You might also like
- Microsoft Azure Cognitive Services Custom VisionDocument14 pagesMicrosoft Azure Cognitive Services Custom VisiondevaindranNo ratings yet
- Administrator's Guide To Portal Capabilities For Microsoft Dynamics 365 PDFDocument328 pagesAdministrator's Guide To Portal Capabilities For Microsoft Dynamics 365 PDFJohn DrewNo ratings yet
- Central Authentication Service CAS Complete Self-Assessment GuideFrom EverandCentral Authentication Service CAS Complete Self-Assessment GuideNo ratings yet
- Active Directory Migrations A Complete Guide - 2020 EditionFrom EverandActive Directory Migrations A Complete Guide - 2020 EditionNo ratings yet
- Webcam Setup - ArchWiki PDFDocument8 pagesWebcam Setup - ArchWiki PDFAlina OtellNo ratings yet
- Absolute Backdoor RevisitedDocument21 pagesAbsolute Backdoor RevisitedpaulnidNo ratings yet
- Snort_Apache_SSL_PHP_MySQL_BASE InstallDocument20 pagesSnort_Apache_SSL_PHP_MySQL_BASE InstallĐỗ Quốc ToảnNo ratings yet
- Installing Moodle On Windows Server 2008 R2 x64Document17 pagesInstalling Moodle On Windows Server 2008 R2 x64alex_pearceNo ratings yet
- Seo Cheat Sheet PDFDocument2 pagesSeo Cheat Sheet PDFScott JohnsonNo ratings yet
- Boot RootDocument26 pagesBoot RootdjstinkyNo ratings yet
- AGORA Low Level Design Document Rev2Document53 pagesAGORA Low Level Design Document Rev2shree_mishra25No ratings yet
- Open Source Lab ManualDocument84 pagesOpen Source Lab ManualRamesh KumarNo ratings yet
- EyOS Installation Manual WindowsDocument36 pagesEyOS Installation Manual WindowsnebondzaNo ratings yet
- Absolute Manage User GuideDocument653 pagesAbsolute Manage User GuidecmarzecJPSNo ratings yet
- Machine Learning Yearning v0-5Document27 pagesMachine Learning Yearning v0-5KarthikNo ratings yet
- Arch TemplateDocument38 pagesArch Templateruhul_ronyNo ratings yet
- Design, Development and Performance Evaluation of Multiprocessor Systems On FpgaDocument161 pagesDesign, Development and Performance Evaluation of Multiprocessor Systems On FpgagurumbhatNo ratings yet
- 10 Principles of A Good Code ReviewDocument7 pages10 Principles of A Good Code ReviewMohamed RahalNo ratings yet
- Building Microservice With Go KitDocument10 pagesBuilding Microservice With Go KitJerry James AkohNo ratings yet
- WP Togaf Bian Rev4 enDocument41 pagesWP Togaf Bian Rev4 enHasti YektaNo ratings yet
- How To Add AdSense Ads Below Post Title in BloggerDocument2 pagesHow To Add AdSense Ads Below Post Title in BloggerRabail KhalidNo ratings yet
- Deloitte Take Home Challenge - V2Document83 pagesDeloitte Take Home Challenge - V2Likhith DNo ratings yet
- DNC Mag Fourthanniv Single PDFDocument85 pagesDNC Mag Fourthanniv Single PDFVimal ThakkarNo ratings yet
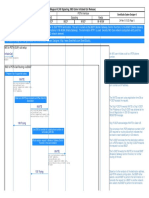
- HLD Document Outlines System ArchitectureDocument5 pagesHLD Document Outlines System ArchitectureRaghavendra MuniramaiahNo ratings yet
- Optimizing Dialog LLM Chatbot Retrieval Augmented Generation With A Swarm Architecture - by Anthony Alcaraz - Aug, 2023 - MediumDocument16 pagesOptimizing Dialog LLM Chatbot Retrieval Augmented Generation With A Swarm Architecture - by Anthony Alcaraz - Aug, 2023 - MediumSergio MartínezNo ratings yet
- Intune Device Enrollment - Android Admin GuideDocument6 pagesIntune Device Enrollment - Android Admin GuideSebastian BravoNo ratings yet
- Caching Architecture Guide For .NET ApplicationsDocument150 pagesCaching Architecture Guide For .NET ApplicationsMarius StoicaNo ratings yet
- Outline: How To Install Development SetupDocument8 pagesOutline: How To Install Development SetupOcean ApplicationsNo ratings yet
- Setting up a Private Cloud with OpenstackDocument20 pagesSetting up a Private Cloud with OpenstackBnaren NarenNo ratings yet
- Deep Learning With Databricks: Srijith Rajamohan, Ph.D. John O'DwyerDocument38 pagesDeep Learning With Databricks: Srijith Rajamohan, Ph.D. John O'DwyerNiharikaNicNo ratings yet
- Code Review Checklist C# DevelopersDocument5 pagesCode Review Checklist C# DevelopersSunil NaikNo ratings yet
- 1 Openstack Neutron Distributed Virtual RouterDocument11 pages1 Openstack Neutron Distributed Virtual RouterShabeer UppotungalNo ratings yet
- Microsoft Dynamics CRM IG OperatingDocument59 pagesMicrosoft Dynamics CRM IG Operatingpeter_rele8401No ratings yet
- A Guide To html5 and css3Document73 pagesA Guide To html5 and css3api-309040523100% (1)
- Chapter 11.2 Starting With Service Portal PDFDocument35 pagesChapter 11.2 Starting With Service Portal PDFKittu KittuNo ratings yet
- Teamviewer ProjectDocument22 pagesTeamviewer ProjectEr Rashid KhanNo ratings yet
- Uncertainty in ModelingDocument25 pagesUncertainty in ModelingAnil YogiNo ratings yet
- ABookofNewEnglandLegendsandFolkLore 10017537 PDFDocument501 pagesABookofNewEnglandLegendsandFolkLore 10017537 PDFaureliabadea100% (1)
- Git Tutorial PDFDocument8 pagesGit Tutorial PDFMauricio Alejandro Arenas ArriagadaNo ratings yet
- Creating a Java Calculator with NetBeans IDEDocument42 pagesCreating a Java Calculator with NetBeans IDEDavid Andrew Divina FariñasNo ratings yet
- SDLC Security Penetration Testing MethodologiesDocument36 pagesSDLC Security Penetration Testing Methodologieszaoui danteNo ratings yet
- Step by Step Azure Site To Site VPN With SonicWall Hardware FirewallDocument25 pagesStep by Step Azure Site To Site VPN With SonicWall Hardware FirewallabcNo ratings yet
- 2021-02-04 DAIM Company PresentationDocument17 pages2021-02-04 DAIM Company PresentationLukasz FrydlewiczNo ratings yet
- Indira Gandhi National Open UniversityDocument37 pagesIndira Gandhi National Open UniversityUninor MyNo ratings yet
- Top Software Development Trends Expected To Dominate in 2022 - by Ankita Kapoor - Enlear AcademyDocument31 pagesTop Software Development Trends Expected To Dominate in 2022 - by Ankita Kapoor - Enlear Academyadede2009No ratings yet
- CAClarityPPM TechRefGuide ENUDocument67 pagesCAClarityPPM TechRefGuide ENUPrashank SinghNo ratings yet
- Software Requirements Specification For Online ShoppingDocument12 pagesSoftware Requirements Specification For Online ShoppingabdulsattarNo ratings yet
- Building Microservice SolutionsDocument35 pagesBuilding Microservice SolutionsWashynAceroMNo ratings yet
- Power Designer Tips TricksDocument7 pagesPower Designer Tips TricksFreddy Castro Ponce0% (1)
- MD-101.examsforall.premium.exam.208qDocument301 pagesMD-101.examsforall.premium.exam.208qEvandro MendonçaNo ratings yet
- BizTalk Naming ConventionsDocument7 pagesBizTalk Naming Conventionsreddysham4uNo ratings yet
- KofaxDocument18 pagesKofaxheryezNo ratings yet
- CMDBuild WorkflowManual ENG V240Document70 pagesCMDBuild WorkflowManual ENG V240Manuel VegaNo ratings yet
- Manual Smart MeyeDocument16 pagesManual Smart MeyeYouness Aad100% (1)
- 15364248-How To Integrate Unity Connection With Microsoft Office 365Document2 pages15364248-How To Integrate Unity Connection With Microsoft Office 365Muhammad PKNo ratings yet
- Security Development Lifecycle A Complete Guide - 2020 EditionFrom EverandSecurity Development Lifecycle A Complete Guide - 2020 EditionNo ratings yet
- Microsoft Security Development Lifecycle A Complete Guide - 2021 EditionFrom EverandMicrosoft Security Development Lifecycle A Complete Guide - 2021 EditionNo ratings yet
- Cloud Computing Infrastructure As A Service (IaaS)Document5 pagesCloud Computing Infrastructure As A Service (IaaS)Kavya MamillaNo ratings yet
- Dump-Networking-2022 1008 142341 StopDocument971 pagesDump-Networking-2022 1008 142341 StopobedNo ratings yet
- Cloud RAN and ECPRI Fronthaul in 5G NetworksDocument5 pagesCloud RAN and ECPRI Fronthaul in 5G NetworksTalent & Tech Global InfotechNo ratings yet
- Types of Mass CommunicationDocument8 pagesTypes of Mass CommunicationNaimat UllahNo ratings yet
- Proposed Continuity Plan of Juan S. Jarencio Memorial School SY 2020-2021Document22 pagesProposed Continuity Plan of Juan S. Jarencio Memorial School SY 2020-2021LILIBETH DILENo ratings yet
- MSD94BDX2: Ver Change List DateDocument17 pagesMSD94BDX2: Ver Change List DateRicardo VieiraNo ratings yet
- ITP211 MULTIMEDIA - OBE SyllabusDocument7 pagesITP211 MULTIMEDIA - OBE SyllabusJoseph MazoNo ratings yet
- Chapter - 9 - V8.0-Wireless and Mobile NetworksDocument30 pagesChapter - 9 - V8.0-Wireless and Mobile NetworksNasir AliNo ratings yet
- Daftar Harga Atk DLL Update BondowosoDocument14 pagesDaftar Harga Atk DLL Update BondowosoFoppsi TamananNo ratings yet
- Manual KONICA MINOLTA 4020vserv. Manual - MenuDocument44 pagesManual KONICA MINOLTA 4020vserv. Manual - MenuGerardo Acosta BravoNo ratings yet
- Mod 03Document56 pagesMod 03michael.santiago15No ratings yet
- Chapter 6 Voice Over IPDocument26 pagesChapter 6 Voice Over IPShame BopeNo ratings yet
- Xoomstv User GuideDocument3 pagesXoomstv User GuideGabriel Morales de PoolNo ratings yet
- Lecture by Saad S. Naif: University of DuhokDocument9 pagesLecture by Saad S. Naif: University of DuhokaafrasyawNo ratings yet
- ArticleDocument769 pagesArticletesnimarapmoonNo ratings yet
- Isp Training With Mikrotik TrainingDocument6 pagesIsp Training With Mikrotik TrainingIfeoma ArinzechukwuNo ratings yet
- Chapter 2 Computer ArchitectureDocument25 pagesChapter 2 Computer ArchitectureAron DionisiusNo ratings yet
- Maxpro Ce SDocument5 pagesMaxpro Ce Snambi.kumresan1No ratings yet
- Itc AssigDocument5 pagesItc AssigHuzaif samiNo ratings yet
- Ims To PSTN CallflowDocument9 pagesIms To PSTN CallflowHenry AlbaNo ratings yet
- Prolin Terminal Manager (2.0.2)Document57 pagesProlin Terminal Manager (2.0.2)acoliveira OliveiraNo ratings yet
- Jncis-Ent RaspunsuriDocument14 pagesJncis-Ent RaspunsuriBogdan BarbuNo ratings yet
- SF DumpDocument12 pagesSF DumpDODAN DANIEL MARTINNo ratings yet
- Lesson 14: Lesson 15Document8 pagesLesson 14: Lesson 15Wendelyn CuyosNo ratings yet
- HDD Compatibility List For DAHUA Products: Class Brand Series Model Number Capacity Type StateDocument3 pagesHDD Compatibility List For DAHUA Products: Class Brand Series Model Number Capacity Type StateAhahaNo ratings yet
- IP - 20C - Preliminary - Datasheet - ETSI - Rev - A 08Document47 pagesIP - 20C - Preliminary - Datasheet - ETSI - Rev - A 08imeldoNo ratings yet
- Aruba Lab 3Document4 pagesAruba Lab 3malek100% (1)
- Guardianeye Monitoring System: Instruction ManualDocument37 pagesGuardianeye Monitoring System: Instruction ManualRachel MalinsNo ratings yet
- Why Use Class 2 USB ModeDocument3 pagesWhy Use Class 2 USB ModeMark SpliffNo ratings yet
- Roku Quick Start GuideDocument6 pagesRoku Quick Start GuideDodong Danilo Montero MaganaNo ratings yet