You might also like
- GozieDocument24 pagesGozieEzeh Samuel ElochukwuNo ratings yet
- Intelligent Sales Prediction Using Machine Learning TechniquesDocument6 pagesIntelligent Sales Prediction Using Machine Learning Techniquesshabir AhmadNo ratings yet
- BigMart sales forecast using MLDocument5 pagesBigMart sales forecast using MLvikas gaurNo ratings yet
- IJRPR6647Document4 pagesIJRPR6647Anas AhmadNo ratings yet
- An Advanced Sales Forecasting Using Machine Learning AlgorithmDocument4 pagesAn Advanced Sales Forecasting Using Machine Learning AlgorithmInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Machine-Learning Models For Sales Time Series Forecasting: Bohdan M. PavlyshenkoDocument11 pagesMachine-Learning Models For Sales Time Series Forecasting: Bohdan M. PavlyshenkoognjanovicNo ratings yet
- Machine-Learning Models For Sales Time Series Forecasting: Bohdan M. PavlyshenkoDocument11 pagesMachine-Learning Models For Sales Time Series Forecasting: Bohdan M. PavlyshenkoJohnson BezawadaNo ratings yet
- Machine-Learning Models For Sales Time Series Forecasting: Bohdan M. PavlyshenkoDocument11 pagesMachine-Learning Models For Sales Time Series Forecasting: Bohdan M. PavlyshenkoognjanovicNo ratings yet
- Grid Search Optimization (GSO) Based Future Sales Prediction For Big MartDocument7 pagesGrid Search Optimization (GSO) Based Future Sales Prediction For Big Martimrul emonNo ratings yet
- Xaviers Institute of Business Management Studies Sub: Operation ManagementDocument22 pagesXaviers Institute of Business Management Studies Sub: Operation Managementsyed tanseerNo ratings yet
- $RABL8HQDocument8 pages$RABL8HQshivani kumariNo ratings yet
- Time Series For Retail StoreDocument10 pagesTime Series For Retail Storekislaya kumarNo ratings yet
- Chapter One 1.1 Background of The StudyDocument3 pagesChapter One 1.1 Background of The StudyHenry FineboneNo ratings yet
- Sales Forecasting: A Practical & Proven Guide to Strategic Sales ForecastingFrom EverandSales Forecasting: A Practical & Proven Guide to Strategic Sales ForecastingNo ratings yet
- Predictive Analytics - Chapter 1 PDFDocument10 pagesPredictive Analytics - Chapter 1 PDFDeniece C. CastilloNo ratings yet
- Intelligent Sales Prediction Using Machine Learning TechniquesDocument7 pagesIntelligent Sales Prediction Using Machine Learning TechniquesAkhiyar WaladiNo ratings yet
- Virtual Supply Chain Front-End, Back-End and Integration IssuesDocument23 pagesVirtual Supply Chain Front-End, Back-End and Integration IssuesDaniel Stiven TamayoNo ratings yet
- 009 Praveen NCDST503Document8 pages009 Praveen NCDST503Kalaivani VNo ratings yet
- Sales Prediction Using Machine Learning: R. Praveen D. Praveen Kumar A. Prince Sam and G. Sivakama SundariDocument8 pagesSales Prediction Using Machine Learning: R. Praveen D. Praveen Kumar A. Prince Sam and G. Sivakama SundariKalaivani VNo ratings yet
- ConclusionsPaper IMA India TechRupt Workshop March 2022Document21 pagesConclusionsPaper IMA India TechRupt Workshop March 2022aaNo ratings yet
- Collaborative Demand Planning: For Profit-Driven Supply ChainsDocument10 pagesCollaborative Demand Planning: For Profit-Driven Supply Chainsvenu212No ratings yet
- Rework B31632V1+Document10 pagesRework B31632V1+Ramanpreet KaurNo ratings yet
- Chapter 1: Introduction: 1.1 Background TheoryDocument36 pagesChapter 1: Introduction: 1.1 Background TheoryBe-fit Be-strongNo ratings yet
- Forecasting Methods DiaryDocument5 pagesForecasting Methods Diaryashish sunnyNo ratings yet
- Cost Estimation in Agile Software Development: Utilizing Functional Size Measurement MethodsFrom EverandCost Estimation in Agile Software Development: Utilizing Functional Size Measurement MethodsNo ratings yet
- Business AnalyticsDocument5 pagesBusiness AnalyticsGovardhan VNo ratings yet
- Pricing Decision Support SystemsDocument19 pagesPricing Decision Support SystemsYasemin OzcanNo ratings yet
- A Prognostic Examination For Big Mart VendingDocument7 pagesA Prognostic Examination For Big Mart VendingIJRASETPublicationsNo ratings yet
- The Six Sigma Method: Boost quality and consistency in your businessFrom EverandThe Six Sigma Method: Boost quality and consistency in your businessRating: 3 out of 5 stars3/5 (2)
- Easychair Preprint: Archit BansalDocument8 pagesEasychair Preprint: Archit Bansalferdyanta_sitepuNo ratings yet
- Easychair Preprint: Mansi Panjwani, Rahul Ramrakhiani, Hitesh Jumnani, Krishna Zanwar and Rupali HandeDocument9 pagesEasychair Preprint: Mansi Panjwani, Rahul Ramrakhiani, Hitesh Jumnani, Krishna Zanwar and Rupali Handeimrul emonNo ratings yet
- Sales Analysis and Forecasting in Shopping Mart: Amit Kumar, Kartik Sharma, Anup Singh, Dravid KumarDocument4 pagesSales Analysis and Forecasting in Shopping Mart: Amit Kumar, Kartik Sharma, Anup Singh, Dravid KumarKartik SharmaNo ratings yet
- A Comparative Study of Various Machine Learning Models On Interval Data A Case Study of Maison Gil Ltd.Document10 pagesA Comparative Study of Various Machine Learning Models On Interval Data A Case Study of Maison Gil Ltd.International Journal of Innovative Science and Research TechnologyNo ratings yet
- Market Research White PaperDocument7 pagesMarket Research White PaperashishkrishNo ratings yet
- Seminar ReportDocument25 pagesSeminar ReportAnas AhmadNo ratings yet
- Graffius Capstone FINISHEDDocument90 pagesGraffius Capstone FINISHEDsandm98No ratings yet
- Chapter 1: Introduction: Overview of Business AnalyticsDocument12 pagesChapter 1: Introduction: Overview of Business AnalyticsShairamay AludinoNo ratings yet
- IoT Domain Analyst Digital Assignment E-R Model and Predictive AnalysisDocument6 pagesIoT Domain Analyst Digital Assignment E-R Model and Predictive AnalysisharshithNo ratings yet
- Role of business analytics in decision makingDocument17 pagesRole of business analytics in decision makingsravaniNo ratings yet
- Unit - V Notes BADocument16 pagesUnit - V Notes BAManish RautNo ratings yet
- The Eight Steps of The Forecasting Process Using Demand Planning SoftwareDocument2 pagesThe Eight Steps of The Forecasting Process Using Demand Planning SoftwareJessee Mburu NyoroNo ratings yet
- AI APPLICATION TO SEGMENTED MARKETINGDocument4 pagesAI APPLICATION TO SEGMENTED MARKETINGjafmanNo ratings yet
- Data Analytics NotesDocument8 pagesData Analytics NotesRamesh Safare100% (2)
- Analytics vs. Analysis: Analytics Is The Discovery, Interpretation, and Communication of Meaningful Patterns inDocument4 pagesAnalytics vs. Analysis: Analytics Is The Discovery, Interpretation, and Communication of Meaningful Patterns inmoonthinkerNo ratings yet
- What Do A Pair of Jeans andDocument10 pagesWhat Do A Pair of Jeans andGirishNo ratings yet
- Business Process Mapping: How to improve customer experience and increase profitability in a post-COVID worldFrom EverandBusiness Process Mapping: How to improve customer experience and increase profitability in a post-COVID worldNo ratings yet
- Explore Big Data to Gain Customer InsightsDocument13 pagesExplore Big Data to Gain Customer InsightsMuhammad FaisalNo ratings yet
- Business @ the Speed of Thought (Review and Analysis of Gates' Book)From EverandBusiness @ the Speed of Thought (Review and Analysis of Gates' Book)Rating: 5 out of 5 stars5/5 (2)
- Big Data: Understanding How Data Powers Big BusinessFrom EverandBig Data: Understanding How Data Powers Big BusinessRating: 2 out of 5 stars2/5 (1)
- Data-Driven Marketing: The 15 Metrics Everyone in Marketing Should KnowFrom EverandData-Driven Marketing: The 15 Metrics Everyone in Marketing Should KnowRating: 4 out of 5 stars4/5 (17)
- Analysis On Ecommerce Platforms Using Marketing Dashboards and Forecasting TechniquesDocument6 pagesAnalysis On Ecommerce Platforms Using Marketing Dashboards and Forecasting TechniquesmafapowuNo ratings yet
- Faculty of Busniess and Management Bachelor in Office System Manangment (BA232) MGT555 Assignment 1 Prepared byDocument13 pagesFaculty of Busniess and Management Bachelor in Office System Manangment (BA232) MGT555 Assignment 1 Prepared byNur Aqilah Shamsul Anuar100% (1)
- 3485-Article Text-6711-1-10-20201223Document20 pages3485-Article Text-6711-1-10-20201223noumanNo ratings yet
- 4298 Gui Ba BG GuideDocument14 pages4298 Gui Ba BG GuideMakendo DestineNo ratings yet
- Optimize Firm Objectives & Forecast DemandDocument2 pagesOptimize Firm Objectives & Forecast DemandedrianclydeNo ratings yet
- Text and Graph Mining Algorithms ExplainedDocument21 pagesText and Graph Mining Algorithms Explainedshabir AhmadNo ratings yet
- Evolutionary Computation: One Project, Many DirectionsDocument2 pagesEvolutionary Computation: One Project, Many Directionsshabir AhmadNo ratings yet
- CS 566 - Evolutionary Computations Paper Critique 1: 1 Summary of Technical ContributionsDocument1 pageCS 566 - Evolutionary Computations Paper Critique 1: 1 Summary of Technical Contributionsshabir AhmadNo ratings yet
- AsmDocument5 pagesAsmshabir AhmadNo ratings yet
- Unit 10 Assignment Brief 2 2018 2019Document3 pagesUnit 10 Assignment Brief 2 2018 2019shabir AhmadNo ratings yet
- S 1Document12 pagesS 1shabir AhmadNo ratings yet
- Public Key Infrastructure by Muhedin Abdullahi MohammedDocument123 pagesPublic Key Infrastructure by Muhedin Abdullahi Mohammedshabir AhmadNo ratings yet
- Computer Support Specialist / First Line Support: The Average SalaryDocument4 pagesComputer Support Specialist / First Line Support: The Average Salaryshabir AhmadNo ratings yet
- Career in CS and ITDocument3 pagesCareer in CS and ITshabir AhmadNo ratings yet
- Non-Dominated Sorting Genetic Algorithm With Numerical Example Step-by-StepDocument185 pagesNon-Dominated Sorting Genetic Algorithm With Numerical Example Step-by-Stepshabir AhmadNo ratings yet
- New Text DocumentDocument4 pagesNew Text Documentshabir AhmadNo ratings yet
- ML 3Document7 pagesML 3shabir AhmadNo ratings yet
- Read MeDocument1 pageRead MeDiego HlchNo ratings yet
- PythonForDataScience Cheatsheet PDFDocument21 pagesPythonForDataScience Cheatsheet PDFGreet Labs100% (2)
- Hands-On Ethical Hacking and Network DefenseDocument74 pagesHands-On Ethical Hacking and Network Defenseمعاذ الصديقNo ratings yet
- How You Can Help Team-FTUDocument1 pageHow You Can Help Team-FTUslavi roomNo ratings yet
- Green Engineering, Process Safety and Inherent Safety: A New ParadigmDocument55 pagesGreen Engineering, Process Safety and Inherent Safety: A New ParadigmAbroo KhattakNo ratings yet
- Make The World A Safer Place With A Career in Cybersecurity: Fit Learning Into Your LifeDocument2 pagesMake The World A Safer Place With A Career in Cybersecurity: Fit Learning Into Your Lifeshabir AhmadNo ratings yet
- Water: Multi-Objective Optimization For Selecting and Siting The Cost-E GWLF Model and NSGAII AlgorithmDocument12 pagesWater: Multi-Objective Optimization For Selecting and Siting The Cost-E GWLF Model and NSGAII Algorithmshabir AhmadNo ratings yet
- NYSDEC WastewaterTreatmentPlants DataDictionaryDocument1 pageNYSDEC WastewaterTreatmentPlants DataDictionaryshabir AhmadNo ratings yet
- NYSDEC WastewaterTreatmentPlants OverviewDocument1 pageNYSDEC WastewaterTreatmentPlants Overviewshabir AhmadNo ratings yet
- Unit 4 NewDocument129 pagesUnit 4 Newshabir AhmadNo ratings yet
- Lecture 2 - ADTsDocument16 pagesLecture 2 - ADTsTalal AhmedNo ratings yet
- LinksDocument1 pageLinksshabir AhmadNo ratings yet
- Chapter 3 - Object Oriented ProgrammingDocument110 pagesChapter 3 - Object Oriented Programmingshabir AhmadNo ratings yet
- 12Document1 page12shabir AhmadNo ratings yet
- Chapter 7 - Arrays SortingDocument32 pagesChapter 7 - Arrays Sortingshabir AhmadNo ratings yet
- NonmadjwwDocument1 pageNonmadjwwshabir AhmadNo ratings yet
- LicenseDocument7 pagesLicenseManni MantasticNo ratings yet
- LicenseDocument7 pagesLicenseManni MantasticNo ratings yet
- Grace Lipsini1 2 3Document4 pagesGrace Lipsini1 2 3api-548923370No ratings yet
- Load Frequency Control of Hydro and Nuclear Power System by PI & GA ControllerDocument6 pagesLoad Frequency Control of Hydro and Nuclear Power System by PI & GA Controllerijsret100% (1)
- Second Quarterly Examination Math 9Document2 pagesSecond Quarterly Examination Math 9Mark Kiven Martinez94% (16)
- ChromosomesDocument24 pagesChromosomesapi-249102379No ratings yet
- spl400 Stereo Power Amplifier ManualDocument4 pagesspl400 Stereo Power Amplifier ManualRichter SiegfriedNo ratings yet
- Getting the Most from Cattle Manure: Proper Application Rates and PracticesDocument4 pagesGetting the Most from Cattle Manure: Proper Application Rates and PracticesRamNocturnalNo ratings yet
- Advanced Presentation Skills: Creating Effective Presentations with Visuals, Simplicity and ClarityDocument15 pagesAdvanced Presentation Skills: Creating Effective Presentations with Visuals, Simplicity and ClarityGilbert TamayoNo ratings yet
- Design ThinkingDocument16 pagesDesign ThinkingbhattanitanNo ratings yet
- Muv PDFDocument6 pagesMuv PDFDenisse PxndithxNo ratings yet
- 96 Amazing Social Media Statistics and FactsDocument19 pages96 Amazing Social Media Statistics and FactsKatie O'BrienNo ratings yet
- Internal Peripherals of Avr McusDocument2 pagesInternal Peripherals of Avr McusKuldeep JashanNo ratings yet
- Document-SAP EWM For Fashion 1.0: 1.general IntroductionDocument3 pagesDocument-SAP EWM For Fashion 1.0: 1.general IntroductionAnonymous u3PhTjWZRNo ratings yet
- Act 1&2 and SAQ No - LawDocument4 pagesAct 1&2 and SAQ No - LawBududut BurnikNo ratings yet
- Electrical Design Report For Mixed Use 2B+G+7Hotel BuildingDocument20 pagesElectrical Design Report For Mixed Use 2B+G+7Hotel BuildingEyerusNo ratings yet
- Oral Medication PharmacologyDocument4 pagesOral Medication PharmacologyElaisa Mae Delos SantosNo ratings yet
- Presentation of Urban RegenerationsDocument23 pagesPresentation of Urban RegenerationsRafiuddin RoslanNo ratings yet
- Boala Cronica Obstructive: BpocDocument21 pagesBoala Cronica Obstructive: BpocNicoleta IliescuNo ratings yet
- English Extra Conversation Club International Women's DayDocument2 pagesEnglish Extra Conversation Club International Women's Dayevagloria11No ratings yet
- SolarBright MaxBreeze Solar Roof Fan Brochure Web 1022Document4 pagesSolarBright MaxBreeze Solar Roof Fan Brochure Web 1022kewiso7811No ratings yet
- Digital Water Monitoring and Turbidity Quality System Using MicrocontrollerDocument8 pagesDigital Water Monitoring and Turbidity Quality System Using MicrocontrollerIrin DwiNo ratings yet
- Variables in Language Teaching - The Role of The TeacherDocument34 pagesVariables in Language Teaching - The Role of The TeacherFatin AqilahNo ratings yet
- GRP Product CatalogueDocument57 pagesGRP Product CatalogueMulyana alcNo ratings yet
- C-Dot Max-XlDocument39 pagesC-Dot Max-XlGourav Roy100% (3)
- (PDF) Biochemistry and Molecular Biology of Plants: Book DetailsDocument1 page(PDF) Biochemistry and Molecular Biology of Plants: Book DetailsArchana PatraNo ratings yet
- IPO Fact Sheet - Accordia Golf Trust 140723Document4 pagesIPO Fact Sheet - Accordia Golf Trust 140723Invest StockNo ratings yet
- Hanwha Engineering & Construction - Brochure - enDocument48 pagesHanwha Engineering & Construction - Brochure - enAnthony GeorgeNo ratings yet
- Service Parts List: 54-26-0005 2551-20 M12™ FUEL™ SURGE™ 1/4" Hex Hydraulic Driver K42ADocument2 pagesService Parts List: 54-26-0005 2551-20 M12™ FUEL™ SURGE™ 1/4" Hex Hydraulic Driver K42AAmjad AlQasrawi100% (1)
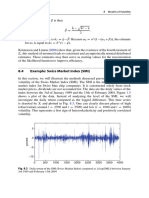
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- Scientology Abridged Dictionary 1973Document21 pagesScientology Abridged Dictionary 1973Cristiano Manzzini100% (2)
- S06 - 1 THC560 DD311Document128 pagesS06 - 1 THC560 DD311Canchari Pariona Jhon AngelNo ratings yet