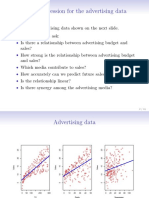
You might also like
- Stanford University CS 229, Autumn 2014 Midterm ExaminationDocument23 pagesStanford University CS 229, Autumn 2014 Midterm ExaminationErico ArchetiNo ratings yet
- Faar Field ManualDocument65 pagesFaar Field ManualAmit Srivastava100% (2)
- Seminar 1 SolutionsDocument9 pagesSeminar 1 SolutionsLavinia MinoiuNo ratings yet
- Instantaneous Rate of Change Application 1-Average Cost, Average Revenue and Average ProfitDocument8 pagesInstantaneous Rate of Change Application 1-Average Cost, Average Revenue and Average ProfitLuCiFeR GamingNo ratings yet
- Lecture PDFDocument115 pagesLecture PDFAnwar HussainNo ratings yet
- KK MathDocument13 pagesKK Mathm-3977431No ratings yet
- Constructing A Probability Histogram A Continues Random VariableDocument23 pagesConstructing A Probability Histogram A Continues Random Variablekateangel ellesoNo ratings yet
- Reading 8: Probability ConceptsDocument31 pagesReading 8: Probability ConceptsAlex PaulNo ratings yet
- 3 Linear Regression-Handout PDFDocument48 pages3 Linear Regression-Handout PDFTaylor TamNo ratings yet
- Statistics Test Attended For The Various SMEs PositionDocument31 pagesStatistics Test Attended For The Various SMEs PositionSibani MishraNo ratings yet
- Session 2 Probability DistributionDocument28 pagesSession 2 Probability DistributionVarun KashyapNo ratings yet
- Solutions Final Exam Quantitative Data Analysis 1 2023 For Canvas - 1708763533Document5 pagesSolutions Final Exam Quantitative Data Analysis 1 2023 For Canvas - 1708763533Adham MahdyNo ratings yet
- Phy Quiz BeeDocument6 pagesPhy Quiz BeeFrancine Esther CruzNo ratings yet
- Probablity DistributionDocument10 pagesProbablity DistributionsolomonmeleseNo ratings yet
- Expectations 13 PagesDocument13 pagesExpectations 13 PagesVelocidad 0.5No ratings yet
- Statistics and Probability Module 3: Week 3: Third QuarterDocument7 pagesStatistics and Probability Module 3: Week 3: Third QuarterALLYSSA MAE PELONIANo ratings yet
- On-Line - Tutoriales (1, 2, 3, 4 y 5)Document22 pagesOn-Line - Tutoriales (1, 2, 3, 4 y 5)Antonio LMNo ratings yet
- Formula of Weighted Average MeanDocument8 pagesFormula of Weighted Average MeanJames HathawayNo ratings yet
- 11.test of SignificanceDocument7 pages11.test of SignificanceTasbir HasanNo ratings yet
- Week 3Document27 pagesWeek 3Sevilla RonabelleNo ratings yet
- Economics 201b Spring 2010 Problem Set 4 SolutionsDocument15 pagesEconomics 201b Spring 2010 Problem Set 4 SolutionsTariq SultanNo ratings yet
- DISCRETE PROBABILITY DISTRIBUTION SchoologyDocument19 pagesDISCRETE PROBABILITY DISTRIBUTION SchoologyEricka Jane Roga PalenciaNo ratings yet
- MEAN - Stats and ProbabilityDocument19 pagesMEAN - Stats and ProbabilityCharisse Buenaventura50% (2)
- 18bge14a U4Document16 pages18bge14a U4Deepak karhana?No ratings yet
- Lesson 3 PresentationDocument21 pagesLesson 3 PresentationD E L INo ratings yet
- 04 Task Performance 1Document6 pages04 Task Performance 1Joel ArriolaNo ratings yet
- Slide-Co Minh NTDocument162 pagesSlide-Co Minh NTwikileaks30No ratings yet
- Solution of Business Stat PaperDocument17 pagesSolution of Business Stat Paperdanial khanNo ratings yet
- Chi-Square Goodness of Fit Test and Its ApplicationsDocument3 pagesChi-Square Goodness of Fit Test and Its ApplicationsTayyaba MahrNo ratings yet
- Lesson 5 The Bernoulli DistributionDocument9 pagesLesson 5 The Bernoulli DistributionJed De guzmanNo ratings yet
- Formula Sheet: Calculating The Mean (Average)Document3 pagesFormula Sheet: Calculating The Mean (Average)jedNo ratings yet
- Formule TestDocument2 pagesFormule TestPlushulik AninaNo ratings yet
- W9PSDocument9 pagesW9PSpolar necksonNo ratings yet
- Multiple Events SummaryDocument6 pagesMultiple Events SummaryNeelima ChintaNo ratings yet
- BALANGUE ALLEN JOHN Lesson 5Document21 pagesBALANGUE ALLEN JOHN Lesson 5James ScoldNo ratings yet
- Chapter 4 PDFDocument11 pagesChapter 4 PDFEurice Amber KatigbakNo ratings yet
- Essential Knowledge: Lesson 2. Optimization ProcessDocument6 pagesEssential Knowledge: Lesson 2. Optimization ProcessMaria Jane PerezNo ratings yet
- Tutorial 3 Sem 1 2021-22Document3 pagesTutorial 3 Sem 1 2021-22Pap Zhong HuaNo ratings yet
- Normal Approximation of The Poisson DistributionDocument1 pageNormal Approximation of The Poisson DistributionChooi Jia YueNo ratings yet
- Midterm 2014Document23 pagesMidterm 2014Zeeshan Ali SayyedNo ratings yet
- QM ICAP Past Paper Answers 2009 To 2014Document88 pagesQM ICAP Past Paper Answers 2009 To 2014salwa asifNo ratings yet
- Ist 214-Statictics Ii: Week 3: Discrete Random Variables and Probability Distributions, Expected Values and VariancesDocument18 pagesIst 214-Statictics Ii: Week 3: Discrete Random Variables and Probability Distributions, Expected Values and Variancesmelekkbass10No ratings yet
- Formula Sheet 1Document5 pagesFormula Sheet 1Ghender TapecNo ratings yet
- Mixture Problems (2hrs)Document13 pagesMixture Problems (2hrs)Dhiman NathNo ratings yet
- Justine Abundo (Activity1)Document7 pagesJustine Abundo (Activity1)justine abundoNo ratings yet
- Central Limit Theorm ExamplesDocument3 pagesCentral Limit Theorm ExamplesOdumetseNo ratings yet
- Normal SolutionDocument7 pagesNormal SolutionramasamyNo ratings yet
- Solution Manual For Introductory Statistics 9th by MannDocument25 pagesSolution Manual For Introductory Statistics 9th by MannKatelynWebsterikzj100% (44)
- STATS For Business Lec 6Document53 pagesSTATS For Business Lec 6Tiger HồNo ratings yet
- SAT Math To Know in One Page PDFDocument3 pagesSAT Math To Know in One Page PDFhaya khaledNo ratings yet
- MinimizationDocument8 pagesMinimizationDiana Rose MustacisaNo ratings yet
- HomeworkB7 1Document11 pagesHomeworkB7 1Rosalie NaritNo ratings yet
- 14-Apr-Examples-Normal and Standard Normal Probability DistributionDocument82 pages14-Apr-Examples-Normal and Standard Normal Probability DistributionAmmar AshrafNo ratings yet
- Mean, Variance, and Standard Deviation ofDocument15 pagesMean, Variance, and Standard Deviation ofShiela Mae GatchalianNo ratings yet
- Problem Set 2 SolutionsDocument4 pagesProblem Set 2 SolutionsandrewlimjfNo ratings yet
- Statistics ProjectDocument14 pagesStatistics ProjectJevbszen RemiendoNo ratings yet
- mt1 2019 SolnDocument8 pagesmt1 2019 Solncdh367No ratings yet
- Ellen Fin3701 S2Document6 pagesEllen Fin3701 S2George DywiliNo ratings yet
- MA101 End Semester Examination 2019 20 - SolutionsDocument9 pagesMA101 End Semester Examination 2019 20 - SolutionsjagpreetNo ratings yet
- Economics 201b Spring 2010 Problem Set 4 SolutionsDocument15 pagesEconomics 201b Spring 2010 Problem Set 4 SolutionsgizNo ratings yet
- Cambridge Mathematics AS and A Level Course: Second EditionFrom EverandCambridge Mathematics AS and A Level Course: Second EditionNo ratings yet
- Reading 11: Hypothesis TestingDocument28 pagesReading 11: Hypothesis TestingAlex PaulNo ratings yet
- Reading 50: Introduction To Alternative InvestmentsDocument68 pagesReading 50: Introduction To Alternative InvestmentsAlex PaulNo ratings yet
- L1R41 - Annotated - LiveDocument52 pagesL1R41 - Annotated - LiveAlex PaulNo ratings yet
- Reading 21: Understanding Income StatementsDocument62 pagesReading 21: Understanding Income StatementsAlex Paul100% (1)
- Reading 53: Portfolio Risk and Return: Part IIDocument37 pagesReading 53: Portfolio Risk and Return: Part IIAlex PaulNo ratings yet
- Reading 48: Derivative Markets and InstrumentsDocument20 pagesReading 48: Derivative Markets and InstrumentsAlex PaulNo ratings yet
- Reading 52: Portfolio Risk and Return: Part IDocument48 pagesReading 52: Portfolio Risk and Return: Part IAlex PaulNo ratings yet
- Reading 28: Non-Current (Long-Term Liabilities)Document33 pagesReading 28: Non-Current (Long-Term Liabilities)Alex PaulNo ratings yet
- L1R32 Annotated CalculatorDocument33 pagesL1R32 Annotated CalculatorAlex PaulNo ratings yet
- Reading 19: Introduction To Financial Statement AnalysisDocument43 pagesReading 19: Introduction To Financial Statement AnalysisAlex PaulNo ratings yet
- Reading 7: Statistical Concepts and Market ReturnsDocument26 pagesReading 7: Statistical Concepts and Market ReturnsAlex PaulNo ratings yet
- Course Text: Notes Will Be Provided Online Throughout The Semester. They Will Include The HomeworkDocument5 pagesCourse Text: Notes Will Be Provided Online Throughout The Semester. They Will Include The HomeworkKuro KinokoNo ratings yet
- Quality Assurance and Quality Control in The Analytical Chemical Laboratory: A Practical Approach Second Edition KonieczkaDocument54 pagesQuality Assurance and Quality Control in The Analytical Chemical Laboratory: A Practical Approach Second Edition Konieczkagreg.kaplan124100% (2)
- OpenStax Statistics CH04 LectureSlides - IsuDocument48 pagesOpenStax Statistics CH04 LectureSlides - IsuAtiwag, Micha T.No ratings yet
- Uniform DistributionDocument6 pagesUniform DistributionYoftahiNo ratings yet
- Cantor DistributionDocument3 pagesCantor Distributionshiena8181No ratings yet
- EECE 5639 Computer Vision I: Filtering, Probability ReviewDocument54 pagesEECE 5639 Computer Vision I: Filtering, Probability ReviewSourabh Sisodia SrßNo ratings yet
- Exercise # 2 StatDocument3 pagesExercise # 2 StatAilyn LabajoNo ratings yet
- EPE2303 Transmission and Distribution - 9. System ReliabilityDocument43 pagesEPE2303 Transmission and Distribution - 9. System ReliabilityBryan KekNo ratings yet
- Probability Theory and Stochastic Process (EC305ES)Document33 pagesProbability Theory and Stochastic Process (EC305ES)Andxp51100% (1)
- Mat303 - Probabilty and Random ProcessesDocument3 pagesMat303 - Probabilty and Random ProcessesChandra PrriyanNo ratings yet
- Machine Learning Algorithms in Depth (MEAP V09) (Vadim Smolyakov) (Z-Library)Document550 pagesMachine Learning Algorithms in Depth (MEAP V09) (Vadim Smolyakov) (Z-Library)AgalievNo ratings yet
- Formula Sheet 1 Probability Distributions: 1.1 The Binomial DistributionDocument8 pagesFormula Sheet 1 Probability Distributions: 1.1 The Binomial DistributionAlan TruongNo ratings yet
- Books 3337 0 0 (1201-1240)Document40 pagesBooks 3337 0 0 (1201-1240)Pablo LedezmaNo ratings yet
- Unit4 StatisticsDocument37 pagesUnit4 StatisticspreetamNo ratings yet
- UTS Business Statistics: Continuous ProbabilityDocument6 pagesUTS Business Statistics: Continuous ProbabilityemilyNo ratings yet
- Probability: Totalfavourable Events Total Number of ExperimentsDocument39 pagesProbability: Totalfavourable Events Total Number of Experimentsmasing4christNo ratings yet
- Random Number GenerationDocument43 pagesRandom Number GenerationAnsh GanatraNo ratings yet
- Abu-Zinadah 2015Document24 pagesAbu-Zinadah 2015zeeshanNo ratings yet
- Week5 BAMDocument48 pagesWeek5 BAMrajaayyappan317No ratings yet
- 4 HeterogenitasDocument46 pages4 HeterogenitasRan TanNo ratings yet
- CHAPTER3 - Discrete Random VariablesDocument28 pagesCHAPTER3 - Discrete Random VariablesDustin WhiteNo ratings yet
- 1703 09648Document209 pages1703 09648F JNo ratings yet
- Random Processes and Sequences: Chapter ThreeDocument52 pagesRandom Processes and Sequences: Chapter ThreeFrances DiazNo ratings yet
- Distribution System Loss (DSL) SegregatorDocument79 pagesDistribution System Loss (DSL) Segregatorrivnad007No ratings yet
- GATE - Communication EngineeringDocument120 pagesGATE - Communication EngineeringMurthy100% (1)
- B.SC Statistics Main&AlliedDocument123 pagesB.SC Statistics Main&AlliedJanakiramanNo ratings yet
- Lecture 3 DistributionDocument101 pagesLecture 3 DistributionSabbir Hasan MonirNo ratings yet
- Asset-V1 MITx+CTL - SC0x+1T2021+type@asset+block@SC0x W7L2 ManagingUncertainty2 FINAL CLEAN UpdDocument27 pagesAsset-V1 MITx+CTL - SC0x+1T2021+type@asset+block@SC0x W7L2 ManagingUncertainty2 FINAL CLEAN UpdNguyen DuyNo ratings yet
- Bản Sao Ch04.v1aDocument52 pagesBản Sao Ch04.v1aNhat ThiNo ratings yet