You might also like
- Reasoning in AiDocument14 pagesReasoning in AipriyankaNo ratings yet
- Introduction To MLDocument39 pagesIntroduction To MLPooja Patwari100% (1)
- 100 Basic Mechanical Engineering Interview Questions Answers PDF Basic Mechanical Engineering Interview Questions Answers PDFDocument9 pages100 Basic Mechanical Engineering Interview Questions Answers PDF Basic Mechanical Engineering Interview Questions Answers PDFRahulBharti100% (2)
- Introduction To Deep Learning-1Document16 pagesIntroduction To Deep Learning-1Palak GandhiNo ratings yet
- Unit I Introduction To AI & ML - AVADocument85 pagesUnit I Introduction To AI & ML - AVAPratik KokateNo ratings yet
- Astm A153Document5 pagesAstm A153rachedNo ratings yet
- Machine LearningDocument211 pagesMachine LearningHarish100% (1)
- 1 - Machine Learning (Start)Document32 pages1 - Machine Learning (Start)Anmol DurgapalNo ratings yet
- Machine LearningDocument81 pagesMachine LearningtelmaNo ratings yet
- BGMEA University of Fashion & Technology (BUFT)Document27 pagesBGMEA University of Fashion & Technology (BUFT)Hassan Al MamunNo ratings yet
- Unit 1 - Machine Learning - WWW - Rgpvnotes.inDocument23 pagesUnit 1 - Machine Learning - WWW - Rgpvnotes.inxaiooNo ratings yet
- The 10 Algorithms Machine Learning Engineers Need To KnowDocument14 pagesThe 10 Algorithms Machine Learning Engineers Need To KnowNikhitha PaiNo ratings yet
- Machine Learning and Deep Learning TechnDocument9 pagesMachine Learning and Deep Learning TechnAndyBarredaMoscosoNo ratings yet
- Wireline PCE PDFDocument56 pagesWireline PCE PDFMuhammad ShahrukhNo ratings yet
- Unit - 5.1 - Introduction To Machine LearningDocument38 pagesUnit - 5.1 - Introduction To Machine LearningHarsh officialNo ratings yet
- Python UNIT-5Document67 pagesPython UNIT-5Chandan Kumar100% (1)
- Orifice PlateDocument18 pagesOrifice PlateAshvani Shukla100% (2)
- ML DL Projects and TutorialsDocument21 pagesML DL Projects and TutorialsAmal AbdallahNo ratings yet
- Ms0750 Vanguard 3-Cylinder Ohv LC Gasoline Briggs & StrattonDocument132 pagesMs0750 Vanguard 3-Cylinder Ohv LC Gasoline Briggs & StrattonKenn Ferro80% (5)
- Presentation On Artificial IntelligenceDocument19 pagesPresentation On Artificial IntelligenceJaswanth S vNo ratings yet
- Unit 4 Machine Learning Tools, Techniques and ApplicationsDocument78 pagesUnit 4 Machine Learning Tools, Techniques and ApplicationsJyothi PulikantiNo ratings yet
- Math 7 q2 Module 7Document12 pagesMath 7 q2 Module 7Rou GeeNo ratings yet
- Machine Learning For BeginnersDocument30 pagesMachine Learning For BeginnersVansh Jatana100% (1)
- ML Interview QuestionsDocument146 pagesML Interview QuestionsIndraneelGhoshNo ratings yet
- IRIS - FlowerDocument13 pagesIRIS - FlowerramNo ratings yet
- Machine Learning PracticesDocument26 pagesMachine Learning PracticesAkhil SinghNo ratings yet
- Machine Learning Summarized Notes 1660762916Document111 pagesMachine Learning Summarized Notes 1660762916Arundas PurakkatNo ratings yet
- Machine Learning For EveryoneDocument50 pagesMachine Learning For Everyonehali433No ratings yet
- L3 - Supervised and Unsupervised LearningDocument24 pagesL3 - Supervised and Unsupervised LearningGaurav Rohilla100% (1)
- MLDocument79 pagesMLkiranNo ratings yet
- Overview of Machine Learning PDFDocument57 pagesOverview of Machine Learning PDFAlexander100% (1)
- Artificial Intelligence (AI) / Machine Learning (ML) : Limited Seats OnlyDocument2 pagesArtificial Intelligence (AI) / Machine Learning (ML) : Limited Seats OnlymukramkhanNo ratings yet
- Machine Learning TutorialDocument44 pagesMachine Learning Tutorialvepowo LandryNo ratings yet
- Chapter 6 AIDocument63 pagesChapter 6 AIMULUKEN TILAHUNNo ratings yet
- Machine Learning Digital Notes (R18a0526)Document118 pagesMachine Learning Digital Notes (R18a0526)Mr TejaNo ratings yet
- L10a - Machine Learning Basic ConceptsDocument80 pagesL10a - Machine Learning Basic ConceptsMeilysaNo ratings yet
- Machine Learning Notes Unit 1 To 4Document101 pagesMachine Learning Notes Unit 1 To 4Saurabh KansaraNo ratings yet
- AI Important QuestionsDocument196 pagesAI Important QuestionsTushar GuptaNo ratings yet
- Learning AIDocument27 pagesLearning AIShankerNo ratings yet
- Basic Data Science Interview Questions: 1. What Do You Understand by Linear Regression?Document38 pagesBasic Data Science Interview Questions: 1. What Do You Understand by Linear Regression?sahil kumarNo ratings yet
- Basic Data Science Interview Questions: 1. What Do You Understand by Linear Regression?Document38 pagesBasic Data Science Interview Questions: 1. What Do You Understand by Linear Regression?sahil kumarNo ratings yet
- Basic Data Science Interview Questions: 1. What Do You Understand by Linear Regression?Document38 pagesBasic Data Science Interview Questions: 1. What Do You Understand by Linear Regression?sahil kumarNo ratings yet
- Supervised LearningDocument19 pagesSupervised LearningSauki RidwanNo ratings yet
- Deep Learning QuestionsDocument51 pagesDeep Learning QuestionsAditi Jaiswal100% (1)
- Essential Mathematics Primary 3 Teachers Guide 9789988897352ARDocument192 pagesEssential Mathematics Primary 3 Teachers Guide 9789988897352ARD Jay Zark100% (2)
- EXPLAIN M03 - 1 Radio Network Planning ProcessDocument42 pagesEXPLAIN M03 - 1 Radio Network Planning ProcessMiguel Andres Vanegas GNo ratings yet
- Artificial Intelligence: Slide 6Document42 pagesArtificial Intelligence: Slide 6fatima hussainNo ratings yet
- Supervised Vs UnsupervisedDocument8 pagesSupervised Vs UnsupervisedKhaula MughalNo ratings yet
- Fog Computing With Integration of IotDocument21 pagesFog Computing With Integration of IotUday ChandraNo ratings yet
- Artificial IntelligenceDocument23 pagesArtificial Intelligenceteddy demissieNo ratings yet
- DATA MINING and MACHINE LEARNING. CLASSIFICATION PREDICTIVE TECHNIQUES: SUPPORT VECTOR MACHINE, LOGISTIC REGRESSION, DISCRIMINANT ANALYSIS and DECISION TREES: Examples with MATLABFrom EverandDATA MINING and MACHINE LEARNING. CLASSIFICATION PREDICTIVE TECHNIQUES: SUPPORT VECTOR MACHINE, LOGISTIC REGRESSION, DISCRIMINANT ANALYSIS and DECISION TREES: Examples with MATLABNo ratings yet
- 20EC067 AI AssignmentDocument32 pages20EC067 AI Assignment20EC081 Satyam ShuklaNo ratings yet
- Machine Learning1Document11 pagesMachine Learning1Rishab Bhattacharyya100% (1)
- Artificial IntelligenceDocument130 pagesArtificial IntelligenceTorres GautamNo ratings yet
- Artificial Intelligence: (Unit 1: Introduction)Document10 pagesArtificial Intelligence: (Unit 1: Introduction)Lucky sahNo ratings yet
- I M. Tech. - I Sem. (CSE) L T C 3 0 3 Program Elective I (16CS5010) Course ObjectivesDocument8 pagesI M. Tech. - I Sem. (CSE) L T C 3 0 3 Program Elective I (16CS5010) Course ObjectivesManjunath KV Assistant Professor (CSE)No ratings yet
- Artificial Inteligence PDFDocument328 pagesArtificial Inteligence PDFLPomelo7No ratings yet
- ML Notes Unit 1-2Document55 pagesML Notes Unit 1-2Mudit MattaNo ratings yet
- UNIT-1 Foundations of Deep LearningDocument51 pagesUNIT-1 Foundations of Deep Learningbhavana100% (1)
- Government Polytechnic College: Machine LearningDocument22 pagesGovernment Polytechnic College: Machine LearningAnand SpNo ratings yet
- ProjectDocument15 pagesProjectayush negiNo ratings yet
- Seminar ReportDocument42 pagesSeminar Reportsammuel john100% (1)
- NLP and ML ProjectDocument37 pagesNLP and ML ProjectAhhishek VaranasiNo ratings yet
- AI ApplicationsDocument165 pagesAI ApplicationsHosam HatimNo ratings yet
- Training Report On Machine LearningDocument27 pagesTraining Report On Machine LearningBhavesh yadavNo ratings yet
- ML Unit 1 PallavDocument22 pagesML Unit 1 Pallavravi joshiNo ratings yet
- Tesla Stock Marketing Price PredictionDocument62 pagesTesla Stock Marketing Price Predictionsyedhaji1996No ratings yet
- Unit 3Document10 pagesUnit 3vamsi kiranNo ratings yet
- Decision Trees. These Models Use Observations About CertainDocument6 pagesDecision Trees. These Models Use Observations About CertainashkingNo ratings yet
- Evolutional Study On KNN and K-Means Algorithms (SP)Document9 pagesEvolutional Study On KNN and K-Means Algorithms (SP)Vinit MehtaNo ratings yet
- IOT Network Technology LAB: // AlgorithmDocument29 pagesIOT Network Technology LAB: // Algorithmsahil kumarNo ratings yet
- What Are The Differences Between Supervised and Unsupervised Learning?Document21 pagesWhat Are The Differences Between Supervised and Unsupervised Learning?sahil kumarNo ratings yet
- What Are The Differences Between Supervised and Unsupervised Learning?Document22 pagesWhat Are The Differences Between Supervised and Unsupervised Learning?sahil kumarNo ratings yet
- Textbook Ebook Applied Mechanics of Polymers Properties Processing and Behavior George Youssef All Chapter PDFDocument43 pagesTextbook Ebook Applied Mechanics of Polymers Properties Processing and Behavior George Youssef All Chapter PDFbetty.combs185100% (6)
- Electrical Vehicle MCQ - Unit 1 & 2Document15 pagesElectrical Vehicle MCQ - Unit 1 & 2Rocky RuleNo ratings yet
- ModdingDocument24 pagesModdingsg 85No ratings yet
- Irfp 4368 PBFDocument8 pagesIrfp 4368 PBFarcatusNo ratings yet
- Gas Turbine Drain Pit Line Descriptions: From West Side To Left Side Water Tray Oil TrayDocument2 pagesGas Turbine Drain Pit Line Descriptions: From West Side To Left Side Water Tray Oil Traysaeed ahmedNo ratings yet
- WarehousesDocument71 pagesWarehousesR3pl1c4No ratings yet
- MATH 545, Stochastic Calculus Problem Set 2: January 24, 2019Document7 pagesMATH 545, Stochastic Calculus Problem Set 2: January 24, 2019patriciaNo ratings yet
- Kinetics Body Work&Energy Impulse&MomentumDocument26 pagesKinetics Body Work&Energy Impulse&MomentumKano MolapisiNo ratings yet
- NetSDK Programming Manual (Intelligent Event)Document116 pagesNetSDK Programming Manual (Intelligent Event)romarmoNo ratings yet
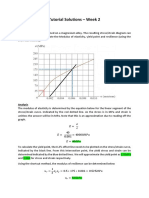
- Week 2 - Tutorial SolutionsDocument4 pagesWeek 2 - Tutorial SolutionsAsian JesusNo ratings yet
- Ex8 14Document2 pagesEx8 14nagesha_basappa865No ratings yet
- What Are The Two Types of IonsDocument2 pagesWhat Are The Two Types of Ionsugna100% (2)
- Sine and Cosine Rule: Formul Ae For Right-Angled Triangl EsDocument7 pagesSine and Cosine Rule: Formul Ae For Right-Angled Triangl EsJennifer ElliottNo ratings yet
- Trickling Filter EquationsDocument5 pagesTrickling Filter EquationsManish Kumar GhoraNo ratings yet
- مُثَلَّث: Maslas Meaning in EnglishDocument1 pageمُثَلَّث: Maslas Meaning in EnglishMr Asraf AllyNo ratings yet
- Mole Concept Notes 2Document43 pagesMole Concept Notes 2Gupta's StudioNo ratings yet
- Delta Log Interpretation 79Document44 pagesDelta Log Interpretation 79ragil saputroNo ratings yet
- Extra Unit 18 Speed Distance and TimeDocument7 pagesExtra Unit 18 Speed Distance and TimeJohn LeeNo ratings yet
- Artificial Intelligence (Professional Elective - I) Ech. III Year II Sem. LTP C Course Code: CS613PE 3 0 0 3Document2 pagesArtificial Intelligence (Professional Elective - I) Ech. III Year II Sem. LTP C Course Code: CS613PE 3 0 0 3Swathi TudicherlaNo ratings yet
- 28 Continuity & Diffrentiability Part 1 of 1Document23 pages28 Continuity & Diffrentiability Part 1 of 1Mehul JainNo ratings yet
- Unit V - 2binary Ripple CounterDocument11 pagesUnit V - 2binary Ripple CounterThiriveedhi SubbarayuduNo ratings yet