You might also like
- USM Students Design Automatic Page Turner for People with DisabilitiesDocument2 pagesUSM Students Design Automatic Page Turner for People with DisabilitiesAbdul MohsinNo ratings yet
- 2019 MakeX Courageous Traveler Techinical Guide V1.1Document66 pages2019 MakeX Courageous Traveler Techinical Guide V1.1Yair XolalpaNo ratings yet
- 722.6 Transmission Conductor Plate Replacement DIYDocument3 pages722.6 Transmission Conductor Plate Replacement DIYcamaro67427100% (1)
- Accident Detection System: Bachelor of Science (Information Technology)Document31 pagesAccident Detection System: Bachelor of Science (Information Technology)vivekNo ratings yet
- Leaf Health Detection Using Python and Open Computer VisionDocument1 pageLeaf Health Detection Using Python and Open Computer VisionRavivarNo ratings yet
- CA971 - Blood Bank Management SystemDocument63 pagesCA971 - Blood Bank Management SystemSYED FARHAN REZANo ratings yet
- Child Tracking Project Report-2Document62 pagesChild Tracking Project Report-2Manish Kumar SahaniNo ratings yet
- Accident Alert SystemDocument23 pagesAccident Alert SystemTrupti PattankudiNo ratings yet
- Final Year ProjectDocument47 pagesFinal Year ProjectKodandaNo ratings yet
- 1steam EngineDocument6 pages1steam Enginesatendrapalsingh3100% (1)
- Cse 498r ReportDocument33 pagesCse 498r ReportSamina YesminNo ratings yet
- Forest Fire Detection Using Sensor NetworksDocument13 pagesForest Fire Detection Using Sensor NetworksMuskan AgarwalNo ratings yet
- Computer Science Engineering: An International Journal (CSEIJ)Document2 pagesComputer Science Engineering: An International Journal (CSEIJ)cseijNo ratings yet
- Automated Algorithmic Trading System Project ReportDocument81 pagesAutomated Algorithmic Trading System Project ReportATHARVA KNo ratings yet
- Building An Efficient Intrusion Detection System Using Feature Selection and Machine LearningDocument12 pagesBuilding An Efficient Intrusion Detection System Using Feature Selection and Machine LearningIJRASETPublications100% (1)
- Seminar Report Machine LearningDocument20 pagesSeminar Report Machine LearningHavish SRNo ratings yet
- Python Projects Download With Source Code, Database and ReportsDocument43 pagesPython Projects Download With Source Code, Database and Reportsmohan dewanganNo ratings yet
- Project ZooDocument8 pagesProject ZooUts HavNo ratings yet
- Android Project Project NptelDocument19 pagesAndroid Project Project NptelVivek KumarNo ratings yet
- Agro System Crop PredictionDocument34 pagesAgro System Crop PredictionTejashri S JNo ratings yet
- Fake News Detector Using ML ClassifiersDocument22 pagesFake News Detector Using ML ClassifiersMenma100% (1)
- Project Report Toxic Comment ClassifierDocument25 pagesProject Report Toxic Comment ClassifierAshish KumarNo ratings yet
- Seminar Report 032Document32 pagesSeminar Report 032046 KISHORENo ratings yet
- Jinendra Major ProjectDocument127 pagesJinendra Major ProjectArham KhanNo ratings yet
- Main Project (Batch - 9)Document57 pagesMain Project (Batch - 9)RamNo ratings yet
- P4 Project ReportDocument28 pagesP4 Project ReportBrij MaheshwariNo ratings yet
- Image - Encryption - and - Decryption - BA DocumentationDocument33 pagesImage - Encryption - and - Decryption - BA DocumentationManikandanNo ratings yet
- LAN Security Manager PDFDocument47 pagesLAN Security Manager PDFRafikiNo ratings yet
- Handwritten Digits RecognitionDocument27 pagesHandwritten Digits RecognitionSubi PapaNo ratings yet
- University Mangament System Using Artificial IntelligenceDocument14 pagesUniversity Mangament System Using Artificial IntelligenceMahar Ali RazaNo ratings yet
- MCA Project Report Format - MU - UpdatedDocument20 pagesMCA Project Report Format - MU - Updatedromi Kushwaha100% (1)
- Human Robot Collaboration: A Case Study Report OnDocument12 pagesHuman Robot Collaboration: A Case Study Report OnNPMYS23No ratings yet
- Project1 ReportDocument31 pagesProject1 ReportAshis MohantyNo ratings yet
- Event Registration: Minor Project Report OnDocument37 pagesEvent Registration: Minor Project Report OnAkhil ChourasiyaNo ratings yet
- Helmet Detect ReportDocument29 pagesHelmet Detect ReportDeepak0% (1)
- Major Project ReportDocument22 pagesMajor Project ReportRohini VhatkarNo ratings yet
- Privacy Policy Prediction for User ImagesDocument35 pagesPrivacy Policy Prediction for User ImagesTaha ShaikhNo ratings yet
- Automated Invigilation Assignment SystemDocument25 pagesAutomated Invigilation Assignment SystemARCHANA100% (1)
- Internship ReportDocument22 pagesInternship ReportSindhu GNo ratings yet
- Project Report UmangDocument99 pagesProject Report UmangUmang BholaNo ratings yet
- Project Report PDFDocument52 pagesProject Report PDFharsh tanejaNo ratings yet
- A Mini Project ReportDocument54 pagesA Mini Project ReportPosi NamdamNo ratings yet
- Mini Project ReportDocument10 pagesMini Project ReportAbhishek Hegde0% (1)
- Artificial Intelligence ReportDocument6 pagesArtificial Intelligence ReportSurbhi NemaNo ratings yet
- My Internship ReportDocument29 pagesMy Internship ReportAfaf AhmedNo ratings yet
- Human Hand Gestures Capturing and Recognition Via CameraDocument64 pagesHuman Hand Gestures Capturing and Recognition Via CameraBharathNo ratings yet
- Visvesvaraya Technological University: BELAGAVI-590018Document25 pagesVisvesvaraya Technological University: BELAGAVI-590018Pruthvi ReddyNo ratings yet
- A Project ReportDocument40 pagesA Project ReportDeep PunjabiNo ratings yet
- Face Mask Detection ProjectDocument57 pagesFace Mask Detection Projectakhil rebelsNo ratings yet
- Final Thesis - 16Document24 pagesFinal Thesis - 16shanmukhaNo ratings yet
- Anush J Internship ReportDocument15 pagesAnush J Internship ReportDeepak VasudevNo ratings yet
- Software Engineering Interview Questions PDFDocument6 pagesSoftware Engineering Interview Questions PDFscatNo ratings yet
- Ankit Singh (1812710008) and Anurag Chauhan (1812710010) B.tech Cse 2022 8th Sem Project, Tours and Travels Management SystemDocument90 pagesAnkit Singh (1812710008) and Anurag Chauhan (1812710010) B.tech Cse 2022 8th Sem Project, Tours and Travels Management SystemShivraj CyberNo ratings yet
- Cloth Donation SystemDocument57 pagesCloth Donation SystemI NoNo ratings yet
- Virtual Mouse Control Using A Web CameraDocument14 pagesVirtual Mouse Control Using A Web CameraThennarasu Ramachandran100% (1)
- Face DetectionDocument14 pagesFace DetectionShivangani AnkitNo ratings yet
- Final Year Project List ECE, ICE, CSE, IT, EEE, Mech (Jntu Final Year Projects)Document9 pagesFinal Year Project List ECE, ICE, CSE, IT, EEE, Mech (Jntu Final Year Projects)nirvanaofworldNo ratings yet
- Project - Farmers BuddyDocument34 pagesProject - Farmers BuddyGunjit MakhijaNo ratings yet
- Machine Learning with Python: Design and Develop Machine Learning and Deep Learning Technique using real world code examplesFrom EverandMachine Learning with Python: Design and Develop Machine Learning and Deep Learning Technique using real world code examplesNo ratings yet
- Smart Material Systems and MEMS: Design and Development MethodologiesFrom EverandSmart Material Systems and MEMS: Design and Development MethodologiesNo ratings yet
- BTP Final ReportDocument40 pagesBTP Final ReportvarshitaNo ratings yet
- Ilovepdf Merged PDFDocument55 pagesIlovepdf Merged PDFSai kumarNo ratings yet
- MID TERM EXAMINATIONDocument3 pagesMID TERM EXAMINATIONIshant SadhawaniNo ratings yet
- Anu Priya - CGMM AssgnDocument3 pagesAnu Priya - CGMM AssgnIshant SadhawaniNo ratings yet
- SC Paper PDFDocument1 pageSC Paper PDFIshant SadhawaniNo ratings yet
- InstructionsDocument5 pagesInstructionsIshant SadhawaniNo ratings yet
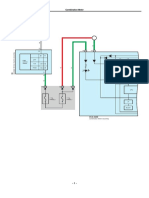
- Combination Meter: D1 (A), D2 (B)Document10 pagesCombination Meter: D1 (A), D2 (B)PeterNo ratings yet
- 18.443 MIT Stats CourseDocument139 pages18.443 MIT Stats CourseAditya JainNo ratings yet
- Babylonian Mathematics (Also Known As Assyro-BabylonianDocument10 pagesBabylonian Mathematics (Also Known As Assyro-BabylonianNirmal BhowmickNo ratings yet
- CRT 48-35L PS EuDocument35 pagesCRT 48-35L PS Eujose alvaradoNo ratings yet
- Ch1 - A Perspective On TestingDocument41 pagesCh1 - A Perspective On TestingcnshariffNo ratings yet
- Hazardous Area ClassificationDocument100 pagesHazardous Area Classificationcherif yahyaouiNo ratings yet
- Basic Vacuum Theory PDFDocument17 pagesBasic Vacuum Theory PDFada guevarraNo ratings yet
- Yoki 644 LPV BS - 7250215 - SDS - EU - 7923568Document14 pagesYoki 644 LPV BS - 7250215 - SDS - EU - 7923568MohamedAhmedShawkyNo ratings yet
- Radproduction Chapter 2-9Document276 pagesRadproduction Chapter 2-9Christian DioNo ratings yet
- Fireclass: FC503 & FC506Document16 pagesFireclass: FC503 & FC506Mersal AliraqiNo ratings yet
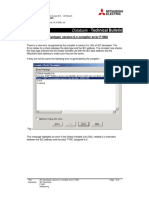
- IEC Developer version 6.n compiler error F1002Document6 pagesIEC Developer version 6.n compiler error F1002AnddyNo ratings yet
- Questions Related To Open Channel Flow.Document3 pagesQuestions Related To Open Channel Flow.Mohd AmirNo ratings yet
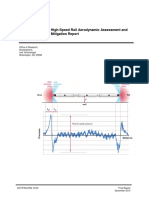
- Pressure Variation in Tunnels Sealed Trains PDFDocument258 pagesPressure Variation in Tunnels Sealed Trains PDFsivasankarNo ratings yet
- Rizal's Works Inspire Filipino PrideDocument2 pagesRizal's Works Inspire Filipino PrideItzLian SanchezNo ratings yet
- Trends and Fads in Business SVDocument2 pagesTrends and Fads in Business SVMarie-Anne DentzerNo ratings yet
- Quick Guide in The Preparation of Purchase Request (PR), Purchase Order (PO) and Other Related DocumentsDocument26 pagesQuick Guide in The Preparation of Purchase Request (PR), Purchase Order (PO) and Other Related DocumentsMiguel VasquezNo ratings yet
- Railway Reservation System - ConciseDocument38 pagesRailway Reservation System - ConciseTECH CodeNo ratings yet
- Text EditorDocument2 pagesText EditorVarunNo ratings yet
- SRFP 2015 Web List PDFDocument1 pageSRFP 2015 Web List PDFabhishekNo ratings yet
- Materiality of Cultural ConstructionDocument3 pagesMateriality of Cultural ConstructionPaul YeboahNo ratings yet
- Time: 3 Hours Total Marks: 100: Printed Page 1 of 2 Sub Code: KEE302Document2 pagesTime: 3 Hours Total Marks: 100: Printed Page 1 of 2 Sub Code: KEE302AvinäshShärmaNo ratings yet
- Equipment & Piping Layout T.N. GopinathDocument88 pagesEquipment & Piping Layout T.N. Gopinathhirenkumar patelNo ratings yet
- Writing in Bengali - : Past and PresentDocument3 pagesWriting in Bengali - : Past and PresentRanjanNo ratings yet
- REHAU 20UFH InstallationDocument84 pagesREHAU 20UFH InstallationngrigoreNo ratings yet
- Speed, Velocity and FrictionDocument10 pagesSpeed, Velocity and FrictionCristie Ann GuiamNo ratings yet
- 1 Shane Fitzsimons - TATA SonsDocument8 pages1 Shane Fitzsimons - TATA Sonsvikashs srivastavaNo ratings yet
- Presentation 5 1Document76 pagesPresentation 5 1Anshul SinghNo ratings yet
- Sketch 5351a Lo LCD Key Uno 1107Document14 pagesSketch 5351a Lo LCD Key Uno 1107nobcha aNo ratings yet