You might also like
- Python HandsOn-Function&OOPsDocument16 pagesPython HandsOn-Function&OOPsHap Py77% (93)
- Statistiek 1920 HER ENG CovDocument8 pagesStatistiek 1920 HER ENG CovThe PrankfellasNo ratings yet
- Python Hands OnDocument11 pagesPython Hands Onprashant pal100% (1)
- Python Funstinos and OOPSDocument7 pagesPython Funstinos and OOPSyipemetNo ratings yet
- CNS (Full PGM)Document124 pagesCNS (Full PGM)KaleeswariNo ratings yet
- IR - 754 All PracticalDocument21 pagesIR - 754 All Practical754Durgesh VishwakarmaNo ratings yet
- Bab Iii, Iv, V FixDocument27 pagesBab Iii, Iv, V FixNela MuetzNo ratings yet
- Dictionaries: PythonDocument16 pagesDictionaries: PythonKsNo ratings yet
- New Daa RahulDocument24 pagesNew Daa RahulAbcd XyzNo ratings yet
- Holiday Coding TasksDocument6 pagesHoliday Coding TaskslavishbailsNo ratings yet
- CSE 3024: Web Mining: Lab Assessment - 3Document13 pagesCSE 3024: Web Mining: Lab Assessment - 3Nikitha ReddyNo ratings yet
- File Handling (FINAL)Document37 pagesFile Handling (FINAL)Nitasha GargNo ratings yet
- Machine Learning NLP LAB Sayak MallickDocument4 pagesMachine Learning NLP LAB Sayak MallickSayak MallickNo ratings yet
- Web Mining DADocument13 pagesWeb Mining DADeep AgrawalNo ratings yet
- DataStructure ProgramsDocument53 pagesDataStructure ProgramsKarthik ReddyNo ratings yet
- PRACTICAL FILE CS Armaan JaiswalDocument26 pagesPRACTICAL FILE CS Armaan JaiswalnikNo ratings yet
- SYCS - Algorithm Code From 1 To 15Document29 pagesSYCS - Algorithm Code From 1 To 15sagar panchalNo ratings yet
- Apr 2023Document32 pagesApr 2023Abhilash JoseNo ratings yet
- Python Final Lab 2019Document35 pagesPython Final Lab 2019vanithaNo ratings yet
- Analizador SintacticoDocument11 pagesAnalizador Sintacticojuan esteban lugo parradoNo ratings yet
- Artificial Intelligence (18Csc305J) Lab: EXPERIMENT 13: Implementation of NLP ProblemDocument9 pagesArtificial Intelligence (18Csc305J) Lab: EXPERIMENT 13: Implementation of NLP ProblemSAILASHREE PANDAB (RA1911032010030)No ratings yet
- DAA LabDocument41 pagesDAA Labpalaniperumal041979No ratings yet
- INS Journal VikasDocument54 pagesINS Journal Vikashaashboi5No ratings yet
- Rec 11Document49 pagesRec 11Tamer SultanyNo ratings yet
- AI Assignment: Asad Nasir - 37 Muhammad Usman Ali - 29 Momin - 49Document7 pagesAI Assignment: Asad Nasir - 37 Muhammad Usman Ali - 29 Momin - 49Crack TunesNo ratings yet
- Python 3 Oops Hands OnDocument7 pagesPython 3 Oops Hands OnrajeshNo ratings yet
- IndexDocument19 pagesIndexSarthak GuptaNo ratings yet
- New Microsoft Word DocumentDocument11 pagesNew Microsoft Word Documentseinkein9No ratings yet
- Caesar Cipher:: Applied Cryptography and Network Security SLOT: L21+L22 Lab Assignment - 1Document13 pagesCaesar Cipher:: Applied Cryptography and Network Security SLOT: L21+L22 Lab Assignment - 1R B SHARANNo ratings yet
- NLP - Practical ListDocument14 pagesNLP - Practical ListYash AminNo ratings yet
- Soundarya 256 NLP PractsDocument14 pagesSoundarya 256 NLP PractsKajal YadavNo ratings yet
- Program 1Document25 pagesProgram 1Asif BadegharNo ratings yet
- Daa Lab Manual Updated TpaDocument35 pagesDaa Lab Manual Updated TpaTHiru ArasuNo ratings yet
- Newton's Backward OutputDocument2 pagesNewton's Backward Outputfacto GamerNo ratings yet
- Simple NMTDocument3 pagesSimple NMTFurious FiveNo ratings yet
- ComputerDocument37 pagesComputerPalakNo ratings yet
- Python3 FrescoDocument8 pagesPython3 FrescoNaresh ReddyNo ratings yet
- EDA Plots CodeDocument13 pagesEDA Plots Codeprashant yadavNo ratings yet
- CodeDocument7 pagesCodeh8jmmxnzt4No ratings yet
- 12 CS Python Revision Tour 1&2 WorksheetDocument5 pages12 CS Python Revision Tour 1&2 WorksheetskltripathiNo ratings yet
- 2023 B Aleph SolDocument3 pages2023 B Aleph Solmoamin.shikhaNo ratings yet
- Fresco Code Python Application ProgrammingDocument7 pagesFresco Code Python Application ProgrammingTECHer YTNo ratings yet
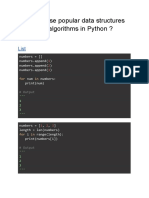
- How To Use Popular Data Structures and Algorithms in Python ?Document11 pagesHow To Use Popular Data Structures and Algorithms in Python ?Satish Singh100% (1)
- Assessment - 2: - K Mary NikithaDocument27 pagesAssessment - 2: - K Mary NikithaNikitha ReddyNo ratings yet
- Folder Creation 04012022Document11 pagesFolder Creation 04012022vinitha mohanrajNo ratings yet
- Practical File CS Nihal SainiDocument28 pagesPractical File CS Nihal SaininikNo ratings yet
- VCNLB 2023Document14 pagesVCNLB 2023Anirudh KesarkarNo ratings yet
- Praktikum 2 PI Genap2023Document4 pagesPraktikum 2 PI Genap2023Irgy Suwito SuryantoNo ratings yet
- Dictionary NotesDocument4 pagesDictionary NotesIlakkiyaa KPNo ratings yet
- Code:-: Compiler Construction (UCS802) Lab Assignment-2Document12 pagesCode:-: Compiler Construction (UCS802) Lab Assignment-2Devansh PahujaNo ratings yet
- "Name" "John" "Age": My - DictDocument7 pages"Name" "John" "Age": My - DictIoane ChumburidzeNo ratings yet
- Reading Merged Dataset Reading Merged Dataset: 'Import Successfull'Document7 pagesReading Merged Dataset Reading Merged Dataset: 'Import Successfull'Cookies KeepingNo ratings yet
- Exp 7Document3 pagesExp 7sumeet.mehraNo ratings yet
- Functions Python PracticeDocument8 pagesFunctions Python PracticeTheAncient01No ratings yet
- Python ExamplesDocument5 pagesPython ExamplesGandhimathiNo ratings yet
- CODIGO#Document4 pagesCODIGO#deger treuriNo ratings yet
- ArkoprovoRoy CSE 3rdyear PCA2 CnAssignmentDocument25 pagesArkoprovoRoy CSE 3rdyear PCA2 CnAssignmentSatya Priya SahaNo ratings yet
- Swp0udz5fa202202484 SP Exp 4Document10 pagesSwp0udz5fa202202484 SP Exp 4SK Relaxing MusicNo ratings yet
- Title: Should-Learn-From-Reddit-Gamestop-Market-Manipulation-And-Other-Recent-Headlines/?sh 1fe971c53cf2Document4 pagesTitle: Should-Learn-From-Reddit-Gamestop-Market-Manipulation-And-Other-Recent-Headlines/?sh 1fe971c53cf2Nikitha ReddyNo ratings yet
- CSE 3024: Web Mining: Lab Assessment - 3Document13 pagesCSE 3024: Web Mining: Lab Assessment - 3Nikitha ReddyNo ratings yet
- Assessment - 2: - K Mary NikithaDocument27 pagesAssessment - 2: - K Mary NikithaNikitha ReddyNo ratings yet
- School of Information Technology and EngineeringDocument17 pagesSchool of Information Technology and EngineeringNikitha ReddyNo ratings yet
- Logitech c922 Pro Stream Webcam 2434709 SpecsDocument2 pagesLogitech c922 Pro Stream Webcam 2434709 SpecsPurchase PDJNo ratings yet
- Intel Server Board S2600WT TPSDocument176 pagesIntel Server Board S2600WT TPSkenNo ratings yet
- AssetWise CONNECT Edition: Going DigitalDocument36 pagesAssetWise CONNECT Edition: Going DigitalRabindra RaiNo ratings yet
- IBM Integration Bus: Lab 6 Resolving Choices Using DiscriminatorsDocument29 pagesIBM Integration Bus: Lab 6 Resolving Choices Using DiscriminatorsLe Duc AnhNo ratings yet
- (XPANEL) To Communicate With Siemens S7-200 PPI Direct PDFDocument7 pages(XPANEL) To Communicate With Siemens S7-200 PPI Direct PDFMarkesoNo ratings yet
- Apps and Services - Guide PDFDocument5 pagesApps and Services - Guide PDFZephir AWTNo ratings yet
- I Am Sharing 'Interview' With YouDocument65 pagesI Am Sharing 'Interview' With YouBranch Reed100% (3)
- Research PaperDocument13 pagesResearch PaperPrateek IngoleNo ratings yet
- ST InspireCast 0005 Datasheet 8.5x11Document2 pagesST InspireCast 0005 Datasheet 8.5x11SOROMAP TNNo ratings yet
- Fundamentals of Engineering Drawing Coordinate Systems in AutoCADDocument38 pagesFundamentals of Engineering Drawing Coordinate Systems in AutoCADthorNo ratings yet
- Basquetball: Ball BoxDocument8 pagesBasquetball: Ball BoxJorge EncaladaNo ratings yet
- Let's Go: Zte Mf90 Getting Started With Your DeviceDocument2 pagesLet's Go: Zte Mf90 Getting Started With Your DeviceAnto PurwantoNo ratings yet
- SNS EN SN S Series 320 Datasheet 1Document2 pagesSNS EN SN S Series 320 Datasheet 1totNo ratings yet
- EDI Notepad GuideDocument45 pagesEDI Notepad GuideJaweed ShariffNo ratings yet
- Windows ADKDocument1,152 pagesWindows ADKA. Sergio RanzanNo ratings yet
- AC200 V 750W - 15kW: Downloaded FromDocument40 pagesAC200 V 750W - 15kW: Downloaded FromAk AndroidNo ratings yet
- Iitdelhi Lab AssignmentDocument4 pagesIitdelhi Lab AssignmentNitishkumarreddyervaNo ratings yet
- CNN Algorithms For Detection of Human Face Attributes - A SurveyDocument6 pagesCNN Algorithms For Detection of Human Face Attributes - A SurveyNurul AlamNo ratings yet
- (Action Required) Google Assignment OnboardinDocument4 pages(Action Required) Google Assignment OnboardinFranco LeveraNo ratings yet
- Employer's Requirements - O - General - Ed08Document34 pagesEmployer's Requirements - O - General - Ed08Ali KamelNo ratings yet
- SFF-8482 R2.5Document25 pagesSFF-8482 R2.5Siddhi SawantNo ratings yet
- Saurabh Chopade Resume APRDocument1 pageSaurabh Chopade Resume APREasy TutsNo ratings yet
- Chapter 2 Software Requirement EngDocument45 pagesChapter 2 Software Requirement EngJëbê Béløñgs Tö JêsüsNo ratings yet
- Computing Funda - Midterm ExamDocument10 pagesComputing Funda - Midterm ExamMark JamesNo ratings yet
- 5.5 Case Study:Smart Home: VunitDocument5 pages5.5 Case Study:Smart Home: VunitPonraj ParkNo ratings yet
- Ch4 3Document8 pagesCh4 3mohadNo ratings yet
- Generate A Random Name - Fake Name GeneratorDocument2 pagesGenerate A Random Name - Fake Name GeneratorCharles M. EvansNo ratings yet
- 16charsx2 Lines 1/16 Duty, 1/5bias: Ss DD ODocument1 page16charsx2 Lines 1/16 Duty, 1/5bias: Ss DD OСобирNo ratings yet
- 1 Introduction VB2008Document61 pages1 Introduction VB2008Zarif ZulkafliNo ratings yet