80% found this document useful (10 votes)
15K views14 pagesSampling Distribution in Inferential Stats
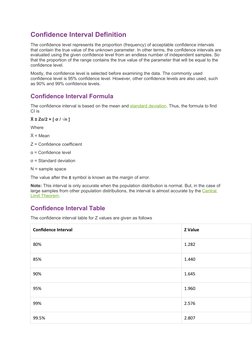
The document discusses sampling distributions and their importance in inferential statistics. It defines a sampling distribution as a theoretical distribution that describes the possible outcomes of a sample statistic calculated from random samples of a population. The most common sample statistic is the sample mean. The sampling distribution of the mean describes how sample means from different samples are distributed around the true population mean. The central limit theorem states that as sample size increases, the sampling distribution of the mean becomes approximately normally distributed, regardless of the shape of the population distribution. The standard error of the mean describes how far sample means typically are from the population mean. Sampling distributions are important for point and interval estimation of population parameters from sample data.
Uploaded by
Nandhini P Asst.Prof/MBACopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
80% found this document useful (10 votes)
15K views14 pagesSampling Distribution in Inferential Stats
The document discusses sampling distributions and their importance in inferential statistics. It defines a sampling distribution as a theoretical distribution that describes the possible outcomes of a sample statistic calculated from random samples of a population. The most common sample statistic is the sample mean. The sampling distribution of the mean describes how sample means from different samples are distributed around the true population mean. The central limit theorem states that as sample size increases, the sampling distribution of the mean becomes approximately normally distributed, regardless of the shape of the population distribution. The standard error of the mean describes how far sample means typically are from the population mean. Sampling distributions are important for point and interval estimation of population parameters from sample data.
Uploaded by
Nandhini P Asst.Prof/MBACopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd