You might also like
- Session-5 MCQDocument3 pagesSession-5 MCQsanathNo ratings yet
- Session-7 MCQ: O F 1 in O F 1 in O F F inDocument3 pagesSession-7 MCQ: O F 1 in O F 1 in O F F insanathNo ratings yet
- Session-4 MCQDocument3 pagesSession-4 MCQsanathNo ratings yet
- Session-1 MCQDocument3 pagesSession-1 MCQsanathNo ratings yet
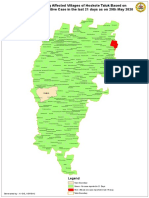
- Map Showing Affected Villages of Hoskote Taluk Based On Atleast One Positive Case in The Last 21 Days As On 29th May 2020Document1 pageMap Showing Affected Villages of Hoskote Taluk Based On Atleast One Positive Case in The Last 21 Days As On 29th May 2020sanathNo ratings yet
- " Free Space Optical Communication": Visvesvaraya Technological UniversityDocument25 pages" Free Space Optical Communication": Visvesvaraya Technological UniversitysanathNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5796)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Chapter 7 Pushdown AutomataDocument9 pagesChapter 7 Pushdown AutomataBharath ChoudharyNo ratings yet
- Programs With Flowchart and AlgorithmDocument7 pagesPrograms With Flowchart and AlgorithmRadhika AjadkaNo ratings yet
- Computational Science and EngineeringDocument6 pagesComputational Science and EngineeringPrince ManzanoNo ratings yet
- CH 27Document16 pagesCH 27Varsha Abhijeet UchagaonkarNo ratings yet
- PG - M.Sc. - Mathematics - 31132 OPTIMIZATION TECHNIQUESDocument130 pagesPG - M.Sc. - Mathematics - 31132 OPTIMIZATION TECHNIQUESvictworks01No ratings yet
- Python Data Science Cookbook - (Index)Document9 pagesPython Data Science Cookbook - (Index)crystal chukuemekaNo ratings yet
- Cse329:Prelude To Competitive Coding: Course OutcomesDocument3 pagesCse329:Prelude To Competitive Coding: Course OutcomesClash With GROUDONNo ratings yet
- WADocument31 pagesWAStokstaart2002No ratings yet
- Gradient Based Particle SwarmDocument7 pagesGradient Based Particle SwarmRavi DadsenaNo ratings yet
- MFDS - All Webinars-MinDocument121 pagesMFDS - All Webinars-MinLok BharatenduNo ratings yet
- Notes On Data Structures and Programming Techniques (CPSC 223, Spring 2021)Document659 pagesNotes On Data Structures and Programming Techniques (CPSC 223, Spring 2021)KALKA DUBEYNo ratings yet
- Linear Programming: The Simplex MethodDocument29 pagesLinear Programming: The Simplex Methodchauhan_88100% (1)
- Discrete-Time Digital Signal Processing - Oppenheim, Schafer & Buck PDFDocument895 pagesDiscrete-Time Digital Signal Processing - Oppenheim, Schafer & Buck PDFKishanNo ratings yet
- I2EA 2 Binary Search PDocument12 pagesI2EA 2 Binary Search Pkomarovischool8No ratings yet
- O'Connor - RPGLab: A Matlab Package For Random Permutation GenerationDocument36 pagesO'Connor - RPGLab: A Matlab Package For Random Permutation GenerationDerek O'ConnorNo ratings yet
- Association Rule MiningDocument54 pagesAssociation Rule Mininghawariya abelNo ratings yet
- 25.memory Representation of Float Data Type in CDocument4 pages25.memory Representation of Float Data Type in CGanesh NimbolkarNo ratings yet
- Bic Easy HardDocument30 pagesBic Easy Hardmaria10018012No ratings yet
- Problem V. The Old Saint and Three Questions: 500 Ms LinuxDocument2 pagesProblem V. The Old Saint and Three Questions: 500 Ms LinuxGilson BravoNo ratings yet
- Module 7 AutomataDocument7 pagesModule 7 AutomataShruti Daddy's AngelNo ratings yet
- Jawaban SOAL LINEAR PROGRAMMING 2 Ihsan Faizal Malik 183402096Document3 pagesJawaban SOAL LINEAR PROGRAMMING 2 Ihsan Faizal Malik 183402096Ihsan Faizal MalikNo ratings yet
- ExamDocument12 pagesExamAidar MukushevNo ratings yet
- Mutna LogikaDocument10 pagesMutna LogikaDamir MiletaNo ratings yet
- An Oil Pipeline Design ProblemDocument13 pagesAn Oil Pipeline Design ProblemThe GantengNo ratings yet
- Program:: Sri Sai Aditya Institute of Science and TechnologyDocument5 pagesProgram:: Sri Sai Aditya Institute of Science and TechnologyRajeev NakkaNo ratings yet
- Operators & Assignments Question 1 Class EBH019 (Public StaticDocument19 pagesOperators & Assignments Question 1 Class EBH019 (Public Staticrahul rastogiNo ratings yet
- CCS353 Set1Document3 pagesCCS353 Set1Bebi RajNo ratings yet
- Lesson Plan: Ma 2266 Statistics and Numerical MethodsDocument6 pagesLesson Plan: Ma 2266 Statistics and Numerical MethodsANANDNo ratings yet
- Homework Week 5 TreesDocument6 pagesHomework Week 5 TreesLe Thi Cam Nhung100% (1)
- Birthday Paradox - A Simulation of Shared Birthday ExperimentsDocument13 pagesBirthday Paradox - A Simulation of Shared Birthday Experimentsdatalore100% (1)