You might also like
- Quality Competencies Matrix: PrintDocument1 pageQuality Competencies Matrix: PrintAnonymous SQ5kprsQnNo ratings yet
- As 6Document2 pagesAs 6kiad.thariyaNo ratings yet
- Appointment 5802 PDFDocument3 pagesAppointment 5802 PDFMohammad ShabirNo ratings yet
- Assign1B22 ERDDocument1 pageAssign1B22 ERDSam ANo ratings yet
- Muskets Tomahawks Army BuilderDocument8 pagesMuskets Tomahawks Army Builderbothi1984No ratings yet
- GR 7 Eng 1st QE TOS 2018 19Document3 pagesGR 7 Eng 1st QE TOS 2018 19Aljerr LaxamanaNo ratings yet
- 6.mathematics of FinanceDocument22 pages6.mathematics of FinanceSanchita ChauhanNo ratings yet
- SATEC Catalog 2009 OnlineDocument28 pagesSATEC Catalog 2009 Onlinetunaunaturk turkNo ratings yet
- Assessing Translation - A Manual For Requesters: PurposeDocument16 pagesAssessing Translation - A Manual For Requesters: PurposeDương HiểnNo ratings yet
- 01A Flows of Economic ActivitiesDocument7 pages01A Flows of Economic ActivitiesGaurav GhareNo ratings yet
- Mohan MandirDocument2 pagesMohan MandirRoopesh ChaudharyNo ratings yet
- HD Brown + Clear Low eDocument3 pagesHD Brown + Clear Low eSukhbir SinghNo ratings yet
- 73 Statechart Diagram: 3.73.1 SemanticsDocument34 pages73 Statechart Diagram: 3.73.1 SemanticsHamza KhanNo ratings yet
- MEXILR1339: Global Assessment Certificate Formulae Sheet & Z Table For In-Class Test & ExaminationDocument2 pagesMEXILR1339: Global Assessment Certificate Formulae Sheet & Z Table For In-Class Test & ExaminationMNo ratings yet
- A Guide For Implementing HFA by LocalsDocument110 pagesA Guide For Implementing HFA by LocalsInterActionNo ratings yet
- HARVEST TOOL Math and EnglishDocument5 pagesHARVEST TOOL Math and EnglishJenefer Cabaron SajulNo ratings yet
- Expense Sheet-June'15Document1 pageExpense Sheet-June'15Rajesh TipnisNo ratings yet
- Lecture 2Document3 pagesLecture 2andreasgavrasNo ratings yet
- Iowa Metro Auto Dealers PAC - 9706 - ScannedDocument2 pagesIowa Metro Auto Dealers PAC - 9706 - ScannedZach EdwardsNo ratings yet
- BUS101 Working PapersDocument388 pagesBUS101 Working PapersftcuserNo ratings yet
- List of O&M Mudigubba Works On 04.010.2023.Document1 pageList of O&M Mudigubba Works On 04.010.2023.Executive Engineer I.B.DivisionNo ratings yet
- SUPER ENERGY CORPORATION PUBLIC COMPANY LIMITED ESG Ratings ReportDocument58 pagesSUPER ENERGY CORPORATION PUBLIC COMPANY LIMITED ESG Ratings Reportmrids177No ratings yet
- At Evaluation Form (June 2023)Document1 pageAt Evaluation Form (June 2023)Tr. ThawdarNo ratings yet
- Corporate Communications: A Dimension of Corporate MeaningDocument21 pagesCorporate Communications: A Dimension of Corporate MeaningsonjalukicNo ratings yet
- Risk Assesment ReportDocument1 pageRisk Assesment Reportsohani WaghelaNo ratings yet
- Bode PlotDocument60 pagesBode PlotAnurag SrivastavNo ratings yet
- MAS Bobadilla Responsibility Accounting Variable Costing & Segmented ReportinDocument9 pagesMAS Bobadilla Responsibility Accounting Variable Costing & Segmented ReportinJEFFERSON CUTENo ratings yet
- About BlankDocument1 pageAbout BlankHarshit KumarNo ratings yet
- Tablas de CaracteresDocument48 pagesTablas de Caracterestazgnr96No ratings yet
- T1DF PBM IBM Payer Manufacturer Map 2017.03.01Document1 pageT1DF PBM IBM Payer Manufacturer Map 2017.03.01The Type 1 Diabetes Defense FoundationNo ratings yet
- BASSnet Fleet Management System PDFDocument14 pagesBASSnet Fleet Management System PDFpravenNo ratings yet
- MPR - (SEP-23) - DNDocument2 pagesMPR - (SEP-23) - DNExecutive Engineer I.B.DivisionNo ratings yet
- J - F - Smart Utility SolutionsDocument13 pagesJ - F - Smart Utility SolutionsBachir GeageaNo ratings yet
- Core Composite PlotDocument1 pageCore Composite PlotThato MasholaNo ratings yet
- NIS2 Security Solution InfographicDocument1 pageNIS2 Security Solution InfographicPaolo ZampieriNo ratings yet
- JayantDocument9 pagesJayantKeshav KansalNo ratings yet
- PrismERP BrochureDocument4 pagesPrismERP BrochureBelal AhmedNo ratings yet
- ER-and-EER-to-Relational Mapping: - For Each Regular Entity Type E in The ER SchemaDocument7 pagesER-and-EER-to-Relational Mapping: - For Each Regular Entity Type E in The ER SchemagtgnomeNo ratings yet
- Pet2Aryf: TransmittedDocument5 pagesPet2Aryf: TransmittedMatthew ListroNo ratings yet
- Community Board 3 ProfileDocument1 pageCommunity Board 3 ProfileThe Lo-DownNo ratings yet
- Dr. Tasneem Akhter Lecture # 2 Market Forces Demand & SupplyDocument16 pagesDr. Tasneem Akhter Lecture # 2 Market Forces Demand & SupplyprofNo ratings yet
- Disclosure Summary Page C'0 - . R: DR-2Document10 pagesDisclosure Summary Page C'0 - . R: DR-2Zach EdwardsNo ratings yet
- DRAFT TRUSTEESHIP AGREEMENT FOR THE TERR - ITORY OF SOMALILAND L' UNDER ITALIAN ADMINISTRATIONDocument12 pagesDRAFT TRUSTEESHIP AGREEMENT FOR THE TERR - ITORY OF SOMALILAND L' UNDER ITALIAN ADMINISTRATIONGaryaqaan Muuse YuusufNo ratings yet
- 12th ResultDocument1 page12th Resultsinghaniya vikash patelNo ratings yet
- LQuiz (TOV1) # 22 (Eng)Document4 pagesLQuiz (TOV1) # 22 (Eng)PkrNo ratings yet
- Lazaro Cet-0216-11 HW1Document2 pagesLazaro Cet-0216-11 HW1MarkJude MorlaNo ratings yet
- USDA Forest Service - Using The BMS Micro-Blaster For Trail WorkDocument6 pagesUSDA Forest Service - Using The BMS Micro-Blaster For Trail WorkRockWagonNo ratings yet
- m140 Chapter6 Sec6.1 F19completedDocument6 pagesm140 Chapter6 Sec6.1 F19completedDesizm .ComNo ratings yet
- 물리전자1필기본Document44 pages물리전자1필기본허상호No ratings yet
- Expense Sheet-April'15Document1 pageExpense Sheet-April'15Rajesh TipnisNo ratings yet
- Coordinating Comp XC12 & A11+Document12 pagesCoordinating Comp XC12 & A11+Krish TomarNo ratings yet
- 2013 July 15th Sumitomo PDFDocument7 pages2013 July 15th Sumitomo PDFHH KevinNo ratings yet
- LiquefactionDocument5 pagesLiquefactionSantosh ZunjarNo ratings yet
- Chemical Kinetics Class - 6 (Notes)Document20 pagesChemical Kinetics Class - 6 (Notes)ᴜsʜɴᴇᴇᴋNo ratings yet
- Print SelDocument1 pagePrint Selvikashchaudhry603No ratings yet
- Adobe Scan 29-Dec-2020Document1 pageAdobe Scan 29-Dec-2020hemanthNo ratings yet
- Statements Are: Half Yearly Am - (2022-2023)Document8 pagesStatements Are: Half Yearly Am - (2022-2023)RomitNo ratings yet
- Epl258 Environmental Aspects and Impacts RegisterDocument3 pagesEpl258 Environmental Aspects and Impacts RegisterMohamed IsmailNo ratings yet
- The Impact of Awe Induced by COVID-19 Pandemic On Green Consumption Behavior in ChinaDocument14 pagesThe Impact of Awe Induced by COVID-19 Pandemic On Green Consumption Behavior in Chinamaryamsaleem430No ratings yet
- New PVC CheatSheet - GMs StaffDocument1 pageNew PVC CheatSheet - GMs Staffmaryamsaleem430No ratings yet
- Business Case For Opening A Café For Professional Meetings Problem StatementDocument2 pagesBusiness Case For Opening A Café For Professional Meetings Problem Statementmaryamsaleem430No ratings yet
- Te Schedule-UET Career Fair 2021 Date: 18-11-2021Document3 pagesTe Schedule-UET Career Fair 2021 Date: 18-11-2021maryamsaleem430No ratings yet
- Final Term ST MGTDocument2 pagesFinal Term ST MGTmaryamsaleem430No ratings yet
- A Practical 3d-Printed Soft Robotic Prosthetic Hand With Multi-Articulating CapabilitiesDocument23 pagesA Practical 3d-Printed Soft Robotic Prosthetic Hand With Multi-Articulating Capabilitiesmaryamsaleem430No ratings yet
- Solutions To Reinforcement Learning by Sutton Chapter 5 r3Document9 pagesSolutions To Reinforcement Learning by Sutton Chapter 5 r3maryamsaleem430No ratings yet
- Green Consumerism Among Students A Survey in CampuDocument7 pagesGreen Consumerism Among Students A Survey in Campumaryamsaleem430No ratings yet
- Week 14 A Case Study of Wal-Mart's "Green" Supply Chain ManagementDocument5 pagesWeek 14 A Case Study of Wal-Mart's "Green" Supply Chain Managementmaryamsaleem430No ratings yet
- Business Case For Opening A Café For Professional Meetings Problem StatementDocument3 pagesBusiness Case For Opening A Café For Professional Meetings Problem Statementmaryamsaleem430No ratings yet
- Exercise Solution For Chapter 2: Nanxi Zhang July 22, 2020Document2 pagesExercise Solution For Chapter 2: Nanxi Zhang July 22, 2020maryamsaleem430No ratings yet
- FFC ReportDocument30 pagesFFC Reportmaryamsaleem430No ratings yet
- Assignment 1 2020Document4 pagesAssignment 1 2020maryamsaleem430No ratings yet
- Post Graduate Academic Calendar (2019-2020) : Fall SemesterDocument29 pagesPost Graduate Academic Calendar (2019-2020) : Fall Semestermaryamsaleem430No ratings yet
- Assignment # 5: Class: BBA 8 Subject: Career Support Training - IV Trainer: Hamid Najmi Topic: Laws of PersuasionDocument1 pageAssignment # 5: Class: BBA 8 Subject: Career Support Training - IV Trainer: Hamid Najmi Topic: Laws of Persuasionmaryamsaleem430No ratings yet
- Barriers For Green Supply Chain Management Implementation: March 2014Document7 pagesBarriers For Green Supply Chain Management Implementation: March 2014maryamsaleem430No ratings yet
- Trust and Knowledge Sharing in Green Sup PDFDocument13 pagesTrust and Knowledge Sharing in Green Sup PDFmaryamsaleem430No ratings yet
- Safety MeasuresDocument28 pagesSafety Measuresmaryamsaleem430No ratings yet
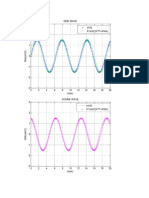
- 3 Sine Wave Sin (T) A Sin (2 Pi F T+theta)Document2 pages3 Sine Wave Sin (T) A Sin (2 Pi F T+theta)maryamsaleem430No ratings yet
- Hbo Chapter 8 12 ReviewerDocument19 pagesHbo Chapter 8 12 ReviewerAngelica Faye DuroNo ratings yet
- Interactive Graduation Flowchart For Students With Disabilites-Revised January 2019Document63 pagesInteractive Graduation Flowchart For Students With Disabilites-Revised January 2019api-328937742100% (1)
- M.SC Biotechnology AY 2018 19Document96 pagesM.SC Biotechnology AY 2018 19Shrikant PatilNo ratings yet
- Barnes, Doria-Resume725Document2 pagesBarnes, Doria-Resume725api-243037220No ratings yet
- English Lingua Journal: Issues in English StudiesDocument12 pagesEnglish Lingua Journal: Issues in English StudiesAL Athar AlghariqaNo ratings yet
- Accenture MBA Rec BrochureDocument15 pagesAccenture MBA Rec BrochureSarad GuptaNo ratings yet
- Alles Elln Action PlanDocument12 pagesAlles Elln Action PlanDynz de ExplorerNo ratings yet
- Rigidez Cognitiva y TOCDocument16 pagesRigidez Cognitiva y TOCnicole dufournel salasNo ratings yet
- Cayamba Educ M3 (L1-L3)Document6 pagesCayamba Educ M3 (L1-L3)Eljen Dave CayambaNo ratings yet
- Caffi 1999Document29 pagesCaffi 1999Aisha SiddiqaNo ratings yet
- ModelsDocument27 pagesModelsamit_bansal_36No ratings yet
- Description of The Strategy: Identifying and Defining Target BehaviorsDocument6 pagesDescription of The Strategy: Identifying and Defining Target Behaviorsiulia9gavrisNo ratings yet
- Gen Math - Module 2 - ActivitiesDocument2 pagesGen Math - Module 2 - ActivitiesJohn Vincent V MagulianoNo ratings yet
- Research Methodology CompleteDocument12 pagesResearch Methodology CompleteAbdifatah AbdilahiNo ratings yet
- Advantages and Disadvantages of PowerPoint in Lectures To ScienceDocument5 pagesAdvantages and Disadvantages of PowerPoint in Lectures To Scienceanon_634630759No ratings yet
- 1:00 - 2:00 PM Teaching Demonstration Semi-Detailed Lesson Plan in Statistics & Probability I. ObjectivesDocument2 pages1:00 - 2:00 PM Teaching Demonstration Semi-Detailed Lesson Plan in Statistics & Probability I. ObjectivesMardy Nelle Sanchez Villacura-GalveNo ratings yet
- Chapter 2 - Results Controls: Management Control SystemsDocument11 pagesChapter 2 - Results Controls: Management Control SystemsJaneNo ratings yet
- Parallelism Between Science Teaching Practices and Classroom Behavior Among Grade 8 Students of Batangas National High SchoolDocument9 pagesParallelism Between Science Teaching Practices and Classroom Behavior Among Grade 8 Students of Batangas National High SchoolIOER International Multidisciplinary Research Journal ( IIMRJ)No ratings yet
- Growth Is The Only Evidence of LifeDocument14 pagesGrowth Is The Only Evidence of LifeDian GalanNo ratings yet
- Psychology in AdministrationDocument16 pagesPsychology in AdministrationMohaiminur ArponNo ratings yet
- Sakar2019 Article Real-timePredictionOfOnlineShoDocument16 pagesSakar2019 Article Real-timePredictionOfOnlineShoSwakkhar ShatabdaNo ratings yet
- Yutuc, Irene M. q2w8 WHLSWPDocument4 pagesYutuc, Irene M. q2w8 WHLSWPmerry menesesNo ratings yet
- Reviewer in Understanding The Self (Midterm)Document1 pageReviewer in Understanding The Self (Midterm)Mark B. BarrogaNo ratings yet
- Human Face Lesson PlanDocument4 pagesHuman Face Lesson Planapi-284994455No ratings yet
- Ernest Sosa - Epistemology. An Antology. Blackwell Books PDFDocument931 pagesErnest Sosa - Epistemology. An Antology. Blackwell Books PDFGendrik Moreno100% (13)
- Lesson Plan 9 ADocument2 pagesLesson Plan 9 AJenny BicaNo ratings yet
- Global Talent Management at NovartisDocument3 pagesGlobal Talent Management at Novartisfalcon_99910No ratings yet
- My IPCRF 2020Document20 pagesMy IPCRF 2020Monic SarVenNo ratings yet
- Interview SkillsDocument34 pagesInterview Skillsnirakhan100% (1)
- Making Connections Level 3 Teacher S Manual: Skills and Strategies Making Connections Level 3 Teacher S Manual: Skills and Strategies For Academic Reading (Paperback) For Academic Reading (Paperback)Document2 pagesMaking Connections Level 3 Teacher S Manual: Skills and Strategies Making Connections Level 3 Teacher S Manual: Skills and Strategies For Academic Reading (Paperback) For Academic Reading (Paperback)Mehmet YILDIZ29% (7)