You might also like
- Artificial Intelligence Interview QuestionsFrom EverandArtificial Intelligence Interview QuestionsRating: 5 out of 5 stars5/5 (2)
- DATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSFrom EverandDATA MINING AND MACHINE LEARNING. PREDICTIVE TECHNIQUES: REGRESSION, GENERALIZED LINEAR MODELS, SUPPORT VECTOR MACHINE AND NEURAL NETWORKSNo ratings yet
- QuestionDocument30 pagesQuestionJustin GomezNo ratings yet
- Machine Learning - A Comprehensive, Step-by-Step Guide to Learning and Applying Advanced Concepts and Techniques in Machine Learning: 3From EverandMachine Learning - A Comprehensive, Step-by-Step Guide to Learning and Applying Advanced Concepts and Techniques in Machine Learning: 3No ratings yet
- Ai Questions and AnswersDocument6 pagesAi Questions and AnswersShravan S NairNo ratings yet
- Practical Full Stack Machine Learning: A Guide to Build Reliable, Reusable, and Production-Ready Full Stack ML SolutionsFrom EverandPractical Full Stack Machine Learning: A Guide to Build Reliable, Reusable, and Production-Ready Full Stack ML SolutionsNo ratings yet
- ML, DL Questions: Downloaded FromDocument4 pagesML, DL Questions: Downloaded FromAryan RajNo ratings yet
- DATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABFrom EverandDATA MINING and MACHINE LEARNING. PREDICTIVE TECHNIQUES: ENSEMBLE METHODS, BOOSTING, BAGGING, RANDOM FOREST, DECISION TREES and REGRESSION TREES.: Examples with MATLABNo ratings yet
- Java/J2EE Design Patterns Interview Questions You'll Most Likely Be Asked: Second EditionFrom EverandJava/J2EE Design Patterns Interview Questions You'll Most Likely Be Asked: Second EditionNo ratings yet
- Image Classification: Step-by-step Classifying Images with Python and Techniques of Computer Vision and Machine LearningFrom EverandImage Classification: Step-by-step Classifying Images with Python and Techniques of Computer Vision and Machine LearningNo ratings yet
- Mastering Classification Algorithms for Machine Learning: Learn how to apply Classification algorithms for effective Machine Learning solutions (English Edition)From EverandMastering Classification Algorithms for Machine Learning: Learn how to apply Classification algorithms for effective Machine Learning solutions (English Edition)No ratings yet
- Waterfall model, Prototyping model, Agile development model comparisonDocument8 pagesWaterfall model, Prototyping model, Agile development model comparisonGUCI NKCNo ratings yet
- Optimizers For NeuralNetworksDocument13 pagesOptimizers For NeuralNetworksAbhishek SainiNo ratings yet
- 13 Useful Deep Learning Interview Questions and AnswerDocument6 pages13 Useful Deep Learning Interview Questions and AnswerMD. SHAHIDUL ISLAMNo ratings yet
- Machine Learning Presentation for Industrial TrainingDocument25 pagesMachine Learning Presentation for Industrial Trainingshveta074No ratings yet
- DEEP LEARNING TECHNIQUES: CLUSTER ANALYSIS and PATTERN RECOGNITION with NEURAL NETWORKS. Examples with MATLABFrom EverandDEEP LEARNING TECHNIQUES: CLUSTER ANALYSIS and PATTERN RECOGNITION with NEURAL NETWORKS. Examples with MATLABNo ratings yet
- Unit 1Document20 pagesUnit 1aswinhacker28No ratings yet
- ML Questions Part 2: Downloaded FromDocument5 pagesML Questions Part 2: Downloaded FromPawan PatankarNo ratings yet
- Interview Questions Set 3Document4 pagesInterview Questions Set 3Aryan RajNo ratings yet
- Machine Learning YearningDocument116 pagesMachine Learning Yearningglory mNo ratings yet
- BigData Assessment2 26230605Document14 pagesBigData Assessment2 26230605abaid choughtaiNo ratings yet
- Represented Using Tensors, and As A Result, Neural Network Programming UtilizesDocument32 pagesRepresented Using Tensors, and As A Result, Neural Network Programming UtilizesYogesh KrishnaNo ratings yet
- Pragmatic Machine Learning with Python: Learn How to Deploy Machine Learning Models in ProductionFrom EverandPragmatic Machine Learning with Python: Learn How to Deploy Machine Learning Models in ProductionNo ratings yet
- Machine Learning: Hands-On for Developers and Technical ProfessionalsFrom EverandMachine Learning: Hands-On for Developers and Technical ProfessionalsNo ratings yet
- Machine Learning Algorithm Classifies Banana Diseases from Leaf ImagesDocument27 pagesMachine Learning Algorithm Classifies Banana Diseases from Leaf ImagesDavis DavidNo ratings yet
- DATA MINING and MACHINE LEARNING: CLUSTER ANALYSIS and kNN CLASSIFIERS. Examples with MATLABFrom EverandDATA MINING and MACHINE LEARNING: CLUSTER ANALYSIS and kNN CLASSIFIERS. Examples with MATLABNo ratings yet
- Internet of Things (IoT) A Quick Start Guide: A to Z of IoT EssentialsFrom EverandInternet of Things (IoT) A Quick Start Guide: A to Z of IoT EssentialsNo ratings yet
- Report Sentiment Analysis Marcos MatheusDocument12 pagesReport Sentiment Analysis Marcos Matheusjfernandesj13No ratings yet
- ML Projects For Final YearDocument7 pagesML Projects For Final YearAlia KhanNo ratings yet
- Intro To Machine Learning ND SyllabusDocument4 pagesIntro To Machine Learning ND SyllabusGk0ur0uNo ratings yet
- Using Pre-Trained ModelsDocument16 pagesUsing Pre-Trained Modelssmartin1970No ratings yet
- 50 Advanced Machine Learning Questions - ChatGPTDocument18 pages50 Advanced Machine Learning Questions - ChatGPTLily Lauren100% (1)
- DP-Designing and ImplementingDocument10 pagesDP-Designing and ImplementingSteven DohNo ratings yet
- Top Data Science Interview Questions and Answers in 2023 PDFDocument14 pagesTop Data Science Interview Questions and Answers in 2023 PDFChristine Cao100% (1)
- Smarter Decisions – The Intersection of Internet of Things and Decision ScienceFrom EverandSmarter Decisions – The Intersection of Internet of Things and Decision ScienceNo ratings yet
- Select and Train Models for Machine Learning ProjectsDocument29 pagesSelect and Train Models for Machine Learning ProjectsBhuwan BhattNo ratings yet
- Anomaly Detection in Images CIFAR-10Document9 pagesAnomaly Detection in Images CIFAR-10Mallikarjun patilNo ratings yet
- Machine Learning: Adaptive Behaviour Through Experience: Thinking MachinesFrom EverandMachine Learning: Adaptive Behaviour Through Experience: Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (5)
- machine_learning_section2_ebookDocument16 pagesmachine_learning_section2_ebookcamgovaNo ratings yet
- Conclusion and Future Scopes 5.1 ConclusionDocument3 pagesConclusion and Future Scopes 5.1 Conclusionshikhar guptaNo ratings yet
- Importany Questions Unit 3 4Document30 pagesImportany Questions Unit 3 4Mubena HussainNo ratings yet
- Master Thesis AlgorithmDocument6 pagesMaster Thesis Algorithmjennifergutierrezmilwaukee100% (2)
- Machine Learning with Clustering: A Visual Guide for Beginners with Examples in PythonFrom EverandMachine Learning with Clustering: A Visual Guide for Beginners with Examples in PythonNo ratings yet
- MACHINE LEARNING FOR BEGINNERS: A Practical Guide to Understanding and Applying Machine Learning Concepts (2023 Beginner Crash Course)From EverandMACHINE LEARNING FOR BEGINNERS: A Practical Guide to Understanding and Applying Machine Learning Concepts (2023 Beginner Crash Course)No ratings yet
- Tesla Stock Marketing Price PredictionDocument62 pagesTesla Stock Marketing Price Predictionsyedhaji1996No ratings yet
- 07two Marks Quest & AnsDocument4 pages07two Marks Quest & AnsV MERIN SHOBINo ratings yet
- Machine Learning Interview Preparation: Day 09Document9 pagesMachine Learning Interview Preparation: Day 09ARPAN MAITYNo ratings yet
- Agile Software Development CDocument17 pagesAgile Software Development CAhsan ChNo ratings yet
- Develop A Program To Implement Data Preprocessing UsingDocument19 pagesDevelop A Program To Implement Data Preprocessing UsingFucker JamunNo ratings yet
- Machine Learning with Python: A Comprehensive Guide with a Practical ExampleFrom EverandMachine Learning with Python: A Comprehensive Guide with a Practical ExampleNo ratings yet
- Machine LearningDocument25 pagesMachine LearningParth NagarNo ratings yet
- AA SL P2 Practice Paper Set 1 SolutionDocument7 pagesAA SL P2 Practice Paper Set 1 SolutionAmmar PasanovicNo ratings yet
- Week 1Document5 pagesWeek 1Mrunal BhilareNo ratings yet
- Digital Signal Analysis and Processing (3-1-2) CourseDocument2 pagesDigital Signal Analysis and Processing (3-1-2) CourseSubodh dhungelNo ratings yet
- Solution To Statistical Physics Exam: 29th June 2015Document13 pagesSolution To Statistical Physics Exam: 29th June 2015*83*22*No ratings yet
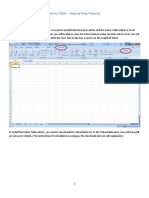
- Solver Table Tutorial PDFDocument6 pagesSolver Table Tutorial PDFsagar maniarNo ratings yet
- B - Lecture3 The Transfer Function and Block Diagram Automatic Control SystemDocument21 pagesB - Lecture3 The Transfer Function and Block Diagram Automatic Control SystemAbaziz Mousa OutlawZz100% (1)
- Peng, Bo y Otros A Meta-Analysis of International Tourism Demand Forecasting andDocument13 pagesPeng, Bo y Otros A Meta-Analysis of International Tourism Demand Forecasting andEdith López CiucciNo ratings yet
- Coloring ProblemsDocument13 pagesColoring ProblemswistfulmemoryNo ratings yet
- Artificial Intelligence in Medicine Book - 2022 - 1Document18 pagesArtificial Intelligence in Medicine Book - 2022 - 1pedroNo ratings yet
- SRI KRISHNADEVARAYA UNIVERSITY ANANTAPUR TIME TABLE FOR PG EXAMSDocument12 pagesSRI KRISHNADEVARAYA UNIVERSITY ANANTAPUR TIME TABLE FOR PG EXAMSYashwanth JvNo ratings yet
- Unit 12 - Week 11Document3 pagesUnit 12 - Week 11sanjay.diddeeNo ratings yet
- The+Student's+t DistributionDocument7 pagesThe+Student's+t DistributionAmarnathMaitiNo ratings yet
- CSF-429 - L7 Word Vectors - GloveDocument24 pagesCSF-429 - L7 Word Vectors - GloveManan PopatNo ratings yet
- Institute of Space Technology: Submitted byDocument12 pagesInstitute of Space Technology: Submitted byMesum IrfaniNo ratings yet
- 1 IFEM Outline 13Document2 pages1 IFEM Outline 13danbradeanuNo ratings yet
- Crypto Assignment 2019Document3 pagesCrypto Assignment 2019Ankit BagdeNo ratings yet
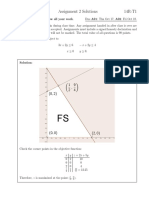
- MATH 1010 Assignment 2 Solutions 14R-T1: SolutionDocument9 pagesMATH 1010 Assignment 2 Solutions 14R-T1: SolutionFarhad KhanNo ratings yet
- Data Science Intern - JD - ZIGRAMDocument8 pagesData Science Intern - JD - ZIGRAMLakshay MadaanNo ratings yet
- Neural Networks and Fuzzy Systems: Multi-Layer Feed Forward NetworksDocument27 pagesNeural Networks and Fuzzy Systems: Multi-Layer Feed Forward NetworksmesferNo ratings yet
- Fault Tolerance ExamDocument14 pagesFault Tolerance Examahmadhassan306No ratings yet
- DCSPDocument116 pagesDCSPCompaniaDekartSRLNo ratings yet
- Click Here For Download: (PDF) The Life and Times of Grigorii RasputinDocument2 pagesClick Here For Download: (PDF) The Life and Times of Grigorii RasputinМаргарет Вејд0% (1)
- Probability Distribution of Discrete Random VariableDocument1 pageProbability Distribution of Discrete Random VariableGladzangel LoricabvNo ratings yet
- String Matching Introduction To NP-CompletenessDocument37 pagesString Matching Introduction To NP-Completeness20DCS009 DEVANSHI BHATTNo ratings yet
- 2CS301 - Data Structure and AlgorithmsDocument2 pages2CS301 - Data Structure and AlgorithmsIshan MakadiaNo ratings yet
- CHEE3367 - Process Control © M. Nikolaou, University of HoustonDocument7 pagesCHEE3367 - Process Control © M. Nikolaou, University of HoustonΜιχάλης ΝικολάουNo ratings yet
- Information Security Unit-2 - 9 HMACDocument4 pagesInformation Security Unit-2 - 9 HMACLokesh Sai Kumar DasariNo ratings yet
- New Frontiers in Graph TheoryDocument526 pagesNew Frontiers in Graph TheorySheshera Mysore100% (1)
- Chapter 2-Part 4Document21 pagesChapter 2-Part 4Farah HaniNo ratings yet
- Day 14 Ws 1000 Questions SeriesDocument23 pagesDay 14 Ws 1000 Questions SeriesArunNo ratings yet