You might also like
- Software Testing Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesFrom EverandSoftware Testing Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNo ratings yet
- Operating SystemDocument21 pagesOperating SystemUsman MalikNo ratings yet
- Application of Deep Learning in Software Testing and Quality AssuranceDocument13 pagesApplication of Deep Learning in Software Testing and Quality AssuranceLeah RachaelNo ratings yet
- Predicting Root Cause Analysis (RCA) Bucket ForDocument4 pagesPredicting Root Cause Analysis (RCA) Bucket ForTameta DadaNo ratings yet
- 62 1520327334 - 06-03-2018 PDFDocument7 pages62 1520327334 - 06-03-2018 PDFRahul SharmaNo ratings yet
- Software Metrics For Fault Prediction Using Machine Learning ApproachesDocument5 pagesSoftware Metrics For Fault Prediction Using Machine Learning ApproachesJerryMathewNo ratings yet
- Information Technology ManagementDocument25 pagesInformation Technology ManagementOUMA ONYANGONo ratings yet
- StaffDocument50 pagesStaffvarunNo ratings yet
- Ensemble Machine Learning Model For Software Defect PredictionDocument11 pagesEnsemble Machine Learning Model For Software Defect PredictionDada Emmanuel GbengaNo ratings yet
- Improving Software Development Process Through Data Mining Techniques of Unsupervised Algorithms IJERTV10IS110002Document4 pagesImproving Software Development Process Through Data Mining Techniques of Unsupervised Algorithms IJERTV10IS110002Karan SadhwaniNo ratings yet
- Comprehensive Study On Machine LearningDocument10 pagesComprehensive Study On Machine LearningTahiru Abdul-MoominNo ratings yet
- Investigating The Role of Code Smells in Preventive MaintenanceDocument23 pagesInvestigating The Role of Code Smells in Preventive MaintenanceJunaidNo ratings yet
- S E-1Document46 pagesS E-1Akash SatputeNo ratings yet
- BTech CSE-software EngineeringDocument83 pagesBTech CSE-software EngineeringFaraz khanNo ratings yet
- Bug Tracking System: Nikunj AggarwalDocument104 pagesBug Tracking System: Nikunj AggarwalAmit KapoorNo ratings yet
- Employee Management System ReportDocument79 pagesEmployee Management System ReportbelayNo ratings yet
- SE Module 1Document21 pagesSE Module 1rohithlokesh2912No ratings yet
- Theis ProposalDocument6 pagesTheis ProposaliramNo ratings yet
- Unit I & IIDocument21 pagesUnit I & IIvishalmaharshi779No ratings yet
- Malware IdentificationDocument28 pagesMalware IdentificationEminent ProjectsNo ratings yet
- Bug Tracking System ThesisDocument7 pagesBug Tracking System Thesisaprildavislittlerock100% (2)
- Introduction To Software EngineeringDocument48 pagesIntroduction To Software EngineeringSonal MaratheNo ratings yet
- Efficient Software Cost Estimation Using Machine Learning TechniquesDocument20 pagesEfficient Software Cost Estimation Using Machine Learning Techniquessheela uppalagallaNo ratings yet
- COS 202 NoteDocument13 pagesCOS 202 NoteDaniel IhejirikaNo ratings yet
- Nmaist Project PresentationDocument27 pagesNmaist Project PresentationDavis DavidNo ratings yet
- PaigeDocument17 pagesPaigeSHUBHAM POLNo ratings yet
- Software Processes in Software Engineering - GeeksforGeeksDocument13 pagesSoftware Processes in Software Engineering - GeeksforGeeksGanesh PanigrahiNo ratings yet
- A Review of Software Fault Detection and Correction Process, Models and TechniquesDocument8 pagesA Review of Software Fault Detection and Correction Process, Models and TechniquesDr Muhamma Imran BabarNo ratings yet
- Software ProjectDocument18 pagesSoftware ProjectRushikesh KanseNo ratings yet
- Software Engineering NotesDocument61 pagesSoftware Engineering NotesAnonymous L7XrxpeI1z100% (3)
- Chapter 1Document52 pagesChapter 1Kajal SinghalNo ratings yet
- A Framework For Software Defect Prediction Using Neural NetworksDocument11 pagesA Framework For Software Defect Prediction Using Neural NetworksarmanNo ratings yet
- Machine Learning Based Approach For Predicting Fault in Software Engineering by GMFPA: A SurveyDocument6 pagesMachine Learning Based Approach For Predicting Fault in Software Engineering by GMFPA: A SurveyijcnesNo ratings yet
- MAD Micro ProjectDocument21 pagesMAD Micro ProjectRed Light HackersNo ratings yet
- Preliminary Investigation: 1 School Management SystemDocument69 pagesPreliminary Investigation: 1 School Management SystemNilam BiradarNo ratings yet
- SE - Unit - 1 NotesDocument20 pagesSE - Unit - 1 NotesYuvraj AgarkarNo ratings yet
- Employee Management System ReportDocument77 pagesEmployee Management System ReportAjay RohillaNo ratings yet
- Software Engineering 1Document35 pagesSoftware Engineering 1KartikNo ratings yet
- Deep Learning Software Defect Prediction Methods FDocument11 pagesDeep Learning Software Defect Prediction Methods Fsinduja.cseNo ratings yet
- Unit 1Document18 pagesUnit 1milf hunterNo ratings yet
- SEN Notes - Unit 1Document28 pagesSEN Notes - Unit 1Om DevharkarNo ratings yet
- Management Information Systems - Group 4Document12 pagesManagement Information Systems - Group 4Sasha FoxNo ratings yet
- Fault LocalizationDocument4 pagesFault LocalizationiramNo ratings yet
- Software Engeenering Unit-I NotesDocument23 pagesSoftware Engeenering Unit-I Notesyashbhatnagar02No ratings yet
- Bug Tracking SystemDocument28 pagesBug Tracking SystemKaataRanjithkumarNo ratings yet
- 2 Software Engineering ProcessDocument14 pages2 Software Engineering ProcessHemant GoyalNo ratings yet
- SDP Edited1.editedDocument8 pagesSDP Edited1.editedakhtar abbasNo ratings yet
- Software EngineeringDocument7 pagesSoftware EngineeringNaveenmanuelcabralNo ratings yet
- Diploma SidDocument36 pagesDiploma SidKailash GoradeNo ratings yet
- WelcomeDocument23 pagesWelcomeabiramanNo ratings yet
- Chapter 1 Introduction To Development Approach SSAD and OOADDocument71 pagesChapter 1 Introduction To Development Approach SSAD and OOADPrashant Shitole100% (1)
- Question Paper1Document10 pagesQuestion Paper1Ran StarkNo ratings yet
- Software Engineering Is The Process of Designing, Developing, Testing, andDocument5 pagesSoftware Engineering Is The Process of Designing, Developing, Testing, andbilalshahzad238No ratings yet
- Jay Prakash, DBMSDocument10 pagesJay Prakash, DBMSAnirudh Adithya B SNo ratings yet
- LEC 3 Information System PlanningDocument6 pagesLEC 3 Information System PlanningJEMIMA MILES CASIBUANo ratings yet
- Software Cost Estimation PDFDocument6 pagesSoftware Cost Estimation PDFsheela uppalagallaNo ratings yet
- CCPeDocument17 pagesCCPeCO - 46 - Vaishnavi SableNo ratings yet
- Software EngineeringDocument47 pagesSoftware Engineeringquotelyric188No ratings yet
- Page - IDocument38 pagesPage - ISal 's ManNo ratings yet
- Quant, FM, and Data Science Interview Compilation: Aaron CaoDocument14 pagesQuant, FM, and Data Science Interview Compilation: Aaron CaoNameet JainNo ratings yet
- Chapter - Binary Index TreesDocument24 pagesChapter - Binary Index TreesNameet JainNo ratings yet
- Nameet Kumar Jain: Text Mining and AnalyticsDocument2 pagesNameet Kumar Jain: Text Mining and AnalyticsNameet JainNo ratings yet
- 2 TopFacebookQuestionsDocument2 pages2 TopFacebookQuestionsDIVYANSHUNo ratings yet
- 9 AssignmentDynamicProgrammingDocument10 pages9 AssignmentDynamicProgrammingDIVYANSHUNo ratings yet
- Get Familiar With Python Get Familiar With Python 2K18/CO/221 2K18/CO/221Document2 pagesGet Familiar With Python Get Familiar With Python 2K18/CO/221 2K18/CO/221Nameet JainNo ratings yet
- Nameet Kumar Jain: Competitive Programmer's Core SkillsDocument2 pagesNameet Kumar Jain: Competitive Programmer's Core SkillsNameet JainNo ratings yet
- Linux Shell Scripting CookbookDocument125 pagesLinux Shell Scripting CookbookkajaljainNo ratings yet
- Online Application ProcessDocument2 pagesOnline Application ProcessNameet JainNo ratings yet
- Bank Queue Management System: Problem StatementDocument58 pagesBank Queue Management System: Problem StatementNameet JainNo ratings yet
- Academic Qualifications: Sahilnegi104104 Sahil Negi Sahil NegiDocument1 pageAcademic Qualifications: Sahilnegi104104 Sahil Negi Sahil NegiNameet JainNo ratings yet
- LALR Parser For A Grammar: Compiler DesignDocument8 pagesLALR Parser For A Grammar: Compiler DesignNameet JainNo ratings yet
- Nameet Kumar Jain: Education ProjectsDocument1 pageNameet Kumar Jain: Education ProjectsNameet JainNo ratings yet
- 5000 TOEFL Words PDFDocument36 pages5000 TOEFL Words PDFPrudhveeraj Chegu100% (2)
- New One PlacementsDocument8 pagesNew One PlacementsNameet JainNo ratings yet
- 5000 TOEFL Words PDFDocument36 pages5000 TOEFL Words PDFPrudhveeraj Chegu100% (2)
- Delhi Technological University Department of Computer ScienceDocument4 pagesDelhi Technological University Department of Computer ScienceNameet JainNo ratings yet
- October 2020 EditionDocument1 pageOctober 2020 EditionSahil BonganeNo ratings yet
- Operating SystemDocument54 pagesOperating Systemkartik anand100% (2)
- Online Examination System: OverviewDocument2 pagesOnline Examination System: OverviewNameet JainNo ratings yet
- HR Questions: About Situational QuestionsDocument3 pagesHR Questions: About Situational QuestionsNameet JainNo ratings yet
- 12.1 Next-Gen-Js-Summary PDFDocument8 pages12.1 Next-Gen-Js-Summary PDFBenefitsNo ratings yet
- Department of Training and Placement Delhi Technological University Standard Operating Procedure/Placement Policy/Rules (2020-2021)Document4 pagesDepartment of Training and Placement Delhi Technological University Standard Operating Procedure/Placement Policy/Rules (2020-2021)Nitin RajputNo ratings yet
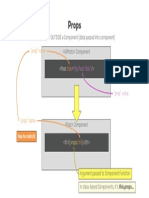
- Props Learning CardDocument1 pageProps Learning CardNameet JainNo ratings yet
- Lecture 1: Catalan Numbers and Recurrence RelationsDocument6 pagesLecture 1: Catalan Numbers and Recurrence RelationsNameet JainNo ratings yet
- LP23 - HashingDocument33 pagesLP23 - HashingNameet JainNo ratings yet
- Greedy AlgorithmDocument18 pagesGreedy AlgorithmNick TunacNo ratings yet
- Because Even Dijkstra Isn't That Fast AlwaysDocument6 pagesBecause Even Dijkstra Isn't That Fast AlwaysNameet JainNo ratings yet
- Line Follower Robot PDFDocument5 pagesLine Follower Robot PDFNameet JainNo ratings yet
- Daily Lesson Log: The Learner... The Learner... The Learner... The Learner..Document2 pagesDaily Lesson Log: The Learner... The Learner... The Learner... The Learner..Christian Joy Magno Olarte100% (1)
- Eng4u The Hunger Games Unit PlanDocument13 pagesEng4u The Hunger Games Unit PlanDIAYANARA ROSE CACHONo ratings yet
- A Companion To The Study of HistoryDocument369 pagesA Companion To The Study of HistoryNawaz205050% (2)
- PPM - HCM Integration With Business PartnersDocument8 pagesPPM - HCM Integration With Business PartnersJosé RiveraNo ratings yet
- Reported Speech TheoryDocument3 pagesReported Speech TheoryLaura GompaNo ratings yet
- NEXGEN-4000 PLC: 4 Channel, 16 Bit Analog Output Module (Ordering Code - 4334)Document2 pagesNEXGEN-4000 PLC: 4 Channel, 16 Bit Analog Output Module (Ordering Code - 4334)arunkumarNo ratings yet
- Mini ProjectDocument12 pagesMini ProjectTamizh KdzNo ratings yet
- Trends in English Language Teaching TodayDocument3 pagesTrends in English Language Teaching TodaySusarla SuryaNo ratings yet
- Mar Apr 2019Document32 pagesMar Apr 2019KalyanNo ratings yet
- The Effective Communication in Accountancy Business and ManagementDocument4 pagesThe Effective Communication in Accountancy Business and Managementlarry delos reyeNo ratings yet
- D2 - Launching Feedback-Driven Fuzzing On TrustZone TEE - Andrey AkimovDocument61 pagesD2 - Launching Feedback-Driven Fuzzing On TrustZone TEE - Andrey AkimovKnife FishNo ratings yet
- The Culture of ChinaDocument302 pagesThe Culture of ChinaDanielaGothamNo ratings yet
- R 2008 M.E. Embedded System Tech SyllabusDocument26 pagesR 2008 M.E. Embedded System Tech Syllabuslee_ganeshNo ratings yet
- Peter M. Worsley: The End of Anthropology?Document15 pagesPeter M. Worsley: The End of Anthropology?majorbonobo50% (2)
- (Final) LHS ML Information System User's ManualDocument111 pages(Final) LHS ML Information System User's ManualHarold Paulo MejiaNo ratings yet
- Companion To Real Analysis - ErdmanDocument261 pagesCompanion To Real Analysis - ErdmankhoconnoNo ratings yet
- IMS-ZXUN CSCF-BC-EN-Installation and Commissioning-Data Configuration-1-PPT-201010-87Document87 pagesIMS-ZXUN CSCF-BC-EN-Installation and Commissioning-Data Configuration-1-PPT-201010-87BSSNo ratings yet
- SAP SRM TCodes PDFDocument6 pagesSAP SRM TCodes PDFtoabhishekpalNo ratings yet
- OutDocument452 pagesOutZaraScha HeMoi HemoyNo ratings yet
- Quiz # 1 CourseDocument1 pageQuiz # 1 Coursesmartbilal5338No ratings yet
- Separation of East PakistanDocument2 pagesSeparation of East PakistanNaveed ullahNo ratings yet
- Biblical Truth Transforming Culture Full PH DDissertation Glenn MartinDocument178 pagesBiblical Truth Transforming Culture Full PH DDissertation Glenn MartinGlenn MartinNo ratings yet
- BIT 2109 Integrative Programming and TechnologiesDocument4 pagesBIT 2109 Integrative Programming and TechnologiesHerwin CapiñanesNo ratings yet
- Batch ManagementDocument18 pagesBatch ManagementDarsh RathodNo ratings yet
- Guide Engineering Optimization L TEX Style Guide For Authors (Style 2 + Chicago Author-Date Reference Style)Document17 pagesGuide Engineering Optimization L TEX Style Guide For Authors (Style 2 + Chicago Author-Date Reference Style)skyline1122No ratings yet
- 9th Grade Math Vocabulary 1683069284Document2 pages9th Grade Math Vocabulary 1683069284BABY MARIE APASNo ratings yet
- Igor Stravinsky - Conversations With Igor StravinskyDocument190 pagesIgor Stravinsky - Conversations With Igor StravinskySlobodan Marjanovic100% (1)
- Subject: PRF192-PFC Workshop 05Document13 pagesSubject: PRF192-PFC Workshop 05Quoc Khanh NguyenNo ratings yet
- Introduction To Parallel ProgrammingDocument51 pagesIntroduction To Parallel Programminglmaraujo67No ratings yet
- Constructing More Extended Formal Proofs: - For A Given Argument As A Sequence of Statements, Each Is Either A Premise ofDocument10 pagesConstructing More Extended Formal Proofs: - For A Given Argument As A Sequence of Statements, Each Is Either A Premise ofariel lapiraNo ratings yet
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)From EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Rating: 4 out of 5 stars4/5 (1)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeFrom EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeRating: 4.5 out of 5 stars4.5/5 (69)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziFrom Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNo ratings yet
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet
- Four Battlegrounds: Power in the Age of Artificial IntelligenceFrom EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceRating: 5 out of 5 stars5/5 (5)
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsFrom EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsNo ratings yet
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureFrom EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNo ratings yet