distributed File System: Institute of Engineering and Technology Bundelkhand UniversityDocument51 pagesPresentation ON Distributed File System: Institute of Engineering and Technology Bundelkhand UniversitySaumya KatiyarNo ratings yet
- Case Study On Network File SystemDocument8 pagesCase Study On Network File SystemStarSports kabaddiNo ratings yet
- Case Study On Network File SystemDocument8 pagesCase Study On Network File SystemStarSports kabaddiNo ratings yet
- LPI Exam 201 Prep:: File and Service SharingDocument14 pagesLPI Exam 201 Prep:: File and Service SharingSeth4ChaosNo ratings yet
- Overview of LinuxDocument0 pagesOverview of LinuxAmit MishraNo ratings yet
- Introduction, The Operating System Layer, Protection, Process and Threads Address Space, Creation of A New Process, ThreadsDocument10 pagesIntroduction, The Operating System Layer, Protection, Process and Threads Address Space, Creation of A New Process, ThreadsSurya BhaskerNo ratings yet
- “Information Systems Unraveled: Exploring the Core Concepts”: GoodMan, #1From Everand“Information Systems Unraveled: Exploring the Core Concepts”: GoodMan, #1No ratings yet
- Working and Types of Forklifts For The Construction IndustryDocument5 pagesWorking and Types of Forklifts For The Construction IndustryTUSHAR BANGERANo ratings yet
- Everything You Need to Know About Pipe SaddlesDocument4 pagesEverything You Need to Know About Pipe SaddlesTUSHAR BANGERANo ratings yet
- Duck On A Bike: Pre-K Essential Literature by David ShannonDocument2 pagesDuck On A Bike: Pre-K Essential Literature by David ShannonTUSHAR BANGERANo ratings yet
- What Is A Sideboom PipeLayerDocument3 pagesWhat Is A Sideboom PipeLayerTUSHAR BANGERANo ratings yet
- Supporting and Design Consideration of Small-Bore PipingDocument4 pagesSupporting and Design Consideration of Small-Bore PipingTUSHAR BANGERANo ratings yet
- The Sun: Guide For ReadingDocument2 pagesThe Sun: Guide For ReadingTUSHAR BANGERANo ratings yet
- Solar Radiation Hand Book (2008) : Typical Climatic Data For Selected Radiation StationsDocument80 pagesSolar Radiation Hand Book (2008) : Typical Climatic Data For Selected Radiation StationsGirish PatilNo ratings yet
- Indices Surds Logarithm NotesDocument20 pagesIndices Surds Logarithm NotesTUSHAR BANGERANo ratings yet
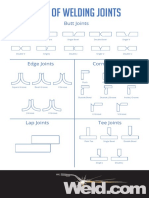
- Types of Common Welding Joints ExplainedDocument1 pageTypes of Common Welding Joints ExplainedTUSHAR BANGERANo ratings yet
- Solar CycleDocument6 pagesSolar CycleanandhugsNo ratings yet
- 7 English NCERT Chapter PDFDocument13 pages7 English NCERT Chapter PDFudswainNo ratings yet
- Renogy RV Solar Panel Installation Manual and GuideDocument22 pagesRenogy RV Solar Panel Installation Manual and GuideTUSHAR BANGERANo ratings yet
- Solar Panel Construction, Orientation and Use - Page 1 of 31Document31 pagesSolar Panel Construction, Orientation and Use - Page 1 of 31TUSHAR BANGERANo ratings yet
- IRENA Electric Vehicles 2017Document52 pagesIRENA Electric Vehicles 2017jrocatt10No ratings yet
- Solar Panel Construction, Orientation and Use - Page 1 of 31Document31 pagesSolar Panel Construction, Orientation and Use - Page 1 of 31TUSHAR BANGERANo ratings yet
- The Electric Vehicle: A Review: International Journal of Electric and Hybrid Vehicles January 2017Document19 pagesThe Electric Vehicle: A Review: International Journal of Electric and Hybrid Vehicles January 2017TUSHAR BANGERANo ratings yet
- Beginners-Guide Final Sept2 2014Document14 pagesBeginners-Guide Final Sept2 2014piyushNo ratings yet
- Spur, Helical, Bevel, and Worm GearsDocument2 pagesSpur, Helical, Bevel, and Worm GearsVinayak RaoNo ratings yet
- Spec Sheet - ABS-M30 ENDocument2 pagesSpec Sheet - ABS-M30 ENTUSHAR BANGERANo ratings yet
- Design and Fabrication of Electric Bike: Shweta MateyDocument9 pagesDesign and Fabrication of Electric Bike: Shweta MateySumanth NNo ratings yet
- L Williams ResumeDocument2 pagesL Williams Resumeapi-555629186No ratings yet
- ChromosomesDocument24 pagesChromosomesapi-249102379No ratings yet
- Edmonson - Pageantry Overture - AnalysisDocument3 pagesEdmonson - Pageantry Overture - Analysisapi-426112870No ratings yet
- Pure and Applied Analysis Problems Solved Step-by-StepDocument8 pagesPure and Applied Analysis Problems Solved Step-by-Stepalpha2122No ratings yet
- HHG4M - Lifespan Development Textbook Lesson 2Document95 pagesHHG4M - Lifespan Development Textbook Lesson 2Lubomira SucheckiNo ratings yet
- IPO Fact Sheet - Accordia Golf Trust 140723Document4 pagesIPO Fact Sheet - Accordia Golf Trust 140723Invest StockNo ratings yet
- SS1c MIDTERMS LearningModuleDocument82 pagesSS1c MIDTERMS LearningModuleBryce VentenillaNo ratings yet
- SolarBright MaxBreeze Solar Roof Fan Brochure Web 1022Document4 pagesSolarBright MaxBreeze Solar Roof Fan Brochure Web 1022kewiso7811No ratings yet
- Quick Reference - HVAC (Part-1) : DECEMBER 1, 2019Document18 pagesQuick Reference - HVAC (Part-1) : DECEMBER 1, 2019shrawan kumarNo ratings yet
- Oas Community College: Republic of The Philippines Commission On Higher Education Oas, AlbayDocument22 pagesOas Community College: Republic of The Philippines Commission On Higher Education Oas, AlbayJaycel NepalNo ratings yet
- Athenaze 1 Chapter 7a Jun 18th 2145Document3 pagesAthenaze 1 Chapter 7a Jun 18th 2145maverickpussNo ratings yet
- Guillermo Estrella TolentinoDocument15 pagesGuillermo Estrella TolentinoJessale JoieNo ratings yet
- Technical Description: BoilerDocument151 pagesTechnical Description: BoilerÍcaro VianaNo ratings yet
- Staining TechniquesDocument31 pagesStaining TechniquesKhadija JaraNo ratings yet
- Administracion Una Perspectiva Global Y Empresarial Resumen Por CapitulosDocument7 pagesAdministracion Una Perspectiva Global Y Empresarial Resumen Por Capitulosafmqqaepfaqbah100% (1)
- Oral Medication PharmacologyDocument4 pagesOral Medication PharmacologyElaisa Mae Delos SantosNo ratings yet
- Eole Press KitDocument15 pagesEole Press KitBob AndrepontNo ratings yet
- 99th Indian Science Congress (Bhubaneshwar)Document95 pages99th Indian Science Congress (Bhubaneshwar)Aadarsh DasNo ratings yet
- PedigreesDocument5 pagesPedigreestpn72hjg88No ratings yet
- Lateral capacity of pile in clayDocument10 pagesLateral capacity of pile in clayGeetha MaNo ratings yet
- City MSJDocument50 pagesCity MSJHilary LedwellNo ratings yet
- Understanding 2006 PSAT-NMSQT ScoresDocument8 pagesUnderstanding 2006 PSAT-NMSQT ScorestacobeoNo ratings yet
- Corporate Governance in SMEsDocument18 pagesCorporate Governance in SMEsSana DjaanineNo ratings yet
- Millennium Separation ReportDocument3 pagesMillennium Separation ReportAlexandra AkeNo ratings yet
- Fashion Cycle StepsDocument2 pagesFashion Cycle Stepssaranya narenNo ratings yet
- Multivariate Analysis Homework QuestionsDocument2 pagesMultivariate Analysis Homework Questions歐怡君No ratings yet