You might also like
- Data Scientist Girish Dasari ExperienceDocument3 pagesData Scientist Girish Dasari ExperienceGirish DasariNo ratings yet
- Vivek Varma K: Data Scientist - Data AnalystDocument5 pagesVivek Varma K: Data Scientist - Data AnalystAmit PandeyNo ratings yet
- Data Analyst with 7+ Years of ExperienceDocument4 pagesData Analyst with 7+ Years of Experiencevitig2No ratings yet
- MonishKunar DataAnalyst ResumeDocument3 pagesMonishKunar DataAnalyst Resumevalish silverspaceNo ratings yet
- Saketh Rao Data AnalystDocument2 pagesSaketh Rao Data Analystvalish silverspace100% (1)
- Resume: Rakesh Kumar Prasad Mobile:-09560910462 ObjectiveDocument6 pagesResume: Rakesh Kumar Prasad Mobile:-09560910462 ObjectiveRakesh PrasadNo ratings yet
- Arif Jahangir: Data Scientist - Machine Learning EngineerDocument4 pagesArif Jahangir: Data Scientist - Machine Learning EngineerjaniNo ratings yet
- Shilpa Ravichettu - Tableau3Document6 pagesShilpa Ravichettu - Tableau3anthony talentitNo ratings yet
- Tableau ResumeDocument5 pagesTableau Resumedon saligramNo ratings yet
- Resume-Senior Data Engineer-Etihad Airways-Kashish SuriDocument4 pagesResume-Senior Data Engineer-Etihad Airways-Kashish SuriAviraj kalraNo ratings yet
- Latha Data Analyst Resume..Document3 pagesLatha Data Analyst Resume..KIRAN KIRANNo ratings yet
- Data Architect - GCDocument4 pagesData Architect - GCmyprents.indiaNo ratings yet
- Karim Budhwani (470) 447-0765 Sr. Data Analyst Professional SummaryDocument4 pagesKarim Budhwani (470) 447-0765 Sr. Data Analyst Professional SummarySrikanth ReddyNo ratings yet
- Reetesh Jain2Document4 pagesReetesh Jain2Shantnu GuptaNo ratings yet
- TharaDocument4 pagesTharaAnusha RNo ratings yet
- Manu - Tomar - Data AnalystDocument2 pagesManu - Tomar - Data AnalystArun DhwajNo ratings yet
- Product Owner ProfileDocument2 pagesProduct Owner ProfileRahul ChintaNo ratings yet
- Akash Kasuladev Data AnalystDocument4 pagesAkash Kasuladev Data AnalystnnsoftsolutionsNo ratings yet
- Created Complex SQL Queries Using Temporary Tables, CTE's and Sub QueriesDocument8 pagesCreated Complex SQL Queries Using Temporary Tables, CTE's and Sub QueriesSushmitha chNo ratings yet
- Bhargavi - Certified Scrum Master with 8+ Years ExperienceDocument5 pagesBhargavi - Certified Scrum Master with 8+ Years ExperiencexovoNo ratings yet
- Saikiran Data - Engineer ResumeDocument7 pagesSaikiran Data - Engineer Resumeramu_uppadaNo ratings yet
- Resume - Dhruv Kharwar PDFDocument1 pageResume - Dhruv Kharwar PDFAnonymous OU3KH3xJ7pNo ratings yet
- Vinay Kumar Data EngineerDocument8 pagesVinay Kumar Data Engineerkevin711588No ratings yet
- Rajesh ReddyDocument3 pagesRajesh ReddyDownload FilesNo ratings yet
- Data Scientist Krishna Saigupta Resume SummaryDocument5 pagesData Scientist Krishna Saigupta Resume SummaryharshNo ratings yet
- Radhika Thotakura 331-271-6777Document7 pagesRadhika Thotakura 331-271-6777Ashwani kumarNo ratings yet
- Aslam, Mohammad Email: Phone: Big Data/Cloud DeveloperDocument6 pagesAslam, Mohammad Email: Phone: Big Data/Cloud DeveloperMadhav GarikapatiNo ratings yet
- Mohit BigData 5yrDocument3 pagesMohit BigData 5yrshreya arunNo ratings yet
- SQL Server Developer Resume: Karthikeyan PDocument3 pagesSQL Server Developer Resume: Karthikeyan PVenugopal KilaariNo ratings yet
- Notes On Dimension and FactsDocument32 pagesNotes On Dimension and FactsVamsi KarthikNo ratings yet
- Mastering Azure Synapse Analytics: Learn how to develop end-to-end analytics solutions with Azure Synapse Analytics (English Edition)From EverandMastering Azure Synapse Analytics: Learn how to develop end-to-end analytics solutions with Azure Synapse Analytics (English Edition)No ratings yet
- Naha Tabhulu ResumeDocument8 pagesNaha Tabhulu ResumeHARSHANo ratings yet
- Durgesh Sr. Data Architect / Modeler/BigdataDocument5 pagesDurgesh Sr. Data Architect / Modeler/BigdataMadhav Garikapati100% (1)
- ObjectiveDocument3 pagesObjectiveharshNo ratings yet
- Theertha Praveen E Sr. BSA Resume PDFDocument4 pagesTheertha Praveen E Sr. BSA Resume PDFAshutosh SinghNo ratings yet
- Resume 1Document3 pagesResume 1Damu GowdaNo ratings yet
- Sandeep Vallabhaneni: SQL Server Dba / Developer/ Bi DeveloperDocument8 pagesSandeep Vallabhaneni: SQL Server Dba / Developer/ Bi DevelopernicevenuNo ratings yet
- What is Apache Spark? The Complete GuideDocument65 pagesWhat is Apache Spark? The Complete GuideApurvaNo ratings yet
- Full Stack Java Developer and Actimize Consultant ResumeDocument5 pagesFull Stack Java Developer and Actimize Consultant ResumevishuchefNo ratings yet
- Data Architect or ETL Architect or BI Architect or Data WarehousDocument4 pagesData Architect or ETL Architect or BI Architect or Data Warehousapi-77236210No ratings yet
- Yogitha ResumeDocument8 pagesYogitha ResumeDilshad SmileyNo ratings yet
- GSC ResumeDocument3 pagesGSC ResumeSarath GrandheNo ratings yet
- Aslam Big Data EngineerDocument6 pagesAslam Big Data EngineerMadhav GarikapatiNo ratings yet
- Master Big Data Engineering with IBMDocument27 pagesMaster Big Data Engineering with IBMshrishaila_shettyNo ratings yet
- Ram Madhav ResumeDocument6 pagesRam Madhav Resumeramu_uppadaNo ratings yet
- Data Analysis and AutomtionDocument3 pagesData Analysis and AutomtionAshwin GirishNo ratings yet
- Profile Summary:: Work ExperienceDocument5 pagesProfile Summary:: Work ExperienceSharath ReddyNo ratings yet
- BigData - ResumeDocument5 pagesBigData - ResumemuralindlNo ratings yet
- VAMSI MicrostrategyDocument8 pagesVAMSI MicrostrategyJoshElliotNo ratings yet
- Cleaning Data With PySpark Chapter3Document25 pagesCleaning Data With PySpark Chapter3FgpeqwNo ratings yet
- Test Plan Template ProagricaDocument5 pagesTest Plan Template ProagricaKrishna KeerthiNo ratings yet
- Sep 2021 - Data ScientistDocument8 pagesSep 2021 - Data ScientistKrishna KeerthiNo ratings yet
- IHealth Login Testing HW - 19AUGDocument2 pagesIHealth Login Testing HW - 19AUGKrishna KeerthiNo ratings yet
- Master of Science in Computer Science - University of North Carolina, Charlotte, NCDocument2 pagesMaster of Science in Computer Science - University of North Carolina, Charlotte, NCKrishna KeerthiNo ratings yet
- Ihealth App - User Stories - S2Document8 pagesIhealth App - User Stories - S2Krishna KeerthiNo ratings yet
- Travis Walton Part 1 MUFON Case FileDocument346 pagesTravis Walton Part 1 MUFON Case FileClaudio Silva100% (1)
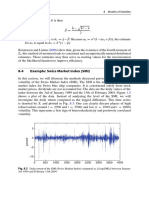
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- City MSJDocument50 pagesCity MSJHilary LedwellNo ratings yet
- Eole Press KitDocument15 pagesEole Press KitBob AndrepontNo ratings yet
- ChromosomesDocument24 pagesChromosomesapi-249102379No ratings yet
- Oracle Unified Method (OUM) White Paper - Oracle's Full Lifecycle Method For Deploying Oracle-Based Business Solutions - GeneralDocument17 pagesOracle Unified Method (OUM) White Paper - Oracle's Full Lifecycle Method For Deploying Oracle-Based Business Solutions - GeneralAndreea Mirosnicencu100% (1)
- Early Diabetic Risk Prediction Using Machine Learning Classification TechniquesDocument6 pagesEarly Diabetic Risk Prediction Using Machine Learning Classification TechniquesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Android TabletsDocument2 pagesAndroid TabletsMarcus McElhaneyNo ratings yet
- Boala Cronica Obstructive: BpocDocument21 pagesBoala Cronica Obstructive: BpocNicoleta IliescuNo ratings yet
- Service Parts List: 54-26-0005 2551-20 M12™ FUEL™ SURGE™ 1/4" Hex Hydraulic Driver K42ADocument2 pagesService Parts List: 54-26-0005 2551-20 M12™ FUEL™ SURGE™ 1/4" Hex Hydraulic Driver K42AAmjad AlQasrawi100% (1)
- CHEMICAL ANALYSIS OF WATER SAMPLEDocument5 pagesCHEMICAL ANALYSIS OF WATER SAMPLEAiron Fuentes EresNo ratings yet
- Inspection and Acceptance Report: Stock No. Unit Description QuantityDocument6 pagesInspection and Acceptance Report: Stock No. Unit Description QuantityAnj LeeNo ratings yet
- Durand Et Al JHRC 1997 Experimental Design Optimization of The Analysis of Gasoline by Capillary Gas ChromatographyDocument6 pagesDurand Et Al JHRC 1997 Experimental Design Optimization of The Analysis of Gasoline by Capillary Gas ChromatographyCatalinaSalamancaNo ratings yet
- Staining TechniquesDocument31 pagesStaining TechniquesKhadija JaraNo ratings yet
- BOQ - Hearts & Arrows Office 04sep2023Document15 pagesBOQ - Hearts & Arrows Office 04sep2023ChristianNo ratings yet
- Useful Relations in Quantum Field TheoryDocument30 pagesUseful Relations in Quantum Field TheoryDanielGutierrez100% (1)
- 266 009-336Document327 pages266 009-336AlinaE.BarbuNo ratings yet
- Mind Map On The History of Science, Technology and SocietyDocument1 pageMind Map On The History of Science, Technology and SocietyJohn Michael Vincent CarreonNo ratings yet
- SS1c MIDTERMS LearningModuleDocument82 pagesSS1c MIDTERMS LearningModuleBryce VentenillaNo ratings yet
- Casestudy3 Hbo MaDocument2 pagesCasestudy3 Hbo Ma132345usdfghjNo ratings yet
- More Than Moore: by M. Mitchell WaldropDocument4 pagesMore Than Moore: by M. Mitchell WaldropJuanjo ThepresisNo ratings yet
- Agilent Cool On-Column Operation ManualDocument42 pagesAgilent Cool On-Column Operation Manualdmcevoy1965No ratings yet
- Best Way To LearnDocument3 pagesBest Way To LearnRAMIZKHAN124No ratings yet
- Marulaberry Kicad EbookDocument23 pagesMarulaberry Kicad EbookPhan HaNo ratings yet
- Organic Chem Diels-Alder Reaction LabDocument9 pagesOrganic Chem Diels-Alder Reaction LabPryanka BalleyNo ratings yet
- ??????? ?? ??????Document29 pages??????? ?? ??????Aysha ShahabNo ratings yet
- PropensityModels PDFDocument4 pagesPropensityModels PDFSarbarup BanerjeeNo ratings yet
- Design ThinkingDocument16 pagesDesign ThinkingbhattanitanNo ratings yet
- Admisibility To Object EvidenceDocument168 pagesAdmisibility To Object EvidenceAnonymous 4WA9UcnU2XNo ratings yet
- 5.a Personal Diet Consultant For Healthy MealDocument5 pages5.a Personal Diet Consultant For Healthy MealKishore SahaNo ratings yet