You might also like
- Cook's Illustrated 090Document36 pagesCook's Illustrated 090vicky610100% (3)
- Invoice Being Charged Sued If or Violation Has This in Wrongful - RightfulDocument67 pagesInvoice Being Charged Sued If or Violation Has This in Wrongful - RightfulSteven SchoferNo ratings yet
- VRF, MPLS and MP-BGP FundamentalsDocument55 pagesVRF, MPLS and MP-BGP FundamentalsIVAN TANEV100% (2)
- Earth Works Volume Conversion and Swell FactorsDocument4 pagesEarth Works Volume Conversion and Swell FactorsJj BarakaNo ratings yet
- Assurance Question Bank 2013 PDFDocument168 pagesAssurance Question Bank 2013 PDFIan RelacionNo ratings yet
- LP Exemplar in English 9 Verbal and Non VerbalDocument3 pagesLP Exemplar in English 9 Verbal and Non VerbalBaby Lyn Oamil EusebioNo ratings yet
- Overcoming ChallengesDocument28 pagesOvercoming ChallengesDeutsche Mark CuynoNo ratings yet
- Jitante Stotram v4 PDFDocument71 pagesJitante Stotram v4 PDFRamadevaNo ratings yet
- The Pevearsion of Russian LiteratureDocument8 pagesThe Pevearsion of Russian LiteratureStan MazoNo ratings yet
- OSTEOARTHRITISDocument53 pagesOSTEOARTHRITISRiza Umami100% (1)
- KF2.5-200 - With-M-C - GB - 03-15 KRACHT Bomba PDFDocument8 pagesKF2.5-200 - With-M-C - GB - 03-15 KRACHT Bomba PDFJairo Andrés FA100% (1)
- Computation: A Modification of The Fast Inverse Square Root AlgorithmDocument14 pagesComputation: A Modification of The Fast Inverse Square Root AlgorithmDavid C HouserNo ratings yet
- K01603 - 20190413172609 - Lecture Note - Chapter 3 PDFDocument32 pagesK01603 - 20190413172609 - Lecture Note - Chapter 3 PDFSHARIFAH NUR ARISHIA WAN HAZAMINo ratings yet
- ArticleDocument14 pagesArticlealipirkhedriNo ratings yet
- Sign Bit DetectorDocument11 pagesSign Bit DetectorkaranNo ratings yet
- Vector Quantization: Data Compression and Data RetrievalDocument39 pagesVector Quantization: Data Compression and Data RetrievalPooja BhartiNo ratings yet
- EECE 5550 Mobile Robotics Lab #4: Due: Nov 21, 2022Document6 pagesEECE 5550 Mobile Robotics Lab #4: Due: Nov 21, 2022isic.mirjanaNo ratings yet
- Problem Set 1: 2.29 Numerical Fluid Mechanics - Spring 2015Document8 pagesProblem Set 1: 2.29 Numerical Fluid Mechanics - Spring 2015Ihab OmarNo ratings yet
- Unit 3Document24 pagesUnit 3websurfer2002No ratings yet
- HW 1Document8 pagesHW 1BenNo ratings yet
- Determinants (CTD) : Cramer's Rule (Section 2.3)Document9 pagesDeterminants (CTD) : Cramer's Rule (Section 2.3)asahNo ratings yet
- Correctedreport EXP 3Document12 pagesCorrectedreport EXP 3SuneelRuttalaNo ratings yet
- DCT Presentation1Document39 pagesDCT Presentation1party0703No ratings yet
- Data Compression Seminar Scalar Quantizer DesignDocument9 pagesData Compression Seminar Scalar Quantizer DesignJohnKiefferNo ratings yet
- Fast Support Vector Classifier With Quantile: School of Mathematical Sciences, Inner Mongolia University, ChinaDocument7 pagesFast Support Vector Classifier With Quantile: School of Mathematical Sciences, Inner Mongolia University, ChinaJagan J Jagan JNo ratings yet
- 4.3 2-D Discrete Cosine Transforms: N N K N N K N N X K K XDocument19 pages4.3 2-D Discrete Cosine Transforms: N N K N N K N N X K K Xnayeem4444No ratings yet
- Soft Decoding Techniques for the Golay Code and Leech LatticeDocument46 pagesSoft Decoding Techniques for the Golay Code and Leech Latticekunduru_reddy_3No ratings yet
- The W Hashing FunctionDocument20 pagesThe W Hashing FunctionSri Chandan KalavapudiNo ratings yet
- midterm_20Document2 pagesmidterm_20Hamdi M. SaifNo ratings yet
- Calcul DiffDocument38 pagesCalcul Difffakraouicpge2019No ratings yet
- 3 PDFDocument56 pages3 PDFTala AbdelghaniNo ratings yet
- Chapter 3Document32 pagesChapter 3LEE LEE LAUNo ratings yet
- On Codes and Siegel Modular Forms: E. XT Xo, Xo, Xoo, Xo, Xo, XoDocument12 pagesOn Codes and Siegel Modular Forms: E. XT Xo, Xo, Xoo, Xo, Xo, XoNur HamidNo ratings yet
- Calculus 1 HW Assignment #4 Deadline April 04Document5 pagesCalculus 1 HW Assignment #4 Deadline April 04Nhi DiễmNo ratings yet
- Article Title 1Document12 pagesArticle Title 1alipirkhedriNo ratings yet
- Source and Channel Encoder and Decoder Modeling: S-72.333 Postgraduate Course in Radiocommunications Fall 2000Document17 pagesSource and Channel Encoder and Decoder Modeling: S-72.333 Postgraduate Course in Radiocommunications Fall 2000Adarsh AnchiNo ratings yet
- An Adaptive Nonlinear Least-Squares AlgorithmDocument21 pagesAn Adaptive Nonlinear Least-Squares AlgorithmOleg ShirokobrodNo ratings yet
- Basics of Wavelets: Isye8843A, Brani Vidakovic Handout 20Document27 pagesBasics of Wavelets: Isye8843A, Brani Vidakovic Handout 20Abbas AbbasiNo ratings yet
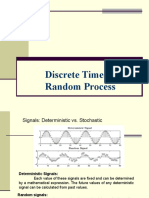
- Discrete Time Random ProcessDocument35 pagesDiscrete Time Random ProcessSundarRajanNo ratings yet
- BarrDocument15 pagesBarrYash MehrotraNo ratings yet
- Some Modified Matrix Eigenvalue: E 2 (X), (A I) A (X) - (9) ) - A (A) O'i (A O'2 (A A, (A) 21 (A) 22 (A) 2, (A)Document17 pagesSome Modified Matrix Eigenvalue: E 2 (X), (A I) A (X) - (9) ) - A (A) O'i (A O'2 (A A, (A) 21 (A) 22 (A) 2, (A)Satyavir YadavNo ratings yet
- 1 Mathematical Modeling of Physical SystemsDocument18 pages1 Mathematical Modeling of Physical Systemsmichael KetselaNo ratings yet
- Recursive Least Squares Algorithm For Nonlinear Dual-Rate Systems Using Missing-Output Estimation ModelDocument20 pagesRecursive Least Squares Algorithm For Nonlinear Dual-Rate Systems Using Missing-Output Estimation ModelTín Trần TrungNo ratings yet
- Chapter 2 Metric Spaces 2018Document19 pagesChapter 2 Metric Spaces 2018PutriNo ratings yet
- Paper: MatrixDocument3 pagesPaper: Matrixsanjay udhayaNo ratings yet
- IIT Block CodesDocument12 pagesIIT Block CodesHarshaNo ratings yet
- Wavelets and Image Compression: A Guide to Multiresolution Analysis and Its ApplicationsDocument20 pagesWavelets and Image Compression: A Guide to Multiresolution Analysis and Its ApplicationsAshish PandeyNo ratings yet
- Double Cyclic Codes: 2 Cristina Fernández-Córdoba Roger Ten-VallsDocument17 pagesDouble Cyclic Codes: 2 Cristina Fernández-Córdoba Roger Ten-VallsmathsNo ratings yet
- Vectors and Its RepresentationsDocument2 pagesVectors and Its RepresentationsFranklyn FrankNo ratings yet
- LDPC-Coded 8PSK DesignDocument4 pagesLDPC-Coded 8PSK DesignNitesh ChilakalaNo ratings yet
- RC6 AttackDocument10 pagesRC6 AttackМилош ПантовићNo ratings yet
- 4curve Fitting TechniquesDocument32 pages4curve Fitting TechniquesSubhankarGangulyNo ratings yet
- New branch and bound algorithm for integer quadratic problemsDocument12 pagesNew branch and bound algorithm for integer quadratic problemsShah AzNo ratings yet
- Discrete-Time Signals and Systems: Gao Xinbo School of E.E., Xidian UnivDocument40 pagesDiscrete-Time Signals and Systems: Gao Xinbo School of E.E., Xidian UnivThagiat Ahzan AdpNo ratings yet
- Final Slides HLDocument22 pagesFinal Slides HLapi-534815355No ratings yet
- CHAPTER 3: Cyclic and Convolution CodesDocument30 pagesCHAPTER 3: Cyclic and Convolution CodesHamzah NaserNo ratings yet
- P1 - 16 and Quantization... DCDocument8 pagesP1 - 16 and Quantization... DCsana aminNo ratings yet
- Chapter 2: Quadratic ProgrammingDocument16 pagesChapter 2: Quadratic ProgrammingcartamenesNo ratings yet
- Vector and Matrix NormDocument17 pagesVector and Matrix NormpaivensolidsnakeNo ratings yet
- Notes MS 2014Document38 pagesNotes MS 2014dnyNo ratings yet
- 4 Sampling Quantization 0809Document13 pages4 Sampling Quantization 0809maricela_eliz453No ratings yet
- Cs6402 DAA Notes (Unit-3)Document25 pagesCs6402 DAA Notes (Unit-3)Jayakumar DNo ratings yet
- Semi-Orthogonal Wavelets of Space and Fast Wavelet AlgorithmsDocument6 pagesSemi-Orthogonal Wavelets of Space and Fast Wavelet AlgorithmsjuanNo ratings yet
- Mpc12 ExamDocument8 pagesMpc12 Examamir12345678No ratings yet
- Determining The Magnetic Field of A Circular Current Using Biot-Savart's LawDocument2 pagesDetermining The Magnetic Field of A Circular Current Using Biot-Savart's LawPhạm Hoàng SơnNo ratings yet
- 1-S2.0-S0898122109007263-MainDocument14 pages1-S2.0-S0898122109007263-MainThiago NobreNo ratings yet
- Monte Carlo BasicsDocument23 pagesMonte Carlo BasicsIon IvanNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Data Compression Seminar Scalar Quantizer DesignDocument9 pagesData Compression Seminar Scalar Quantizer DesignJohnKiefferNo ratings yet
- 9 Run Length CodesDocument9 pages9 Run Length CodesJohnKiefferNo ratings yet
- 2 Huffman CodesDocument10 pages2 Huffman CodesJohnKiefferNo ratings yet
- Data Compression Seminar Key ConceptsDocument8 pagesData Compression Seminar Key ConceptsJohnKiefferNo ratings yet
- Fourteen Methods To Triangulate A TetrahedronDocument31 pagesFourteen Methods To Triangulate A TetrahedronJohnKiefferNo ratings yet
- Purposive Communication: Republic of The Philippines Province of Ilocos Sur Ilocos Sur Community College Vigan CityDocument7 pagesPurposive Communication: Republic of The Philippines Province of Ilocos Sur Ilocos Sur Community College Vigan CityLes GasparNo ratings yet
- Generator Honda EP2500CX1Document50 pagesGenerator Honda EP2500CX1Syamsul Bahry HarahapNo ratings yet
- Corporate Governance Committees in India: Key Reports and RecommendationsDocument39 pagesCorporate Governance Committees in India: Key Reports and Recommendationskush mandaliaNo ratings yet
- SPEC 2 - Module 1Document21 pagesSPEC 2 - Module 1Margie Anne ClaudNo ratings yet
- iGCSE Anthology English Language A and English LiteratureDocument25 pagesiGCSE Anthology English Language A and English LiteratureBubbleNo ratings yet
- 2D TransformationDocument38 pages2D TransformationSarvodhya Bahri0% (1)
- Benefics & Malefics ExplanationDocument1 pageBenefics & Malefics ExplanationkrastromanNo ratings yet
- 2019-Kubelka-Munk Double Constant Theory of Digital Rotor Spun Color Blended YarnDocument6 pages2019-Kubelka-Munk Double Constant Theory of Digital Rotor Spun Color Blended YarnyuNo ratings yet
- Learning and Teaching in The Clinical EnvironmentDocument4 pagesLearning and Teaching in The Clinical EnvironmentDaniel Alejandro Lozano MorenoNo ratings yet
- Oracle VMDocument243 pagesOracle VMАскандар Каландаров100% (1)
- Salary Survey (Hong Kong) - 2022Document7 pagesSalary Survey (Hong Kong) - 2022Nathan SmithNo ratings yet
- Office AutomationDocument12 pagesOffice AutomationMad GirlNo ratings yet
- Macroeconomics: University of Economics Ho Chi Minh CityDocument193 pagesMacroeconomics: University of Economics Ho Chi Minh CityNguyễn Văn GiápNo ratings yet
- Complete Notes On 9th Physics by Asif RasheedDocument82 pagesComplete Notes On 9th Physics by Asif RasheedAsif Rasheed Rajput75% (28)
- Polysemy Types ExplainedDocument13 pagesPolysemy Types ExplainedнастяNo ratings yet
- Cooper Tire Warranty InformationDocument28 pagesCooper Tire Warranty InformationAbdulAziz AlGhamdiNo ratings yet
- Csir - CimfrDocument31 pagesCsir - Cimfrshravan kumarNo ratings yet
- 0000 0000 0335Document40 pages0000 0000 0335Hari SetiawanNo ratings yet
- Key Responsibilities On Skill.: Curriculum Vitae PersonalDocument3 pagesKey Responsibilities On Skill.: Curriculum Vitae PersonalLAM NYAWALNo ratings yet