You might also like
- L2 SU RecurrencesDocument43 pagesL2 SU RecurrencesAnas AlajatiNo ratings yet
- Liu Et Al-2018-Journal of Applied Econometrics - Sup-1Document9 pagesLiu Et Al-2018-Journal of Applied Econometrics - Sup-1Grant HeilemanNo ratings yet
- Chap 2Document6 pagesChap 2김민성No ratings yet
- The Gcd-Sum Function: Article 01.2.2 Journal of Integer Sequences, Vol. 4 (2001)Document19 pagesThe Gcd-Sum Function: Article 01.2.2 Journal of Integer Sequences, Vol. 4 (2001)harsh bhambhaniNo ratings yet
- A4 SolutionDocument3 pagesA4 SolutionMickey WongNo ratings yet
- Sanet - ST Spectral Analysis For Univariate Time Series (Instructor Solution Manual, Solutions)Document491 pagesSanet - ST Spectral Analysis For Univariate Time Series (Instructor Solution Manual, Solutions)Angel Cuevas MuñozNo ratings yet
- Ex 5 Sol 475Document16 pagesEx 5 Sol 475Rohit GargNo ratings yet
- CS103X: Discrete Structures Homework Assignment 1: SolutionsDocument9 pagesCS103X: Discrete Structures Homework Assignment 1: SolutionsMichel MagnaNo ratings yet
- Econ107 Assignment 1 Answer Key: Question 1 (50 Marks)Document4 pagesEcon107 Assignment 1 Answer Key: Question 1 (50 Marks)Ives LeeNo ratings yet
- Midterm 1 SolutionsDocument6 pagesMidterm 1 SolutionssowNo ratings yet
- Homework 1: ELEN E6885: Introduction To Reinforcement Learning September 21, 2021Document8 pagesHomework 1: ELEN E6885: Introduction To Reinforcement Learning September 21, 2021jiashu chenNo ratings yet
- Alevelsb fs1 Ex7mixDocument6 pagesAlevelsb fs1 Ex7mixTwiddle MegaNo ratings yet
- POM Final FormulaDocument5 pagesPOM Final FormulaShawron weevNo ratings yet
- Actividad 2 Bernal-GrandaDocument7 pagesActividad 2 Bernal-GrandaTeofilo GrandaNo ratings yet
- Formula Sheet NumericalDocument3 pagesFormula Sheet NumericalZain BhinderNo ratings yet
- Mathematical Foundation: 1 Running TimeDocument6 pagesMathematical Foundation: 1 Running TimeHiten LohakareNo ratings yet
- PnormDocument9 pagesPnormpedroNo ratings yet
- Processos Estoc Asticos: Augusto GadelhaDocument22 pagesProcessos Estoc Asticos: Augusto GadelhaIoneide SoaresNo ratings yet
- CH 15Document19 pagesCH 15aNo ratings yet
- L4 1 LTIsys AnalysisDocument11 pagesL4 1 LTIsys AnalysisMohd Shadab AlamNo ratings yet
- 2016 Exam 3 SolutionDocument6 pages2016 Exam 3 Solution김명주No ratings yet
- EULEURDocument10 pagesEULEURLansana TOURENo ratings yet
- Chapter 4Document34 pagesChapter 4Sixu YanNo ratings yet
- BT Wk10 LectureNotesDocument16 pagesBT Wk10 LectureNotesRiya ChNo ratings yet
- Derivation of Peak TimeDocument1 pageDerivation of Peak TimeIman SatriaNo ratings yet
- Processos Estoc Asticos: Augusto GadelhaDocument18 pagesProcessos Estoc Asticos: Augusto GadelhaIoneide SoaresNo ratings yet
- The 2017 Putnam Competition Problems and SolutionsDocument12 pagesThe 2017 Putnam Competition Problems and SolutionsSounak DayNo ratings yet
- EE675A Lecture 16Document6 pagesEE675A Lecture 16sachin bhadangNo ratings yet
- ECE 301: Signals and Systems Homework Assignment #5: Professor: Aly El Gamal TA: Xianglun MaoDocument10 pagesECE 301: Signals and Systems Homework Assignment #5: Professor: Aly El Gamal TA: Xianglun MaosowNo ratings yet
- IIT - PCM-2003 With Solutions PDFDocument32 pagesIIT - PCM-2003 With Solutions PDFShubham KumarNo ratings yet
- Introduction To Fluid Mechanics Kundu 4e Solution ManualDocument155 pagesIntroduction To Fluid Mechanics Kundu 4e Solution ManualAyush DeoreNo ratings yet
- Chapter 3: Some Time-Series ModelsDocument33 pagesChapter 3: Some Time-Series Modelspayal sachdevNo ratings yet
- AGA-8 Equations Written by WBDocument3 pagesAGA-8 Equations Written by WBWaqar BhattiNo ratings yet
- Solving Real Business Cycle Models by Solving Systems of First Order ConditionsDocument18 pagesSolving Real Business Cycle Models by Solving Systems of First Order ConditionsBrunéNo ratings yet
- ELEN3012 - 2020 Part 2Document7 pagesELEN3012 - 2020 Part 2Bongani MofokengNo ratings yet
- Analysis II MS Sol 2015-16Document3 pagesAnalysis II MS Sol 2015-16Mainak SamantaNo ratings yet
- DR Mervet Elmhalawy Time SeriesDocument54 pagesDR Mervet Elmhalawy Time SeriesMohamed AsimNo ratings yet
- Answers For Recurrence ProblemsDocument1 pageAnswers For Recurrence ProblemsdfdfdfNo ratings yet
- Week 3 Video 3 - First Order DynamicsDocument9 pagesWeek 3 Video 3 - First Order DynamicsJovi LeoNo ratings yet
- List of FormulasDocument7 pagesList of Formulastimeijkhout92No ratings yet
- 23 Exam 01 SOLv 231025 ADocument5 pages23 Exam 01 SOLv 231025 A이주영No ratings yet
- SemiDocument6 pagesSemiYash MehrotraNo ratings yet
- Concrete Mathematics Exercises From 30 September 2016: Exercise 1.7Document6 pagesConcrete Mathematics Exercises From 30 September 2016: Exercise 1.7rohanNo ratings yet
- Lecture3 2023 AnnotatedDocument28 pagesLecture3 2023 AnnotatedproddutkumarbiswasNo ratings yet
- Sms2307: Tutorial 2: N N N NDocument2 pagesSms2307: Tutorial 2: N N N NnadiNo ratings yet
- Notes 1 2018-19 Infinitely Many PrimesDocument12 pagesNotes 1 2018-19 Infinitely Many PrimesadrverharNo ratings yet
- On Integral Representations of Q - Gamma and Q-Beta FunctionsDocument16 pagesOn Integral Representations of Q - Gamma and Q-Beta Functionsyip90No ratings yet
- Master's TheoremDocument4 pagesMaster's TheoremyashdhingraNo ratings yet
- Quadratic Iterations To Π Associated With Elliptic Functions To The Cubic And Septic BaseDocument16 pagesQuadratic Iterations To Π Associated With Elliptic Functions To The Cubic And Septic BaseRenee BravoNo ratings yet
- Test #3 Answer Key: Niversity of Ennsylvania Epartment of AthematicsDocument3 pagesTest #3 Answer Key: Niversity of Ennsylvania Epartment of AthematicsBakari HamisiNo ratings yet
- Some Improved Estimators of Population Mean Using Information On Two Auxiliary AttributesDocument9 pagesSome Improved Estimators of Population Mean Using Information On Two Auxiliary AttributesScience DirectNo ratings yet
- Flowchart 1Document3 pagesFlowchart 1VaibhavNo ratings yet
- P20 IIR Filters Part3Document33 pagesP20 IIR Filters Part3Harold GealanNo ratings yet
- Real Business Cycles: Jes Us Fern Andez-Villaverde University of PennsylvaniaDocument22 pagesReal Business Cycles: Jes Us Fern Andez-Villaverde University of PennsylvaniawilianssterNo ratings yet
- 2a 4 Ac B 4a: Quadratic Solution: VertexDocument5 pages2a 4 Ac B 4a: Quadratic Solution: VertexCheng Win-YarnNo ratings yet
- 714-11-2020 Finite Fourier AnalysisDocument15 pages714-11-2020 Finite Fourier AnalysisMarcus PoonNo ratings yet
- Lectures PDFDocument62 pagesLectures PDFAtul RaiNo ratings yet
- The Gcd-Sum Function: Journal of Integer Sequences December 2001Document20 pagesThe Gcd-Sum Function: Journal of Integer Sequences December 2001John Vincent V MagulianoNo ratings yet
- HW 3 SolDocument2 pagesHW 3 Sol与六No ratings yet
- The Impact of Awe Induced by COVID-19 Pandemic On Green Consumption Behavior in ChinaDocument14 pagesThe Impact of Awe Induced by COVID-19 Pandemic On Green Consumption Behavior in Chinamaryamsaleem430No ratings yet
- New PVC CheatSheet - GMs StaffDocument1 pageNew PVC CheatSheet - GMs Staffmaryamsaleem430No ratings yet
- Week 14 A Case Study of Wal-Mart's "Green" Supply Chain ManagementDocument5 pagesWeek 14 A Case Study of Wal-Mart's "Green" Supply Chain Managementmaryamsaleem430No ratings yet
- Business Case For Opening A Café For Professional Meetings Problem StatementDocument3 pagesBusiness Case For Opening A Café For Professional Meetings Problem Statementmaryamsaleem430No ratings yet
- Green Consumerism Among Students A Survey in CampuDocument7 pagesGreen Consumerism Among Students A Survey in Campumaryamsaleem430No ratings yet
- Te Schedule-UET Career Fair 2021 Date: 18-11-2021Document3 pagesTe Schedule-UET Career Fair 2021 Date: 18-11-2021maryamsaleem430No ratings yet
- Business Case For Opening A Café For Professional Meetings Problem StatementDocument2 pagesBusiness Case For Opening A Café For Professional Meetings Problem Statementmaryamsaleem430No ratings yet
- A Practical 3d-Printed Soft Robotic Prosthetic Hand With Multi-Articulating CapabilitiesDocument23 pagesA Practical 3d-Printed Soft Robotic Prosthetic Hand With Multi-Articulating Capabilitiesmaryamsaleem430No ratings yet
- Chapter 3: The Reinforcement Learning Problem (Markov Decision Processes, or MDPS)Document27 pagesChapter 3: The Reinforcement Learning Problem (Markov Decision Processes, or MDPS)maryamsaleem430No ratings yet
- Final Term ST MGTDocument2 pagesFinal Term ST MGTmaryamsaleem430No ratings yet
- Assignment 1 2020Document4 pagesAssignment 1 2020maryamsaleem430No ratings yet
- FFC ReportDocument30 pagesFFC Reportmaryamsaleem430No ratings yet
- Exercise Solution For Chapter 2: Nanxi Zhang July 22, 2020Document2 pagesExercise Solution For Chapter 2: Nanxi Zhang July 22, 2020maryamsaleem430No ratings yet
- Barriers For Green Supply Chain Management Implementation: March 2014Document7 pagesBarriers For Green Supply Chain Management Implementation: March 2014maryamsaleem430No ratings yet
- Post Graduate Academic Calendar (2019-2020) : Fall SemesterDocument29 pagesPost Graduate Academic Calendar (2019-2020) : Fall Semestermaryamsaleem430No ratings yet
- Trust and Knowledge Sharing in Green Sup PDFDocument13 pagesTrust and Knowledge Sharing in Green Sup PDFmaryamsaleem430No ratings yet
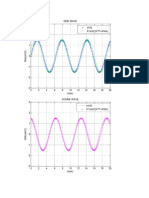
- 3 Sine Wave Sin (T) A Sin (2 Pi F T+theta)Document2 pages3 Sine Wave Sin (T) A Sin (2 Pi F T+theta)maryamsaleem430No ratings yet
- Assignment # 5: Class: BBA 8 Subject: Career Support Training - IV Trainer: Hamid Najmi Topic: Laws of PersuasionDocument1 pageAssignment # 5: Class: BBA 8 Subject: Career Support Training - IV Trainer: Hamid Najmi Topic: Laws of Persuasionmaryamsaleem430No ratings yet
- Safety MeasuresDocument28 pagesSafety Measuresmaryamsaleem430No ratings yet
- SYLLABUSDocument1 pageSYLLABUSUadNo ratings yet
- Engineering Council of South Africa: Training and Mentoring Guide For Professional CategoriesDocument26 pagesEngineering Council of South Africa: Training and Mentoring Guide For Professional CategoriesMECHANICAL ENGINEERINGNo ratings yet
- Attach Request: RRC Connection Setup Complete RRC Connection Setup CompleteDocument8 pagesAttach Request: RRC Connection Setup Complete RRC Connection Setup CompleteVusal SuleymanovNo ratings yet
- HW 3Document10 pagesHW 3Hande ÖzerNo ratings yet
- Carjau Aurelia Nicoleta - ENDocument1 pageCarjau Aurelia Nicoleta - ENFirst CopyNo ratings yet
- Professional Education LET Reviewer 150 Items With Answer KeyDocument14 pagesProfessional Education LET Reviewer 150 Items With Answer KeyAngel Salinas100% (1)
- PrestressingDocument14 pagesPrestressingdrotostotNo ratings yet
- Lyra Kate Mae P. Salvador BSA-1 MANSCI-446 Course Final RequirementDocument5 pagesLyra Kate Mae P. Salvador BSA-1 MANSCI-446 Course Final RequirementLyra Kate Mae SalvadorNo ratings yet
- 32 KV High Voltage Power Transmission Line and Stress On Brassica JunceaDocument4 pages32 KV High Voltage Power Transmission Line and Stress On Brassica Junceamuhammad mushofahNo ratings yet
- Analisis Perencanaan Strategis Sebagai Determinan Kinerja Perusahaan Daerah Air Minum PDAM Kota Gorontalo PDFDocument19 pagesAnalisis Perencanaan Strategis Sebagai Determinan Kinerja Perusahaan Daerah Air Minum PDAM Kota Gorontalo PDFMuhammat Nur SalamNo ratings yet
- Vehicle Yaw Rate Estimation Using A Virtual SensorDocument14 pagesVehicle Yaw Rate Estimation Using A Virtual Sensorbnc1No ratings yet
- System 9898XT Service ManualDocument398 pagesSystem 9898XT Service ManualIsai Lara Osoria100% (3)
- Purple Futuristic Pitch Deck PresentationDocument10 pagesPurple Futuristic Pitch Deck PresentationRidzki F.RNo ratings yet
- Punjab Medical Faculty Registration Form: Personal DetailsDocument2 pagesPunjab Medical Faculty Registration Form: Personal DetailsAamir Khan PtiNo ratings yet
- Job Card-TPN 1010-B150Document2 pagesJob Card-TPN 1010-B150Debasis Pattnaik DebaNo ratings yet
- Aace Evm 82R 13Document22 pagesAace Evm 82R 13eduardomenac2000No ratings yet
- Green Bill: Easypa Y Scan & PayDocument4 pagesGreen Bill: Easypa Y Scan & Paymohamed elmakhzniNo ratings yet
- Control 4Document17 pagesControl 4muhamed mahmoodNo ratings yet
- Transportation Research Part C: Xiaojie Luan, Francesco Corman, Lingyun MengDocument27 pagesTransportation Research Part C: Xiaojie Luan, Francesco Corman, Lingyun MengImags GamiNo ratings yet
- Sikatard 930: Cement Hydration StabiliserDocument2 pagesSikatard 930: Cement Hydration StabiliserBudhi KurniawanNo ratings yet
- Uplift With Moment CalculationDocument4 pagesUplift With Moment CalculationdennykvgNo ratings yet
- All About Immanuel KantDocument20 pagesAll About Immanuel KantSean ChoNo ratings yet
- Ampd Data Sheet Vacuum Casting Resin 8263Document2 pagesAmpd Data Sheet Vacuum Casting Resin 8263Lorenzo Guida0% (1)
- Transitive & Intransitive Verbs: Grammar PracticeDocument5 pagesTransitive & Intransitive Verbs: Grammar PracticeSzeman YipNo ratings yet
- Final CDP MuzaffarpurDocument224 pagesFinal CDP MuzaffarpurVivek Kumar YadavNo ratings yet
- Aras Jung Curriculum IndividualDocument72 pagesAras Jung Curriculum IndividualdianavaleriaalvarezNo ratings yet
- 20years Cultural Heritage Vol2 enDocument252 pages20years Cultural Heritage Vol2 enInisNo ratings yet
- Why Are You Applying For Financial AidDocument2 pagesWhy Are You Applying For Financial AidqwertyNo ratings yet
- A User Guide For FORTRAN 90-95-0Document19 pagesA User Guide For FORTRAN 90-95-0Anonymous IF3H0X2vBeNo ratings yet
- Installation Manual - Chain Link FenceDocument2 pagesInstallation Manual - Chain Link FenceChase GietterNo ratings yet