You might also like
- Forecasting and Predictive Analytics With Forecast X 7th Edition Keating Solutions ManualDocument12 pagesForecasting and Predictive Analytics With Forecast X 7th Edition Keating Solutions ManualHeatherGoodwinyaine100% (17)
- Teachers Book - Smarty 4 PDFDocument77 pagesTeachers Book - Smarty 4 PDFFlorenciaRivichini50% (2)
- 22-02-13 Samsung Answer To Staton Techniya Complaint & CounterclaimsDocument72 pages22-02-13 Samsung Answer To Staton Techniya Complaint & CounterclaimsFlorian MuellerNo ratings yet
- How To Calculate Sample SizeDocument6 pagesHow To Calculate Sample SizeGayan Saranga Sumathipala100% (3)
- August Morning WorkDocument20 pagesAugust Morning Workapi-471325484No ratings yet
- SABS Standards and Their Relevance to Conveyor SpecificationsDocument17 pagesSABS Standards and Their Relevance to Conveyor SpecificationsRobert Nicodemus Pelupessy0% (1)
- Customer: Id Email Password Name Street1 Street2 City State Zip Country Phone TempkeyDocument37 pagesCustomer: Id Email Password Name Street1 Street2 City State Zip Country Phone TempkeyAgus ChandraNo ratings yet
- RADEMAKER) Sophrosyne and The Rhetoric of Self-RestraintDocument392 pagesRADEMAKER) Sophrosyne and The Rhetoric of Self-RestraintLafayers100% (2)
- Choosing the Right Metric: Accuracy, Precision, Recall or F1Document9 pagesChoosing the Right Metric: Accuracy, Precision, Recall or F1PRINCE HRIDAYALANKARNo ratings yet
- EvaluationQuestions Class 10 AiDocument6 pagesEvaluationQuestions Class 10 AikritavearnNo ratings yet
- Confusion Matrix Machine LearningDocument9 pagesConfusion Matrix Machine Learningyordanos birhanuNo ratings yet
- Evaluating A Machine Learning ModelDocument14 pagesEvaluating A Machine Learning ModelJeanNo ratings yet
- EVALUATIONDocument4 pagesEVALUATIONVarsha SinghNo ratings yet
- Interpreting Performance Measures for Classification ModelsDocument5 pagesInterpreting Performance Measures for Classification ModelsFriday JonesNo ratings yet
- 10 Ai Evaluation tp01Document5 pages10 Ai Evaluation tp01tanjirouchihams12No ratings yet
- Cbse - Department of Skill Education Artificial IntelligenceDocument12 pagesCbse - Department of Skill Education Artificial IntelligenceNipun SharmaNo ratings yet
- Do Not Fall into These Financial Back-Testing TrapsDocument18 pagesDo Not Fall into These Financial Back-Testing TrapsdroolingpandaNo ratings yet
- Machine Learning QuestionsDocument19 pagesMachine Learning QuestionsMojdeh SoltaniNo ratings yet
- 41 Machine Learning Interview QuestionDocument21 pages41 Machine Learning Interview QuestionJeeva VenkatramanNo ratings yet
- Working Out Coursework PercentagesDocument6 pagesWorking Out Coursework Percentagesafiwjsazh100% (2)
- Essential ML Interview QuestionsDocument21 pagesEssential ML Interview QuestionsSowrya ReganaNo ratings yet
- Classification Metrics in Machine LearningDocument6 pagesClassification Metrics in Machine Learningxlnc1No ratings yet
- Data Science Unit 5Document11 pagesData Science Unit 5Hanuman JyothiNo ratings yet
- What Is Evaluation ?: PredictionDocument7 pagesWhat Is Evaluation ?: Predictionrokesh choudharyNo ratings yet
- Confusion MatrixDocument5 pagesConfusion MatrixretnoNo ratings yet
- CS305 Exercise 5: Task 1: Comparing Machine Learning AlgorithmsDocument7 pagesCS305 Exercise 5: Task 1: Comparing Machine Learning Algorithmsramgoog71No ratings yet
- Data Science Interview Questions (#Day11) PDFDocument11 pagesData Science Interview Questions (#Day11) PDFSahil Goutham100% (1)
- F1 vs ROC AUC vs Accuracy vs PR AUC: When to Use Each Evaluation MetricDocument1 pageF1 vs ROC AUC vs Accuracy vs PR AUC: When to Use Each Evaluation Metriccool_spNo ratings yet
- Natural Language ProcessingDocument11 pagesNatural Language ProcessingDivya NegiNo ratings yet
- MBA Student Cover Letter Detailing Career in Business Development, Customer Service and Technical SupportDocument5 pagesMBA Student Cover Letter Detailing Career in Business Development, Customer Service and Technical SupportJyoti Arvind PathakNo ratings yet
- 04 Evaluation Revision NotesDocument5 pages04 Evaluation Revision NotesD.PAVITHRANTHANNo ratings yet
- ML Interviw QuestionsDocument11 pagesML Interviw Questions618Vishwajit PawarNo ratings yet
- Significant Figures Homework SheetDocument6 pagesSignificant Figures Homework Sheettqkacshjf100% (1)
- 3 Big Mistakes of Backtesting - Overfitting - Look-Ahead-Bias - PhackingDocument5 pages3 Big Mistakes of Backtesting - Overfitting - Look-Ahead-Bias - PhackingTomNo ratings yet
- Machine Learning WorkflowDocument2 pagesMachine Learning WorkflowBrian JonesNo ratings yet
- Ten Common Analytic MistakesDocument12 pagesTen Common Analytic MistakesRAGOS Jeffrey Miguel P.No ratings yet
- The Three Golden Rules of Market Sizing AreDocument5 pagesThe Three Golden Rules of Market Sizing AreTogap SiahaanNo ratings yet
- Exercise 5Document8 pagesExercise 5Aura LòpezNo ratings yet
- Machine Learning Methods Potential PDFDocument10 pagesMachine Learning Methods Potential PDFJohn ValverdeNo ratings yet
- Managing Your Data Science Projects: Learn Salesmanship, Presentation, and Maintenance of Completed ModelsFrom EverandManaging Your Data Science Projects: Learn Salesmanship, Presentation, and Maintenance of Completed ModelsNo ratings yet
- Examples of Sets in Real LifeDocument12 pagesExamples of Sets in Real LifeHania AltafNo ratings yet
- Level 1 Review Quantitative Methods: Study Session 2Document4 pagesLevel 1 Review Quantitative Methods: Study Session 2Matheus AugustoNo ratings yet
- 120 Interview QuestionsDocument19 pages120 Interview Questionssjbladen83% (12)
- Lesson3. Be A Critical ThinkerDocument7 pagesLesson3. Be A Critical Thinker레댕No ratings yet
- Classification Accuracy Logarithmic Loss Confusion Matrix Area Under Curve F1 Score Mean Absolute ErrorDocument9 pagesClassification Accuracy Logarithmic Loss Confusion Matrix Area Under Curve F1 Score Mean Absolute ErrorHarpreet Singh BaggaNo ratings yet
- Stat Ess Mod 3 Ses 1Document29 pagesStat Ess Mod 3 Ses 1Akila100% (1)
- Mei c3 Coursework Numerical MethodsDocument5 pagesMei c3 Coursework Numerical Methodsuyyjcvvcf100% (2)
- Machine Learning Project Example - Building A Model Step-By-Step PDFDocument9 pagesMachine Learning Project Example - Building A Model Step-By-Step PDFSrinivasKannanNo ratings yet
- Ict Coursework s05.1Document4 pagesIct Coursework s05.1jxaeizhfg100% (2)
- DefinitiveGuideToTheMcKinseyProblemSolvingTest2 PDFDocument14 pagesDefinitiveGuideToTheMcKinseyProblemSolvingTest2 PDFMinhDuongNo ratings yet
- Reflection On EstimationDocument5 pagesReflection On Estimationarhaanadlakha5No ratings yet
- Business Case Analysis with R: Simulation Tutorials to Support Complex Business DecisionsFrom EverandBusiness Case Analysis with R: Simulation Tutorials to Support Complex Business DecisionsNo ratings yet
- Model Evaluation TechniquesDocument20 pagesModel Evaluation TechniquesZeeshan TariqNo ratings yet
- Marketing Analytics Price and PromotionDocument90 pagesMarketing Analytics Price and PromotionnahuelymartinNo ratings yet
- Are Dilbert's Colleagues Really Out FishingDocument9 pagesAre Dilbert's Colleagues Really Out FishingAkhil chandranNo ratings yet
- 7 Steps Machine Learning SuccessDocument14 pages7 Steps Machine Learning SuccessGimme DunlodsNo ratings yet
- How To Give Perfect Interview Answers Every TimeDocument15 pagesHow To Give Perfect Interview Answers Every Timechuaychar50% (2)
- Statistics Coursework HelpDocument8 pagesStatistics Coursework Helpf6a5mww8100% (2)
- Machine Learning Models: by Mayuri BhandariDocument48 pagesMachine Learning Models: by Mayuri BhandarimayuriNo ratings yet
- Statistical ModelingDocument19 pagesStatistical ModelingAnonymous PKVCsGNo ratings yet
- Web Metrics DemystifiedDocument7 pagesWeb Metrics Demystifiedbeach musicianNo ratings yet
- Regression: An Introduction To EconometricsDocument19 pagesRegression: An Introduction To EconometricsCorovei EmiliaNo ratings yet
- Assessing and Improving Prediction and Classification: Theory and Algorithms in C++From EverandAssessing and Improving Prediction and Classification: Theory and Algorithms in C++No ratings yet
- The Truth About Surveys: Getting Paid for Your Opinions (& Other Micro-Task Opportunities) Harmful Scam - OR - Legitimate Income-Producing Work?: The Truth About Everything by Molly Mapenthorpe, #4From EverandThe Truth About Surveys: Getting Paid for Your Opinions (& Other Micro-Task Opportunities) Harmful Scam - OR - Legitimate Income-Producing Work?: The Truth About Everything by Molly Mapenthorpe, #4No ratings yet
- An Introduction To ROC AnalysisDocument14 pagesAn Introduction To ROC AnalysisTrần Anh Tú100% (1)
- Cross-Validation For Detecting and Preventing OverfittingDocument63 pagesCross-Validation For Detecting and Preventing OverfittingnathanlgrossmanNo ratings yet
- Cross Validation Explained: Evaluating ML ModelsDocument8 pagesCross Validation Explained: Evaluating ML ModelsnathanlgrossmanNo ratings yet
- Binary Cross Entropy - Log LossDocument12 pagesBinary Cross Entropy - Log LossnathanlgrossmanNo ratings yet
- A Note On Using The F-MeasureDocument10 pagesA Note On Using The F-MeasurenathanlgrossmanNo ratings yet
- The Original Meaning of 'Natural Born'Document48 pagesThe Original Meaning of 'Natural Born'nathanlgrossmanNo ratings yet
- A K-fold Averaging Cross-validation Procedure Reduces VarianceDocument22 pagesA K-fold Averaging Cross-validation Procedure Reduces VariancenathanlgrossmanNo ratings yet
- A K-fold Averaging Cross-validation Procedure Reduces VarianceDocument22 pagesA K-fold Averaging Cross-validation Procedure Reduces VariancenathanlgrossmanNo ratings yet
- English Common Law in The United StatesDocument26 pagesEnglish Common Law in The United StatesnathanlgrossmanNo ratings yet
- P 797Document6 pagesP 797Arya PratamaNo ratings yet
- The Common Law in The American Legal SystemDocument20 pagesThe Common Law in The American Legal Systemnathanlgrossman100% (1)
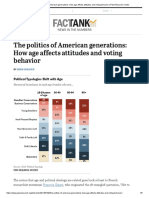
- The Politics of American Generations - How Age Affects Attitudes and Voting BehaviorDocument5 pagesThe Politics of American Generations - How Age Affects Attitudes and Voting BehaviornathanlgrossmanNo ratings yet
- The Mexica Didn't Believe The Conquistadors Were GodsDocument6 pagesThe Mexica Didn't Believe The Conquistadors Were GodsnathanlgrossmanNo ratings yet
- Sample Size Estimation in Prevalence Studies PDFDocument8 pagesSample Size Estimation in Prevalence Studies PDFnathanlgrossmanNo ratings yet
- Ficha de Seguridad Dispositivo Pruba Doble Recamara 2875 - 2876Document133 pagesFicha de Seguridad Dispositivo Pruba Doble Recamara 2875 - 2876janetth rubianoNo ratings yet
- gr12 15jan19 The Prophetic Methodology in Health Care LessonpDocument3 pagesgr12 15jan19 The Prophetic Methodology in Health Care Lessonpzarah jiyavudeenNo ratings yet
- Mitspeck 2014 e VersionDocument130 pagesMitspeck 2014 e VersionVedantDomkondekarNo ratings yet
- Filipinism 3Document3 pagesFilipinism 3Shahani Cel MananayNo ratings yet
- Tutorial Chapter 1 Thermochemistry QuestionsDocument4 pagesTutorial Chapter 1 Thermochemistry Questionssiti nur masyitah nasaruddinNo ratings yet
- Crankcase Pressure SM019901095211 - en PDFDocument5 pagesCrankcase Pressure SM019901095211 - en PDFDavy GonzalezNo ratings yet
- Impact of Microfinance On Women's Empowerment: A Case Study On Two Microfinance Institutions in Sri LankaDocument11 pagesImpact of Microfinance On Women's Empowerment: A Case Study On Two Microfinance Institutions in Sri Lankamandala jyoshnaNo ratings yet
- User Manual: Smart Alarm System & AppDocument41 pagesUser Manual: Smart Alarm System & AppEduardo Jose Fernandez PedrozaNo ratings yet
- Circuit Diagram Eng 5582-2-01Document95 pagesCircuit Diagram Eng 5582-2-01edolzaNo ratings yet
- Nucleus ERPDocument3 pagesNucleus ERPdimensionone1No ratings yet
- Java Pattern Programming AssignmentsDocument9 pagesJava Pattern Programming Assignmentstamj tamjNo ratings yet
- Laser PsicosegundoDocument14 pagesLaser PsicosegundoCristiane RalloNo ratings yet
- BOYSEN® Marmorino™ Italian Marble Finish: Liters UseDocument1 pageBOYSEN® Marmorino™ Italian Marble Finish: Liters UseJohn Ray Esmama CalasicasNo ratings yet
- Bi006008 00 02 - Body PDFDocument922 pagesBi006008 00 02 - Body PDFRamon HidalgoNo ratings yet
- Proportional Valves: Adjustment ProcedureDocument11 pagesProportional Valves: Adjustment Procedureyaniprasetyo12No ratings yet
- EXPERIMENT 4B - HOW STRONG IS YOUR CHOCOLATE - Docx - 2014538817Document6 pagesEXPERIMENT 4B - HOW STRONG IS YOUR CHOCOLATE - Docx - 2014538817Shekaina Joy Wansi ManadaoNo ratings yet
- The Effective of Geothermal Energy in BuDocument8 pagesThe Effective of Geothermal Energy in BuMeziane YkhlefNo ratings yet
- 1 National Workshop For Sustainable Built Environment South - South PartnershipDocument14 pages1 National Workshop For Sustainable Built Environment South - South PartnershipRajendra KunwarNo ratings yet
- Manual HandlingDocument14 pagesManual Handlingkacang mete100% (1)
- 3 6 17weekly Homework Sheet Week 23 - 5th Grade - CcssDocument3 pages3 6 17weekly Homework Sheet Week 23 - 5th Grade - Ccssapi-328344919No ratings yet
- Node - Js 8 The Right Way: Extracted FromDocument11 pagesNode - Js 8 The Right Way: Extracted FromRodrigo Románovich FiodorovichNo ratings yet
- Chapter 5 PresentationDocument35 pagesChapter 5 PresentationSabeur Dammak100% (1)
- K220 Accessories BrochureDocument6 pagesK220 Accessories Brochurehh8g9y6ggcNo ratings yet
- Sta. Rosa, Lapu-Lapu City, Cebu PhilippinesDocument8 pagesSta. Rosa, Lapu-Lapu City, Cebu PhilippinesMet XiiNo ratings yet