You might also like
- 1967 2013 PDFDocument70 pages1967 2013 PDFAlberto Dorado Martín100% (1)
- English 3 PDFDocument177 pagesEnglish 3 PDFÇèrela ĆlavəcillasNo ratings yet
- The 10 Most Inspiring Quotes of Charles F HaanelDocument21 pagesThe 10 Most Inspiring Quotes of Charles F HaanelKallisti Publishing Inc - "The Books You Need to Succeed"100% (2)
- Visual GPTDocument16 pagesVisual GPTPengZai ZhongNo ratings yet
- Sign Language TranslatorDocument4 pagesSign Language TranslatorInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Manual de Partes 501-601Document27 pagesManual de Partes 501-601camilo bautista100% (2)
- Object Oriented DevelopmentDocument18 pagesObject Oriented Developmentsurenyoga100% (1)
- Deepseek-Vl: Towards Real-World Vision-Language UnderstandingDocument33 pagesDeepseek-Vl: Towards Real-World Vision-Language UnderstandingGobiNo ratings yet
- A JAX Library For Computer Vision Research and Beyond: CenicDocument4 pagesA JAX Library For Computer Vision Research and Beyond: Cenicmanohar malliisettyNo ratings yet
- Deep Learning For Sign Language Recognition Current Techniques Benchmarks and Open IssuesDocument35 pagesDeep Learning For Sign Language Recognition Current Techniques Benchmarks and Open IssuesKaran RajNo ratings yet
- Computers & GraphicsDocument18 pagesComputers & Graphicsmr nNo ratings yet
- A Comprehensive Survey On Segment Anything Model For Vision and BeyondDocument28 pagesA Comprehensive Survey On Segment Anything Model For Vision and Beyond1286313960No ratings yet
- Deep Visual-Semantic Alignments For Generating Image DescriptionsDocument14 pagesDeep Visual-Semantic Alignments For Generating Image DescriptionsRAGURAM SHANMUGAMNo ratings yet
- 2017 Deep CNNDocument6 pages2017 Deep CNNSunil ChaluvaiahNo ratings yet
- Sasha Rush - Interactive and Visual Prompt EngineeringDocument11 pagesSasha Rush - Interactive and Visual Prompt EngineeringGugo ManNo ratings yet
- SOLOIST Building Task Bots at ScaleDocument18 pagesSOLOIST Building Task Bots at ScaleDanqing LiuNo ratings yet
- Research Paper Summary: Ans:to The Q:no:1Document7 pagesResearch Paper Summary: Ans:to The Q:no:1Al Adnan MehediNo ratings yet
- 01 IntroDocument31 pages01 IntrodfdffNo ratings yet
- The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of The Open WorldDocument28 pagesThe All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of The Open WorldbibekNo ratings yet
- Designing Language Technology Applications: A Wizard of Oz Driven Prototyping FrameworkDocument4 pagesDesigning Language Technology Applications: A Wizard of Oz Driven Prototyping FrameworkyihoNo ratings yet
- PW - 4 - Litt. SurveyDocument6 pagesPW - 4 - Litt. SurveyTARA TARANNUMNo ratings yet
- Semicon Times: Front-End Design - Knowledge and SkillsDocument8 pagesSemicon Times: Front-End Design - Knowledge and SkillsDevender KhariNo ratings yet
- YOLO-WorldDocument15 pagesYOLO-WorldClark RenNo ratings yet
- A 1000-Word Vocabulary, Speaker-Independent, Continuous Live-Mode Speech Recognizer Implemented in A Single FPGADocument9 pagesA 1000-Word Vocabulary, Speaker-Independent, Continuous Live-Mode Speech Recognizer Implemented in A Single FPGAGanzorig ChakiNo ratings yet
- Python: A Programming Language For So Ware Integration and DevelopmentDocument8 pagesPython: A Programming Language For So Ware Integration and Developmentpatel sandipNo ratings yet
- Chapter 1 - Leadingedge-Software-DevelopmentDocument22 pagesChapter 1 - Leadingedge-Software-DevelopmentYoni YoniNo ratings yet
- Aangan by Khadija Mastoor PDFDocument29 pagesAangan by Khadija Mastoor PDFAnam QureshiNo ratings yet
- Reconocimiento de VozDocument5 pagesReconocimiento de VozosmerNo ratings yet
- 7 - 23 - Deep Image Captioning A Review of Methods, Trends and Future ChallengesDocument21 pages7 - 23 - Deep Image Captioning A Review of Methods, Trends and Future ChallengesPhạm Thanh TrườngNo ratings yet
- ScreenAIDocument15 pagesScreenAImyselfashmeetaNo ratings yet
- Object-Oriented Programming Paradigm For Software DevelopmentDocument4 pagesObject-Oriented Programming Paradigm For Software Developmentsasank sekhar sahuNo ratings yet
- Communication ArchitecturesDocument23 pagesCommunication ArchitecturesVariable 14No ratings yet
- Pytorch-Kaldi 2018Document5 pagesPytorch-Kaldi 2018hhakim32No ratings yet
- x10 BookDocument99 pagesx10 BookDaniel Costa E SaNo ratings yet
- Ai and AppplicationsDocument3 pagesAi and AppplicationsRezkie RezkieNo ratings yet
- Deep Audio-Visual Speech RecognitionDocument13 pagesDeep Audio-Visual Speech RecognitionholissonNo ratings yet
- YOLO-World: Real-Time Open-Vocabulary Object DetectionDocument15 pagesYOLO-World: Real-Time Open-Vocabulary Object Detection2136 SANTHOSHINo ratings yet
- Knowledge Engineering Using Large Language Models - TGDK.1.1.3Document19 pagesKnowledge Engineering Using Large Language Models - TGDK.1.1.3Pablo Ernesto Vigneaux WiltonNo ratings yet
- An Introduction To Deep Learning For The Physical LayerDocument13 pagesAn Introduction To Deep Learning For The Physical Layerzhouxinzhao0211No ratings yet
- Flocking: A Framework For Declarative Music-Making On The WebDocument8 pagesFlocking: A Framework For Declarative Music-Making On The WebTomy NicholsonNo ratings yet
- Object Oriented ParalellDocument26 pagesObject Oriented ParalellRubén VLNo ratings yet
- The Rascal Meta-Programming Language - A Lab For SDocument7 pagesThe Rascal Meta-Programming Language - A Lab For S3dgiordanoNo ratings yet
- Journal of Advanced Research: Andrei-Alexandru Tulbure, Adrian-Alexandru Tulbure, Eva-Henrietta DulfDocument16 pagesJournal of Advanced Research: Andrei-Alexandru Tulbure, Adrian-Alexandru Tulbure, Eva-Henrietta DulfBudrescu GeorgeNo ratings yet
- Codesmith Software Engineering Immersives SyllabusDocument8 pagesCodesmith Software Engineering Immersives SyllabusGeo DuncanNo ratings yet
- Evaluating Sequence-to-Sequence Models For Handwritten Text RecognitionDocument8 pagesEvaluating Sequence-to-Sequence Models For Handwritten Text Recognitionfetulhak abdurahmanNo ratings yet
- PGCON Paper FinalDocument4 pagesPGCON Paper FinalArbaaz ShaikhNo ratings yet
- MLSCA Zaigham MushtaqDocument30 pagesMLSCA Zaigham MushtaqAhsan ChNo ratings yet
- Pytorchvideo: A Deep Learning Library For Video UnderstandingDocument4 pagesPytorchvideo: A Deep Learning Library For Video UnderstandingqwertyNo ratings yet
- Interviews and Observation of Blind Software Developers at Work To Understand Code Navigation ChallengesDocument10 pagesInterviews and Observation of Blind Software Developers at Work To Understand Code Navigation ChallengesAnonymous 75M6uB3OwNo ratings yet
- Object-Oriented Programming in AI: Guest Editors'Document2 pagesObject-Oriented Programming in AI: Guest Editors'Hernan Rivera CabezaNo ratings yet
- Alexandru Panichella Gall Code Analysis Saner17Document12 pagesAlexandru Panichella Gall Code Analysis Saner17Sebastiano PanichellaNo ratings yet
- Large DivisionsDocument7 pagesLarge DivisionsshafiahmedbdNo ratings yet
- Compiling ONNX Neural Network Models Using MlirDocument8 pagesCompiling ONNX Neural Network Models Using MlirGuilhermeNo ratings yet
- Callum Dempsey Leach's CV highlights skills and experienceDocument2 pagesCallum Dempsey Leach's CV highlights skills and experienceM KNo ratings yet
- Accelerating Innovation With Software Abstractions For Scalable Computational GeophysicsDocument10 pagesAccelerating Innovation With Software Abstractions For Scalable Computational GeophysicsLahul LahiriNo ratings yet
- An Object-Oriented and Executable Sysml Framework For Rapid Model DevelopmentDocument10 pagesAn Object-Oriented and Executable Sysml Framework For Rapid Model Developmentrahul.srivastavaNo ratings yet
- 1 s2.0 S0167865523001228 MainDocument8 pages1 s2.0 S0167865523001228 MainSouhaila DjaffalNo ratings yet
- Deep Learning-Based Communication Over The AirDocument11 pagesDeep Learning-Based Communication Over The AirBoy azNo ratings yet
- Zhao Et Al, 2017, InferSpark - Statistical Inference at ScaleDocument13 pagesZhao Et Al, 2017, InferSpark - Statistical Inference at ScaleHeru PraptonoNo ratings yet
- Comprehensive Review On CNN Encoder Decoder PDFDocument23 pagesComprehensive Review On CNN Encoder Decoder PDFkamrulhasanbdyahoo.comNo ratings yet
- Research StatementDocument4 pagesResearch StatementChristopher Collins100% (3)
- What About The Usability in Low-Code Platforms - A SLRDocument16 pagesWhat About The Usability in Low-Code Platforms - A SLRJason K. RubinNo ratings yet
- Burnett - Visual OOPDocument14 pagesBurnett - Visual OOPMuhammad RofiNo ratings yet
- 1 Multiple Choice Questions (MCQ)Document11 pages1 Multiple Choice Questions (MCQ)peppyguypgNo ratings yet
- Places NIPS14 PDFDocument9 pagesPlaces NIPS14 PDFPiyush RaiNo ratings yet
- Pondernet: Learning To Ponder: 8Th Icml Workshop On Automated Machine Learning (2021)Document16 pagesPondernet: Learning To Ponder: 8Th Icml Workshop On Automated Machine Learning (2021)peppyguypgNo ratings yet
- Pondernet: Learning To Ponder: 8Th Icml Workshop On Automated Machine Learning (2021)Document16 pagesPondernet: Learning To Ponder: 8Th Icml Workshop On Automated Machine Learning (2021)peppyguypgNo ratings yet
- Pondernet: Learning To Ponder: 8Th Icml Workshop On Automated Machine Learning (2021)Document16 pagesPondernet: Learning To Ponder: 8Th Icml Workshop On Automated Machine Learning (2021)peppyguypgNo ratings yet
- Swinir: Image Restoration Using Swin TransformerDocument12 pagesSwinir: Image Restoration Using Swin TransformerpeppyguypgNo ratings yet
- Install Notes (Please Read) TumDocument1 pageInstall Notes (Please Read) TumKumarNadarNo ratings yet
- Panasonic SA-HT878Document82 pagesPanasonic SA-HT878immortalwombatNo ratings yet
- Raoult's law and colligative propertiesDocument27 pagesRaoult's law and colligative propertiesGøbindNo ratings yet
- Day3 PESTLE AnalysisDocument13 pagesDay3 PESTLE AnalysisAmit AgrawalNo ratings yet
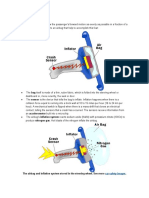
- Airbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreDocument5 pagesAirbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreShivankur HingeNo ratings yet
- Nej Mo A 1311738Document7 pagesNej Mo A 1311738cindy315No ratings yet
- Bioprocess Engineering QuestionsDocument13 pagesBioprocess Engineering QuestionsPalanisamy Selvamani100% (1)
- Adafruit Color SensorDocument25 pagesAdafruit Color Sensorarijit_ghosh_18No ratings yet
- Ic T7HDocument36 pagesIc T7HCarlos GaiarinNo ratings yet
- India: Soil Types, Problems & Conservation: Dr. SupriyaDocument25 pagesIndia: Soil Types, Problems & Conservation: Dr. SupriyaManas KaiNo ratings yet
- Gorsey Bank Primary School: Mission Statement Mission StatementDocument17 pagesGorsey Bank Primary School: Mission Statement Mission StatementCreative BlogsNo ratings yet
- Floor CraneDocument6 pagesFloor CranejillianixNo ratings yet
- Year 5 Reasoning Test Set 3 Paper A: Q Marks Answer Notes 1a 1b 7 6 4Document2 pagesYear 5 Reasoning Test Set 3 Paper A: Q Marks Answer Notes 1a 1b 7 6 4Amina Zeghar BNo ratings yet
- Viennot - 1979 - Spontaneous Reasoning in Elementary DynamicsDocument18 pagesViennot - 1979 - Spontaneous Reasoning in Elementary Dynamicsjumonteiro2000No ratings yet
- Confidentiality Agreement With Undertaking and WaiverDocument1 pageConfidentiality Agreement With Undertaking and WaiverreddNo ratings yet
- TC-21FJ30LA: Service ManualDocument33 pagesTC-21FJ30LA: Service ManualRajo Peto alamNo ratings yet
- Rectangle StabbingDocument49 pagesRectangle StabbingApurba DasNo ratings yet
- Course 4Document3 pagesCourse 4Ibrahim SalahudinNo ratings yet
- Business English 2, (ML, PI, U6, C3)Document2 pagesBusiness English 2, (ML, PI, U6, C3)Ben RhysNo ratings yet
- CFPA E Guideline No 2 2013 FDocument39 pagesCFPA E Guideline No 2 2013 Fmexo62No ratings yet
- Audiology DissertationDocument4 pagesAudiology DissertationPaperWritingHelpOnlineUK100% (1)
- Chapter 08-Borrowing Costs-Tutorial AnswersDocument4 pagesChapter 08-Borrowing Costs-Tutorial AnswersMayomi JayasooriyaNo ratings yet
- The History of Coins and Banknotes in Mexico: September 2012Document35 pagesThe History of Coins and Banknotes in Mexico: September 2012Mladen VidovicNo ratings yet
- SOYER Bend Testing Device BP-1Document2 pagesSOYER Bend Testing Device BP-1abdulla_alazzawiNo ratings yet
- Đáp Án K Năng NóiDocument6 pagesĐáp Án K Năng NóiSói ConNo ratings yet
- CotomDocument8 pagesCotommuangawaNo ratings yet
- Portable USB ChargerDocument13 pagesPortable USB ChargerParmar KundanNo ratings yet