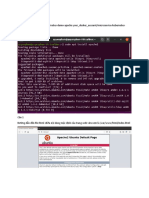
You might also like
- BTTH ch2 Tientrinh TDTT Vie p2Document11 pagesBTTH ch2 Tientrinh TDTT Vie p2Luyen Cong AnhNo ratings yet
- BTTH ch1 Tongquan Kientruc VieDocument17 pagesBTTH ch1 Tongquan Kientruc VieMinh Uyên Đào CôngNo ratings yet
- PhamThiMyDuyen BaiThucHanh Chuong4Document11 pagesPhamThiMyDuyen BaiThucHanh Chuong4Tráng ThắngNo ratings yet
- BTLT PhamThiQuyen20187195 HePhanTanDocument4 pagesBTLT PhamThiQuyen20187195 HePhanTanquyên phạmNo ratings yet
- btth - PhamThiQuyen 20187195 HẹPhanTanDocument3 pagesbtth - PhamThiQuyen 20187195 HẹPhanTanquyên phạmNo ratings yet
- thực hành hệ phân tánDocument4 pagesthực hành hệ phân tánAnonymous Pul8wpdaANo ratings yet
- Bài Tập Tổng Hợp Hệ Phân TánDocument7 pagesBài Tập Tổng Hợp Hệ Phân TánDung PhamNo ratings yet
- Bai Tap Introduction hệ phân tánDocument2 pagesBai Tap Introduction hệ phân tánPhạm Hoàng HảiNo ratings yet
- (123doc) - He-Phan-Tan-Kt-Trac-NghiemDocument15 pages(123doc) - He-Phan-Tan-Kt-Trac-NghiemNguyễn Công NguyênNo ratings yet
- báo cáo hệ phân tánDocument11 pagesbáo cáo hệ phân tánanhduc_mtt_itbk9876100% (1)
- BTLT Chap1 Tongquan Kientruc VieDocument5 pagesBTLT Chap1 Tongquan Kientruc VieNg Thế AnhNo ratings yet
- Chuong 2 HPTDocument3 pagesChuong 2 HPTDang Manh Truong50% (2)
- Btlt2 PhamThiQuyen 20187195Document3 pagesBtlt2 PhamThiQuyen 20187195quyên phạm100% (1)
- Btth2 PhamThiQuyen 20187195Document6 pagesBtth2 PhamThiQuyen 20187195quyên phạm50% (2)
- BTLT 2Document3 pagesBTLT 2Quý Nguyễn Quang100% (3)
- Hệ phân tánDocument15 pagesHệ phân tánbuicongdangNo ratings yet
- ôn tập hệ phân tán (by Q7)Document9 pagesôn tập hệ phân tán (by Q7)Hưng Huy TrầnNo ratings yet
- Báo cáo bài tập lớn hệ phân tán trang web quản lý thư việnDocument10 pagesBáo cáo bài tập lớn hệ phân tán trang web quản lý thư việnchung_nguyen_2533% (3)
- BaitapsqlDocument11 pagesBaitapsqlPhu TranNo ratings yet
- (123doc) Bai Tap He Phan Tan Co Dap An Chi TietDocument12 pages(123doc) Bai Tap He Phan Tan Co Dap An Chi TietĐình ThànhNo ratings yet
- Tuan05 ProcessDocument9 pagesTuan05 ProcessThịnh LêNo ratings yet
- Ly Thuyet Ngon Ngu Va Phuong Phap DichDocument157 pagesLy Thuyet Ngon Ngu Va Phuong Phap DichNo PromisesNo ratings yet
- BT GK NMMMTDocument21 pagesBT GK NMMMTQuang Hà MinhNo ratings yet
- Báo cáo Trí tuệ nhân tạoDocument18 pagesBáo cáo Trí tuệ nhân tạoquyên phạm100% (1)
- quản lý đồ án niên luânDocument2 pagesquản lý đồ án niên luânTrần Rainkt50% (2)
- Báo cáo quản trị mạngDocument20 pagesBáo cáo quản trị mạngNguyễn DũngNo ratings yet
- Lab 1 - Getting Comfortable With Kali LinuxDocument27 pagesLab 1 - Getting Comfortable With Kali LinuxLê Bảo Duy NgôNo ratings yet
- btlt2 PhamThiQuyen 20187195 HePhanTanDocument6 pagesbtlt2 PhamThiQuyen 20187195 HePhanTanquyên phạm75% (4)
- HCI - Cách chấm điểmDocument9 pagesHCI - Cách chấm điểmThành ĐôngNo ratings yet
- Computer NetworkingDocument74 pagesComputer NetworkingPhước NguyễnNo ratings yet
- Ôn tập trắc nghiệm Kỹ thuật truyền số liệuDocument71 pagesÔn tập trắc nghiệm Kỹ thuật truyền số liệuQuảng100% (2)
- Họ TênDocument2 pagesHọ TênJame MrrNo ratings yet
- De Thi Thuc Hanh SQLDocument3 pagesDe Thi Thuc Hanh SQLapi-3755986No ratings yet
- NT132.K11.ANTT.1 - Lab1 - 17520900-Phúc - 17521141 - ToànDocument14 pagesNT132.K11.ANTT.1 - Lab1 - 17520900-Phúc - 17521141 - ToànToan Thai QuocNo ratings yet
- Trắc nghiệmDocument55 pagesTrắc nghiệmViệt VđNo ratings yet
- Demo KerberosDocument46 pagesDemo Kerberos1531Nguyễn Linh Phú0% (1)
- BÁO CÁO PROJECT 1-TrungDocument35 pagesBÁO CÁO PROJECT 1-TrungTrung Nguyen0% (1)
- Đề cương ôn tập cuối kỳ môn Cơ sở dữ liệu (UIT)Document17 pagesĐề cương ôn tập cuối kỳ môn Cơ sở dữ liệu (UIT)Tuấn Đặng MinhNo ratings yet
- Cau Hoi Va Bai Tap On Tap He Dieu Hanh 1Document41 pagesCau Hoi Va Bai Tap On Tap He Dieu Hanh 1trdangkhoa199289% (9)
- 100 Câu HĐHDocument15 pages100 Câu HĐHThanh Thủy100% (1)
- Đề thi mẫu Đáp án tham khảoDocument4 pagesĐề thi mẫu Đáp án tham khảoNguyễn Bình MinhNo ratings yet
- một số mô thức lập trình.Document22 pagesmột số mô thức lập trình.Do Ba Manh88% (8)
- He Phan TanDocument59 pagesHe Phan Tankajerin100% (1)
- Câu hỏi BGPDocument5 pagesCâu hỏi BGPTuấn Totti100% (1)
- Lession 03 - TCP - IP - V2.0Document158 pagesLession 03 - TCP - IP - V2.0Vũ Thiện TâmNo ratings yet
- CÂU HỎI ÔN TẬP MÔN CÔNG NGHỆ MẠNG KHÔNG DÂYDocument8 pagesCÂU HỎI ÔN TẬP MÔN CÔNG NGHỆ MẠNG KHÔNG DÂYHoàng QuânNo ratings yet
- Đề giao thứcDocument28 pagesĐề giao thứcTiến Đạt BùiNo ratings yet
- Baitap 1Document2 pagesBaitap 1Nguyễn Duy ĐạtNo ratings yet
- (123doc) Xay Dung Chuong Trinh Mo Phong Cac Giai Thuat Dinh Thoi Cho CpuDocument42 pages(123doc) Xay Dung Chuong Trinh Mo Phong Cac Giai Thuat Dinh Thoi Cho CpuNa Nguyễn LêNo ratings yet
- Ôn tập Hệ Phân TánDocument9 pagesÔn tập Hệ Phân Tánchieu dinh100% (1)
- Trainning HDHDocument104 pagesTrainning HDHVũ MichaelNo ratings yet
- Cau Hoi Bai Tap Mang May TinhDocument59 pagesCau Hoi Bai Tap Mang May TinhVũ Hữu Cường0% (1)
- KYANH Phân Tích Gói Tinh Httpgaia - Cs.umass - EduDocument4 pagesKYANH Phân Tích Gói Tinh Httpgaia - Cs.umass - EduTinh nguyen0% (1)
- Bảng Băm Phân Tán (DHT) và Mạng Ngang Hàng ChordDocument49 pagesBảng Băm Phân Tán (DHT) và Mạng Ngang Hàng ChordThinkPad100% (2)
- Bài Tập Thực Hành Số 2 Môn Học: Nhập Môn Mạng Máy TínhDocument7 pagesBài Tập Thực Hành Số 2 Môn Học: Nhập Môn Mạng Máy TínhVăn Đức DuyNo ratings yet
- BTTH ch4 Dongbohoa VieDocument11 pagesBTTH ch4 Dongbohoa VieLê Thanh TùngNo ratings yet
- 14-Advanced Topics in JavaDocument32 pages14-Advanced Topics in Javahanguyenb1a4No ratings yet
- Lab05 MultiThreadingDocument25 pagesLab05 MultiThreadingThành ĐạtNo ratings yet
- Bai 17 - Xay dung ung dung voi WebService - AsynTask ver 3Document9 pagesBai 17 - Xay dung ung dung voi WebService - AsynTask ver 3Dinh Thanh ChuNo ratings yet
- (123doc) - Bai-On-Thi-Lap-Trinh-Huong-Doi-TuongDocument2 pages(123doc) - Bai-On-Thi-Lap-Trinh-Huong-Doi-TuongHung NguyênNo ratings yet
- Short 6591576100831232 Document Daodanghuy 20176782 .1mDocument1 pageShort 6591576100831232 Document Daodanghuy 20176782 .1mchieu dinhNo ratings yet
- Intern Report Template-1Document1 pageIntern Report Template-1chieu dinhNo ratings yet
- DCCT CachethongphantanDocument21 pagesDCCT Cachethongphantanchieu dinhNo ratings yet
- Dethi HPT 20171-CQDocument2 pagesDethi HPT 20171-CQchieu dinhNo ratings yet
- Chuong 6Document1 pageChuong 6chieu dinhNo ratings yet
- Baocao Chuong Trinh DichDocument4 pagesBaocao Chuong Trinh DichHeo Hóm Hỉnh100% (1)
- He PTDocument20 pagesHe PTchieu dinhNo ratings yet
- Bản bàn giao công việcDocument2 pagesBản bàn giao công việcchieu dinhNo ratings yet
- Báo Cáo Theo Dõi Công N AP6-AP5 T1.2019-T4.2021Document315 pagesBáo Cáo Theo Dõi Công N AP6-AP5 T1.2019-T4.2021chieu dinhNo ratings yet
- Hệ điều hành VxWorksDocument2 pagesHệ điều hành VxWorkschieu dinhNo ratings yet
- Ôn tập Hệ Phân TánDocument9 pagesÔn tập Hệ Phân Tánchieu dinh100% (1)
- Trinh-Bien-Dich - Nguyen-Thi-Thu-Huong - Unit5-Bo-Phan-Tich-Tu-Vung - (Cuuduongthancong - Com)Document4 pagesTrinh-Bien-Dich - Nguyen-Thi-Thu-Huong - Unit5-Bo-Phan-Tich-Tu-Vung - (Cuuduongthancong - Com)chieu dinhNo ratings yet
- Bai Tap He NhungDocument3 pagesBai Tap He Nhungchieu dinhNo ratings yet
- Hệ điều hành VxWorksDocument2 pagesHệ điều hành VxWorkschieu dinhNo ratings yet
- Free RTOSDocument2 pagesFree RTOSchieu dinhNo ratings yet