You might also like
- Ab Initio Job Interview Questions and AnswersDocument8 pagesAb Initio Job Interview Questions and AnswersAkash GanjiNo ratings yet
- Snyder Computer Chips Inc.Document3 pagesSnyder Computer Chips Inc.Malik AsadNo ratings yet
- 10-701 Midterm Exam Solutions, Spring 2007Document20 pages10-701 Midterm Exam Solutions, Spring 2007Juan VeraNo ratings yet
- Unit III: Virtual Simulation Assignment Gravity and OrbitsDocument5 pagesUnit III: Virtual Simulation Assignment Gravity and OrbitsMalik AsadNo ratings yet
- Solved - Determine The Real Root of F (X) 5x3 - 5x2 + 6x - 2 - (...Document6 pagesSolved - Determine The Real Root of F (X) 5x3 - 5x2 + 6x - 2 - (...Angel Maliel Limon CaceresNo ratings yet
- Textbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkDocument4 pagesTextbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkMalik Asad0% (1)
- Textbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkDocument4 pagesTextbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkMalik AsadNo ratings yet
- Write A Java Program 8. I N Cryptarithmetic Puzzle...Document5 pagesWrite A Java Program 8. I N Cryptarithmetic Puzzle...Hadiqa ShahidNo ratings yet
- Q1. Modify The MATLAB Code For Jacobi's Iterative ...Document6 pagesQ1. Modify The MATLAB Code For Jacobi's Iterative ...Malik AsadNo ratings yet
- 5 2e3Document7 pages5 2e3Ed HelmsNo ratings yet
- COMP3308/COMP3608 Artificial Intelligence Week 10 Tutorial Exercises Support Vector Machines. Ensembles of ClassifiersDocument3 pagesCOMP3308/COMP3608 Artificial Intelligence Week 10 Tutorial Exercises Support Vector Machines. Ensembles of ClassifiersharietNo ratings yet
- Question: Question 1: A Sum of 25,000$ Is Invested in A Savings Account Which Pays Interest at A Rate of 7 ..Document3 pagesQuestion: Question 1: A Sum of 25,000$ Is Invested in A Savings Account Which Pays Interest at A Rate of 7 ..Quratulain Shafique QureshiNo ratings yet
- Textbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkDocument6 pagesTextbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkMalik AsadNo ratings yet
- Assignment Help (+1) 346-375-7878Document3 pagesAssignment Help (+1) 346-375-7878Muhammad Sheharyar MohsinNo ratings yet
- A Control Engineer Has Conducted An Experiment To ...Document2 pagesA Control Engineer Has Conducted An Experiment To ...Amirul IqmalNo ratings yet
- Question: 1.what Is The Asymptotic Complexity of The Following PieceDocument4 pagesQuestion: 1.what Is The Asymptotic Complexity of The Following PieceArpon Barua 1821897630No ratings yet
- Q8 Ama AsmDocument3 pagesQ8 Ama AsmMyname SmaNo ratings yet
- Solve The Following Linear Program Graphically Usi...Document3 pagesSolve The Following Linear Program Graphically Usi...Malik AsadNo ratings yet
- Textbook Solutions Expert Q&A Study Pack PracticeDocument4 pagesTextbook Solutions Expert Q&A Study Pack PracticeArpon Barua 1821897630No ratings yet
- Consider The Following Analytic Function - F (X) ...Document3 pagesConsider The Following Analytic Function - F (X) ...iramNo ratings yet
- An Insurance Company Offers Its Policyholders A Nu...Document2 pagesAn Insurance Company Offers Its Policyholders A Nu...Jaleel AhmedNo ratings yet
- CSE303: ADA M#5 (E-Tutorial#2) : Computational Complexity ReductionDocument13 pagesCSE303: ADA M#5 (E-Tutorial#2) : Computational Complexity ReductionPrajjwal MehraNo ratings yet
- Assembly Language Programming. Due - Description - T... PDFDocument6 pagesAssembly Language Programming. Due - Description - T... PDFNabil AlzeqriNo ratings yet
- Solved - Extending The Concepts and SkillsConsider The RandomDocument9 pagesSolved - Extending The Concepts and SkillsConsider The RandomMUHAMMAD NAWAZNo ratings yet
- Solved The 5-m High Retaining Wall in Figure 13.40c Is Subject...Document1 pageSolved The 5-m High Retaining Wall in Figure 13.40c Is Subject...Cristian A. GarridoNo ratings yet
- CSE303: ADA M#5 (E-Tutorial#1) : Computational ComplexityDocument13 pagesCSE303: ADA M#5 (E-Tutorial#1) : Computational ComplexityPrajjwal MehraNo ratings yet
- Question: Explain The Following Terms Associated With Cache and MemorDocument4 pagesQuestion: Explain The Following Terms Associated With Cache and MemorVicky VNo ratings yet
- Complete The Given C Program That Computes The Eul...Document3 pagesComplete The Given C Program That Computes The Eul...Malik AsadNo ratings yet
- Ee364a Homework 1 SolutionsDocument8 pagesEe364a Homework 1 Solutionsafmtbbasx100% (1)
- DAA Super-Imp-Tie-22Document4 pagesDAA Super-Imp-Tie-22Shan MpNo ratings yet
- Introduction Computational EngineeringDocument80 pagesIntroduction Computational EngineeringlucyvrNo ratings yet
- Mathematical Foundations of Machine LearningDocument7 pagesMathematical Foundations of Machine LearningYasin Çağatay GültekinNo ratings yet
- Algorithms Solutions CH 01 Oct2010Document16 pagesAlgorithms Solutions CH 01 Oct2010IRishikesh De0% (1)
- An M12 X 1.75 Bolt Has A Major-Diameter Area of 11...Document5 pagesAn M12 X 1.75 Bolt Has A Major-Diameter Area of 11...fem mece3381No ratings yet
- Find Its Acceleration For The First Instant and Se...Document2 pagesFind Its Acceleration For The First Instant and Se...Ionaishi FloresNo ratings yet
- Exam 2001Document17 pagesExam 2001kib6707No ratings yet
- Guidelines For Submission:: Last Date of SubmissionDocument5 pagesGuidelines For Submission:: Last Date of SubmissionSahil KalingNo ratings yet
- Question: Exercise (Test Your Understanding) A Beam of Yellow Light WithDocument3 pagesQuestion: Exercise (Test Your Understanding) A Beam of Yellow Light WithMuhammad SatrioNo ratings yet
- Dynamic Programming Introduction - Tutorial (Updated)Document6 pagesDynamic Programming Introduction - Tutorial (Updated)Atharv SinghNo ratings yet
- Step-by-Step Solution Possibilities in Different Computer Algebra SystemsDocument12 pagesStep-by-Step Solution Possibilities in Different Computer Algebra Systemsjaved shaikh chaandNo ratings yet
- (13 Marks) Calculate The Maximum Average Power ...Document9 pages(13 Marks) Calculate The Maximum Average Power ...Malik AsadNo ratings yet
- Guidelines For Submission:: Last Date of SubmissionDocument5 pagesGuidelines For Submission:: Last Date of SubmissionSahil KalingNo ratings yet
- Search Results: Mathcad Solve BlockDocument3 pagesSearch Results: Mathcad Solve BlockbashasvuceNo ratings yet
- Which of The Following Are Spanning Sets For P3 - J...Document2 pagesWhich of The Following Are Spanning Sets For P3 - J...Abdullah AnwerNo ratings yet
- A Safety Engineer Feels That 35% of All Industrial...Document2 pagesA Safety Engineer Feels That 35% of All Industrial...Hafiz Muhammad Umar AslamNo ratings yet
- Exercise 03Document5 pagesExercise 03gfjggNo ratings yet
- NPC - Print ItDocument22 pagesNPC - Print ItbayentapasNo ratings yet
- NP Completeness Ccoew 2022 PDFDocument64 pagesNP Completeness Ccoew 2022 PDFNishit Sushil SinghNo ratings yet
- Question: Devise A Hill Climbing Search Based Approach To Solve N-City Tsps. You Must de Ne All Req..Document4 pagesQuestion: Devise A Hill Climbing Search Based Approach To Solve N-City Tsps. You Must de Ne All Req..Malik AsadNo ratings yet
- Solved - Chapter 3 Problem 69RE Solution - Probability and Statistics For Engineers and Scientists 9th EditionDocument3 pagesSolved - Chapter 3 Problem 69RE Solution - Probability and Statistics For Engineers and Scientists 9th EditionJaleel AhmedNo ratings yet
- Consider The Mass-Spring System in The Following F...Document5 pagesConsider The Mass-Spring System in The Following F...aNo ratings yet
- 13 Consider The Linear Transformation T R4 R3...Document3 pages13 Consider The Linear Transformation T R4 R3...Quỳnh Trang TrầnNo ratings yet
- Lect Exf RevDocument3 pagesLect Exf RevAnthony-Dimitri ANo ratings yet
- This Study Resource Was: Final ExaminationDocument7 pagesThis Study Resource Was: Final ExaminationPuwa CalvinNo ratings yet
- Problem IN JAVA - in The Game of - C-R-A-P-S - (Chegg...Document12 pagesProblem IN JAVA - in The Game of - C-R-A-P-S - (Chegg...Hadiqa ShahidNo ratings yet
- Solved Refer To Figure 10.41. Given q2 3800 LBFT, x1 18 ...Document1 pageSolved Refer To Figure 10.41. Given q2 3800 LBFT, x1 18 ...Cristian A. GarridoNo ratings yet
- Problem 6.3-4 The Composite Beam Shown in The Figu...Document3 pagesProblem 6.3-4 The Composite Beam Shown in The Figu...Gary RenfronNo ratings yet
- Thesis Fabrizio GalliDocument22 pagesThesis Fabrizio GalliFabri GalliNo ratings yet
- Section 7.6 Linear Programming: NameDocument2 pagesSection 7.6 Linear Programming: Namesarasmile2009No ratings yet
- ITC LAB Outline Spring 2021Document6 pagesITC LAB Outline Spring 2021zain arshadNo ratings yet
- Algo - Mod12 - NP-Hard and NP-Complete ProblemsDocument56 pagesAlgo - Mod12 - NP-Hard and NP-Complete ProblemsISSAM HAMADNo ratings yet
- This Question Has Been Answered: Find Study ResourcesDocument3 pagesThis Question Has Been Answered: Find Study ResourcesMalik AsadNo ratings yet
- This Study Resource Was: Economic Problems: Possible Initiatives To Protect Small BusinessesDocument7 pagesThis Study Resource Was: Economic Problems: Possible Initiatives To Protect Small BusinessesMalik AsadNo ratings yet
- Math ExamDocument9 pagesMath ExamMalik AsadNo ratings yet
- CS 188 Fall 2019 Written Homework 1 2 PDFDocument10 pagesCS 188 Fall 2019 Written Homework 1 2 PDFMalik AsadNo ratings yet
- This Study Resource Was: Problems of Political System in Pakistan and Its SolutionsDocument2 pagesThis Study Resource Was: Problems of Political System in Pakistan and Its SolutionsMalik AsadNo ratings yet
- The Expenditure Cycle: Purchasing To Cash Disbursements Instructors Manual Learning ObjectivesDocument17 pagesThe Expenditure Cycle: Purchasing To Cash Disbursements Instructors Manual Learning ObjectivesMalik AsadNo ratings yet
- Question: Erika and Kitty, Who Are Twins, Just Received $30,000 Each For Their 25th Birthday. They Both Hav..Document4 pagesQuestion: Erika and Kitty, Who Are Twins, Just Received $30,000 Each For Their 25th Birthday. They Both Hav..Malik AsadNo ratings yet
- Question: Bank A Offers Loans at An 8% Nominal Rate (Its APR) But Requires That Interest Be Paid Quarterly ..Document3 pagesQuestion: Bank A Offers Loans at An 8% Nominal Rate (Its APR) But Requires That Interest Be Paid Quarterly ..Malik AsadNo ratings yet
- Question: Do The Initial Coding and Focus/selective Coding of The Following Interview Transcripts. Develop ..Document5 pagesQuestion: Do The Initial Coding and Focus/selective Coding of The Following Interview Transcripts. Develop ..Malik AsadNo ratings yet
- Question: Assume That Your Father Is Now 50 Years Old, Plan To Retired in 10 Years, and Expects To Live For..Document3 pagesQuestion: Assume That Your Father Is Now 50 Years Old, Plan To Retired in 10 Years, and Expects To Live For..Malik AsadNo ratings yet
- Question: Austral & Company Has A Debt Ratio of 0.5, A Total Assets Turnover Ratio of 0.25, and A Pro ..Document3 pagesQuestion: Austral & Company Has A Debt Ratio of 0.5, A Total Assets Turnover Ratio of 0.25, and A Pro ..Malik AsadNo ratings yet
- Unit 4: Features and Constraints: TopicsDocument10 pagesUnit 4: Features and Constraints: TopicsMalik AsadNo ratings yet
- Question: Solve The System Using The Laplace Transform: (2x" - 6x+2y)Document3 pagesQuestion: Solve The System Using The Laplace Transform: (2x" - 6x+2y)Malik AsadNo ratings yet
- Question: Question: Personal Health Record Management System (WriteDocument10 pagesQuestion: Question: Personal Health Record Management System (WriteMalik AsadNo ratings yet
- Question: Question 1: Recommender System You Are Required To Make ADocument6 pagesQuestion: Question 1: Recommender System You Are Required To Make AMalik AsadNo ratings yet
- Question: Devise A Hill Climbing Search Based Approach To Solve N-City Tsps. You Must de Ne All Req..Document4 pagesQuestion: Devise A Hill Climbing Search Based Approach To Solve N-City Tsps. You Must de Ne All Req..Malik AsadNo ratings yet
- Textbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkDocument6 pagesTextbook Solutions Expert Q&A Practice: Find Solutions For Your HomeworkMalik AsadNo ratings yet
- Question: 3. Write A Program On Python That Asks The User For A Color, A LDocument6 pagesQuestion: 3. Write A Program On Python That Asks The User For A Color, A LMalik AsadNo ratings yet
- This Study Resource Was: IS 665 Data Analysis For Information Systems Technical Assignment 1 Part I. Statistics (40 PTS.)Document7 pagesThis Study Resource Was: IS 665 Data Analysis For Information Systems Technical Assignment 1 Part I. Statistics (40 PTS.)Malik AsadNo ratings yet
- Question: Simply Supported Bridge Girders (W18x119) Act Compositely WiDocument3 pagesQuestion: Simply Supported Bridge Girders (W18x119) Act Compositely WiMalik AsadNo ratings yet
- Student Solutions Manual, Volume 1 For Serway/Jewett's Physics For Scientists and EngineersDocument5 pagesStudent Solutions Manual, Volume 1 For Serway/Jewett's Physics For Scientists and EngineersMalik AsadNo ratings yet
- A Styrofoam Cup Holds 0.262 KG of Water at 27.0°C....Document4 pagesA Styrofoam Cup Holds 0.262 KG of Water at 27.0°C....Malik AsadNo ratings yet
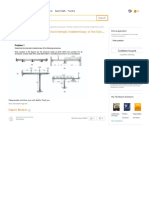
- Problem 1 Determine The Kinematic Indeterminacy Of...Document4 pagesProblem 1 Determine The Kinematic Indeterminacy Of...Malik AsadNo ratings yet
- CD Is A Manufacturing Entity That Runs A Number Of...Document3 pagesCD Is A Manufacturing Entity That Runs A Number Of...Malik AsadNo ratings yet