You might also like
- Ventura 2012Document10 pagesVentura 2012Portgas D AceNo ratings yet
- A Review On Video and Image Defogging Algorithms Image Restoration EnhancementDocument4 pagesA Review On Video and Image Defogging Algorithms Image Restoration EnhancementerpublicationNo ratings yet
- A Real-Time Panoramic Vision System For AutonomousDocument8 pagesA Real-Time Panoramic Vision System For AutonomousMatthew Kevin KumarNo ratings yet
- Li Lets See Clearly Contaminant Artifact Removal For Moving Cameras ICCV 2021 PaperDocument10 pagesLi Lets See Clearly Contaminant Artifact Removal For Moving Cameras ICCV 2021 PaperPS InnovationsNo ratings yet
- Unsupervised Learning of Depth and Ego-Motion From VideoDocument10 pagesUnsupervised Learning of Depth and Ego-Motion From VideoSagar URNo ratings yet
- 6416 978-1-5386-7150-4/18/$31.00 ©2018 Ieee Igarss 2018Document4 pages6416 978-1-5386-7150-4/18/$31.00 ©2018 Ieee Igarss 2018Uppuluri Lalitha MadhuriNo ratings yet
- Preprints202308 1425 v1Document17 pagesPreprints202308 1425 v1Maharani SwistaNo ratings yet
- Carnegie Mellon: Department of Electrical and Computer EngineeringDocument35 pagesCarnegie Mellon: Department of Electrical and Computer Engineeringanunay_scribdNo ratings yet
- 1 s2.0 S0165168422001979 MainDocument14 pages1 s2.0 S0165168422001979 MainFlying AVANo ratings yet
- Paper 19-Feature Descriptor Based On Normalized CornersDocument7 pagesPaper 19-Feature Descriptor Based On Normalized CornersItms HamandyNo ratings yet
- FYP Project Report For PlagiarismDocument47 pagesFYP Project Report For PlagiarismTouseef SattiNo ratings yet
- Campus Virtual Tour System Based On Cylindric PanoramaDocument6 pagesCampus Virtual Tour System Based On Cylindric Panorama161080200132 Moch. Bagus SetiawanNo ratings yet
- Underwater Computer Vision: Exploring the Depths of Computer Vision Beneath the WavesFrom EverandUnderwater Computer Vision: Exploring the Depths of Computer Vision Beneath the WavesNo ratings yet
- REF 5 Lxy - IEEE-2010Document9 pagesREF 5 Lxy - IEEE-2010subhasaranya259No ratings yet
- 32 Digital Image Processing - 1Document17 pages32 Digital Image Processing - 1Sirisha KhaspaNo ratings yet
- LEVIA2020 Image Synthesis Pipeline For Surface InspectionDocument9 pagesLEVIA2020 Image Synthesis Pipeline For Surface Inspectionkidsfunlearning kidsfunlearningNo ratings yet
- Direction Oriented Fast Iterative Block Based Video Inpainting Using Morphological Operations and SSDDocument10 pagesDirection Oriented Fast Iterative Block Based Video Inpainting Using Morphological Operations and SSDShanmuganathan V (RC2113003011029)No ratings yet
- Practical 3D Tracking Using Low-Cost Cameras: Roman Barták, Michal Koutný, David ObdržálekDocument2 pagesPractical 3D Tracking Using Low-Cost Cameras: Roman Barták, Michal Koutný, David ObdržálekBENLAHRECH Djamal EddNo ratings yet
- Scene Modelling, Recognition and Tracking With Invariant Image FeaturesDocument10 pagesScene Modelling, Recognition and Tracking With Invariant Image FeaturesMohamad GhafariNo ratings yet
- Synchronization and Rolling Shutter Compensation For Consumer Video Camera ArraysDocument8 pagesSynchronization and Rolling Shutter Compensation For Consumer Video Camera ArraysCarlos HumbertoNo ratings yet
- 3autonomous CarDocument11 pages3autonomous CarJaya KumarNo ratings yet
- Instant 3D Photography: Peter Hedman, Johannes KopfDocument12 pagesInstant 3D Photography: Peter Hedman, Johannes KopfAvinash MallickNo ratings yet
- Aggarwal Panoramic Stereo Videos CVPR 2016 PaperDocument9 pagesAggarwal Panoramic Stereo Videos CVPR 2016 PaperTestNo ratings yet
- Multi View Environment - Fuhrmann-2014-MVEDocument8 pagesMulti View Environment - Fuhrmann-2014-MVES GuruNo ratings yet
- Iccv 2005 86Document8 pagesIccv 2005 86zhaobingNo ratings yet
- Applica - Tion of Image Processing Techniques in Computer Graphics AlgorithmsDocument10 pagesApplica - Tion of Image Processing Techniques in Computer Graphics AlgorithmsCharu SharmaNo ratings yet
- 2 - Two Rough UserDocument11 pages2 - Two Rough UserLê TườngNo ratings yet
- Progressive 3D Reconstruction of Infrastructure With VideogrammetryDocument12 pagesProgressive 3D Reconstruction of Infrastructure With VideogrammetryRaju RaraNo ratings yet
- By Reinhard Koch, Marc Pollefeys and Luc Van GoolDocument13 pagesBy Reinhard Koch, Marc Pollefeys and Luc Van GoolFatin KhairudinNo ratings yet
- Motion Detection Application Using Web CameraDocument3 pagesMotion Detection Application Using Web CameraIlham ClinkersNo ratings yet
- Simple, Accurate, and Robust Projector-Camera CalibrationDocument8 pagesSimple, Accurate, and Robust Projector-Camera CalibrationJosue MelongNo ratings yet
- Oski Per 2013Document10 pagesOski Per 2013Alex PavloffNo ratings yet
- Cascaded Light Propagation Volumes For Real-Time Indirect IlluminationDocument9 pagesCascaded Light Propagation Volumes For Real-Time Indirect IlluminationmfbaranowNo ratings yet
- Capnet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D SupervisionDocument8 pagesCapnet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D SupervisionArmandoNo ratings yet
- Deep Multimodality Learning For UAV Video Aesthetic Quality AssessmentDocument12 pagesDeep Multimodality Learning For UAV Video Aesthetic Quality AssessmentXin JinNo ratings yet
- Recognition of Front and Rear IJEIR-13Document4 pagesRecognition of Front and Rear IJEIR-13Vivek DeshmukhNo ratings yet
- SVO: Semi-Direct Visual Odometry For Monocular and Multi-Camera SystemsDocument18 pagesSVO: Semi-Direct Visual Odometry For Monocular and Multi-Camera SystemsMike AlonsoNo ratings yet
- User-Perspective Augmented Reality Magic Lens From GradientsDocument10 pagesUser-Perspective Augmented Reality Magic Lens From GradientsgabrieliamNo ratings yet
- SFM MVS PhotoScan Image Processing ExercDocument24 pagesSFM MVS PhotoScan Image Processing Exercgorgo_elsucioNo ratings yet
- Making One Object Look Like Another Controlling Appearance Using A Projector-Camera SystemDocument8 pagesMaking One Object Look Like Another Controlling Appearance Using A Projector-Camera SystemXitocranNo ratings yet
- (Yuan2018) Image Haze Removal Via Reference Retrieval and Scene PriorDocument15 pages(Yuan2018) Image Haze Removal Via Reference Retrieval and Scene PriorK SavitriNo ratings yet
- Lee 3D Video Stabilization With Depth Estimation by CNN-Based Optimization CVPR 2021 PaperDocument10 pagesLee 3D Video Stabilization With Depth Estimation by CNN-Based Optimization CVPR 2021 PaperArmandoNo ratings yet
- KinectFusion For Faces Real-Time 3D Face Tracking and Modeling Using A Kinect Camera For A Markerless AR SystemDocument6 pagesKinectFusion For Faces Real-Time 3D Face Tracking and Modeling Using A Kinect Camera For A Markerless AR Systemcabeça dos gamesNo ratings yet
- Sinha Sig Graph Asia 08Document10 pagesSinha Sig Graph Asia 08jimakosjpNo ratings yet
- Unsupervised Loop ClosureDocument10 pagesUnsupervised Loop ClosureGeorge PachitariuNo ratings yet
- Mobile 3d ReconDocument11 pagesMobile 3d ReconShaerman ChenNo ratings yet
- First-Person Hyper-Lapse VideosDocument10 pagesFirst-Person Hyper-Lapse VideosInduchoodan RajendranNo ratings yet
- Rotoscoping Appearance ModelsDocument9 pagesRotoscoping Appearance ModelsNeerajNo ratings yet
- Monocular Vision For Mobile Robot Localization and Autonomous NavigationDocument24 pagesMonocular Vision For Mobile Robot Localization and Autonomous NavigationJeanchristophe1996No ratings yet
- Turning Mobile Phones Into 3D ScannersDocument8 pagesTurning Mobile Phones Into 3D ScannersFilippo CostanzoNo ratings yet
- Areial ImageDocument84 pagesAreial ImageudayszNo ratings yet
- Key TRDocument10 pagesKey TRqwertyNo ratings yet
- On Computer Vision For Augmented RealityDocument4 pagesOn Computer Vision For Augmented RealityAditya IyerNo ratings yet
- Pottier 2023 Meas. Sci. Technol. 34 075001Document17 pagesPottier 2023 Meas. Sci. Technol. 34 075001Basil Azeem ed20b009No ratings yet
- Practical SVBRDF Capture in The Frequency DomainDocument12 pagesPractical SVBRDF Capture in The Frequency DomainZStepan11No ratings yet
- True Orthophoto Generation From Uav Images Implementation ofDocument7 pagesTrue Orthophoto Generation From Uav Images Implementation ofHolman Latorre BossaNo ratings yet
- Photo Reality Capture For Preliminary Infrastructure Design WebDocument16 pagesPhoto Reality Capture For Preliminary Infrastructure Design WebjausingchiNo ratings yet
- PanoWS Dresden2004 ChapmanDocument8 pagesPanoWS Dresden2004 Chapmanchandrasekhar71No ratings yet
- End-To-End Optimization of Optics and Image Processing For Achromatic Extended Depth of Field and Super-Resolution ImagingDocument13 pagesEnd-To-End Optimization of Optics and Image Processing For Achromatic Extended Depth of Field and Super-Resolution ImagingJ SpencerNo ratings yet
- Orthomosaic From Generating 3D Models With PhotogrammetryDocument13 pagesOrthomosaic From Generating 3D Models With PhotogrammetryInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Maytag MDG30 MDG50 MDG75 PNH SpecificationsDocument2 pagesMaytag MDG30 MDG50 MDG75 PNH Specificationsmairimsp2003No ratings yet
- How To Automatically Backup phpMyAdmin - SQLBackupAndFTP's BlogDocument6 pagesHow To Automatically Backup phpMyAdmin - SQLBackupAndFTP's BlogIbn KhaledNo ratings yet
- No. 304 (171) 2021/PA Admn 111!: To, Centre ExcellenceDocument9 pagesNo. 304 (171) 2021/PA Admn 111!: To, Centre ExcellenceSanjeev kumarNo ratings yet
- Common Hydraulic Problems - Symptoms and Causes - Hydraproducts - Hydraulic Systems - Hydraulic Power Packs - BlogDocument3 pagesCommon Hydraulic Problems - Symptoms and Causes - Hydraproducts - Hydraulic Systems - Hydraulic Power Packs - BlogLacatusu MirceaNo ratings yet
- (Supervisor) Assistant Professor, E.C.E Department Gitam, VisakhapatnamDocument14 pages(Supervisor) Assistant Professor, E.C.E Department Gitam, VisakhapatnamG Sankara raoNo ratings yet
- Md. Shahriar Haque Mithun: GPH Ispat LimitedDocument3 pagesMd. Shahriar Haque Mithun: GPH Ispat LimitedMd. Shahriar haque mithunNo ratings yet
- Power Learning Strategies Success College Life 7th Edition Feldman Test BankDocument24 pagesPower Learning Strategies Success College Life 7th Edition Feldman Test BankKathyHernandeznobt100% (32)
- EENG226 Lab1 PDFDocument5 pagesEENG226 Lab1 PDFSaif HassanNo ratings yet
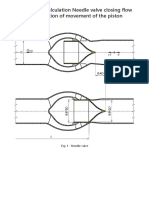
- Hydrodynamic Calculation Needle Valve Closing Flow Against The Direction of Movement of The PistonDocument23 pagesHydrodynamic Calculation Needle Valve Closing Flow Against The Direction of Movement of The Pistonmet-calcNo ratings yet
- MS Disc Brake CaliperDocument2 pagesMS Disc Brake Caliperghgh140No ratings yet
- M580 HSBY System Planning GuideDocument217 pagesM580 HSBY System Planning GuideISLAMIC LECTURESNo ratings yet
- Elisee - 150 Service ManualDocument176 pagesElisee - 150 Service ManualDawoodNo ratings yet
- BiyDaalt2+OpenMP - Ipynb - ColaboratoryDocument3 pagesBiyDaalt2+OpenMP - Ipynb - ColaboratoryAngarag G.No ratings yet
- Lab 521Document8 pagesLab 521Shashitharan PonnambalanNo ratings yet
- Catamsia 9.0 Cara InstallDocument2 pagesCatamsia 9.0 Cara InstalljohnsonNo ratings yet
- Ethical Hacking DissertationDocument5 pagesEthical Hacking DissertationWriteMyPapersUK100% (1)
- G95me c10 5Document4 pagesG95me c10 5KyinaNo ratings yet
- Seminar3 enDocument7 pagesSeminar3 enandreiNo ratings yet
- Reflection PaperDocument2 pagesReflection PaperKatrina DeveraNo ratings yet
- As 3850-2003 Tilt-Up Concrete ConstructionDocument8 pagesAs 3850-2003 Tilt-Up Concrete ConstructionSAI Global - APACNo ratings yet
- Lesson 2Document10 pagesLesson 2Anore James IvanNo ratings yet
- Jun Jul 2021Document32 pagesJun Jul 2021Lai Kok UeiNo ratings yet
- Outreach in FIRST LEGO LeagueDocument10 pagesOutreach in FIRST LEGO LeagueΑνδρέας ΜήταλαςNo ratings yet
- Dx225lca-2 InglesDocument12 pagesDx225lca-2 InglesredwiolNo ratings yet
- Juhi S. Khandekar: Email ID: Contact (M) : +91-7710007972Document1 pageJuhi S. Khandekar: Email ID: Contact (M) : +91-7710007972Reddi SyamsundarNo ratings yet
- Chapter 2 PurposiveDocument3 pagesChapter 2 PurposiveVenus BarnuevoNo ratings yet
- PSP Student Workbook.20061007.Release NotesDocument1 pagePSP Student Workbook.20061007.Release NoteszombiennNo ratings yet
- Dictionaries Godot GDScript Tutorial Ep 12 Godot TutorialsDocument4 pagesDictionaries Godot GDScript Tutorial Ep 12 Godot TutorialsChris LewinskyNo ratings yet
- 5 HANDGREPEN 1 Horizon - Eng - 0Document28 pages5 HANDGREPEN 1 Horizon - Eng - 0FORLINE nuiNo ratings yet
- Ab 521 Requirements For Engineered Pressure EnclosuresDocument39 pagesAb 521 Requirements For Engineered Pressure EnclosuresCarlos Maldonado SalazarNo ratings yet