You might also like
- Gamp4 VS Gamp5Document1 pageGamp4 VS Gamp5Khushi PatelNo ratings yet
- Captiva Engine 3.6 L Repair Instructions - Off VehicleDocument510 pagesCaptiva Engine 3.6 L Repair Instructions - Off VehicleLucian100% (1)
- Unit - IiDocument46 pagesUnit - IiJit AggNo ratings yet
- Chapter 2 AADocument11 pagesChapter 2 AAselemon GamoNo ratings yet
- Assignment 1Document18 pagesAssignment 1Sania AimenNo ratings yet
- The Institute of Mathematical Sciences C. I. T. Campus Chennai - 600 113. Email: Vraman@imsc - Res.inDocument25 pagesThe Institute of Mathematical Sciences C. I. T. Campus Chennai - 600 113. Email: Vraman@imsc - Res.inrocksisNo ratings yet
- Solution: Finite Element Method, Vii Sem, Mechanical Engineering, Set-ADocument8 pagesSolution: Finite Element Method, Vii Sem, Mechanical Engineering, Set-AJay RaghavNo ratings yet
- 2011isse SCCDocument10 pages2011isse SCCssfofoNo ratings yet
- Sequential and Parallel Sorting AlgorithmsDocument63 pagesSequential and Parallel Sorting AlgorithmskesharwanidurgeshNo ratings yet
- On Implementation of Merge Sort: Kushal Jangid April 6, 2015Document10 pagesOn Implementation of Merge Sort: Kushal Jangid April 6, 2015Gaurav TolaniNo ratings yet
- Data Structure Unit 3 Important QuestionsDocument32 pagesData Structure Unit 3 Important QuestionsYashaswi Srivastava100% (1)
- Assignment 3Document20 pagesAssignment 3mahek saliaNo ratings yet
- Ch5-Searching-Part1-The Design and Analysis of Parallel Algori - Selim G AklDocument8 pagesCh5-Searching-Part1-The Design and Analysis of Parallel Algori - Selim G AklHendro UtomoNo ratings yet
- Daa Unit-2Document53 pagesDaa Unit-2pihadar269No ratings yet
- Module-2:Divide and ConquerDocument26 pagesModule-2:Divide and ConquerSk ShettyNo ratings yet
- Unit 6 Divide and Conquer: StructureDocument26 pagesUnit 6 Divide and Conquer: StructureRaj SinghNo ratings yet
- SearchingDocument29 pagesSearchingEka Sri CahyantiNo ratings yet
- MidsemDocument6 pagesMidsemAravind SomasundaramNo ratings yet
- What Are Stacks and QueuesDocument13 pagesWhat Are Stacks and QueuesrizawanshaikhNo ratings yet
- Homework # 1: Design and Analysis of Algorithms CS 302 Spring 2019Document4 pagesHomework # 1: Design and Analysis of Algorithms CS 302 Spring 2019Amna ArshadNo ratings yet
- 2alg Lecture2Document21 pages2alg Lecture2Harshit RoyNo ratings yet
- Saq 4 DSDocument5 pagesSaq 4 DSabinashreddy792No ratings yet
- Notes On Divide-and-Conquer and Dynamic Programming.: 1 N 1 n/2 n/2 +1 NDocument11 pagesNotes On Divide-and-Conquer and Dynamic Programming.: 1 N 1 n/2 n/2 +1 NMrunal RuikarNo ratings yet
- Unit 3 Divide and Conquer: StructureDocument18 pagesUnit 3 Divide and Conquer: StructureJohn ArthurNo ratings yet
- Lab Session 07: ObjectDocument5 pagesLab Session 07: ObjectMohammad Anas BalochNo ratings yet
- Cormen 2nd Edition SolutionsDocument99 pagesCormen 2nd Edition SolutionsManu ThakurNo ratings yet
- 01 CS251 Ch2 Getting StartedDocument20 pages01 CS251 Ch2 Getting StartedAhmad AlarabyNo ratings yet
- NM3 Root s02Document15 pagesNM3 Root s02sori1386No ratings yet
- Rudiments of Io AnalysisDocument18 pagesRudiments of Io AnalysisJay-ar MiraNo ratings yet
- 8.5 Selecting The MTH Largest: Indx (1..n) Indexx Irank (1..n)Document5 pages8.5 Selecting The MTH Largest: Indx (1..n) Indexx Irank (1..n)Vinay GuptaNo ratings yet
- Unit - Ii: Divide and Conquer: General MethodDocument32 pagesUnit - Ii: Divide and Conquer: General MethodFreddy Basil ThankachanNo ratings yet
- Binary SearchDocument12 pagesBinary SearchpetejuanNo ratings yet
- Divide and Conquer: Module-2Document16 pagesDivide and Conquer: Module-2himanshu malikNo ratings yet
- Introduction To Design Analysis of Algorithms in Simple WayDocument142 pagesIntroduction To Design Analysis of Algorithms in Simple WayRafael SilvaNo ratings yet
- Lecture - 2 On Data Structures: PreliminariesDocument10 pagesLecture - 2 On Data Structures: PreliminariesMohitNo ratings yet
- Algorithms Question BankDocument15 pagesAlgorithms Question BankPablo AhmedNo ratings yet
- K-Means & K-Harmonic Means: A Comparison of Two Unsupervised Clustering AlgorithmsDocument9 pagesK-Means & K-Harmonic Means: A Comparison of Two Unsupervised Clustering Algorithmssuveyda kursuncuNo ratings yet
- 20MCA023 Algorithm AssighnmentDocument13 pages20MCA023 Algorithm AssighnmentPratik KakaniNo ratings yet
- Pareto Analysis TechniqueDocument15 pagesPareto Analysis TechniqueAlberipaNo ratings yet
- K-Means Clustering Algorithm - JavatpointDocument21 pagesK-Means Clustering Algorithm - Javatpointmangotwin22No ratings yet
- State Space Modelling Versus ARIMA Time-Series ModellingDocument9 pagesState Space Modelling Versus ARIMA Time-Series ModellingAmsalu WalelignNo ratings yet
- Project 1Document11 pagesProject 1Ahmed AbdelhalimNo ratings yet
- K. J. Somaiya College of Engineering, Mumbai-77Document7 pagesK. J. Somaiya College of Engineering, Mumbai-77ARNAB DENo ratings yet
- SortingDocument57 pagesSortingSanjeeb PradhanNo ratings yet
- (Data Structure AND Algorathims) : (Teacher: MR Yang Weichao)Document6 pages(Data Structure AND Algorathims) : (Teacher: MR Yang Weichao)aliNo ratings yet
- Algo PaperDocument5 pagesAlgo PaperUzmanNo ratings yet
- BG Ksort Ieeetoc - PSDocument9 pagesBG Ksort Ieeetoc - PSfarleyknightNo ratings yet
- Lecture4 NotesDocument7 pagesLecture4 NotesKutemwa MithiNo ratings yet
- Divide and Conquer: Analysis of AlgorithmsDocument11 pagesDivide and Conquer: Analysis of Algorithmsgashaw asmamawNo ratings yet
- End Term Exam: Sukrit Chatterjee - E19ECE039Document6 pagesEnd Term Exam: Sukrit Chatterjee - E19ECE039Sukrit ChatterjeeNo ratings yet
- 0.1 Worst and Best Case AnalysisDocument6 pages0.1 Worst and Best Case Analysisshashank dwivediNo ratings yet
- Computer Network Assignment HelpDocument17 pagesComputer Network Assignment HelpComputer Network Assignment Help100% (1)
- Nonlinear Programming Based Sliding Mode Control of An Inverted PendulumDocument5 pagesNonlinear Programming Based Sliding Mode Control of An Inverted Pendulumvirus101No ratings yet
- Computer GeneratedDocument3 pagesComputer GeneratedDebela NanessoNo ratings yet
- Closest Points ProblemDocument11 pagesClosest Points ProblemSom SirurmathNo ratings yet
- Minimum and MaximumDocument28 pagesMinimum and MaximumDinoNo ratings yet
- Daa Lab ManualDocument55 pagesDaa Lab ManualHathiram PawarNo ratings yet
- Topic 1 Overview of Intelligent SystemsDocument35 pagesTopic 1 Overview of Intelligent SystemsPurvi ChaurasiaNo ratings yet
- Actavis Corporate Identity Manual MayDocument50 pagesActavis Corporate Identity Manual MayDanNo ratings yet
- Detection and Verification System of Handwriting and Signature Using Raspberry Picopy 220426094934Document48 pagesDetection and Verification System of Handwriting and Signature Using Raspberry Picopy 220426094934Akmad Ali AbdulNo ratings yet
- Course Structure & Syllabus M.Tech: Digital System & Computer Electronics (DSCE)Document66 pagesCourse Structure & Syllabus M.Tech: Digital System & Computer Electronics (DSCE)Nikhil KumarNo ratings yet
- Manual Serie TC3YF - Autonics PDFDocument1 pageManual Serie TC3YF - Autonics PDFJuan Manuel EscorihuelaNo ratings yet
- MH-500 (I) 0i-MC Machine Instruction ManualDocument109 pagesMH-500 (I) 0i-MC Machine Instruction ManualsunhuynhNo ratings yet
- X Ray Multimeter PracticeDocument8 pagesX Ray Multimeter PracticeKhaeroel AnsoryNo ratings yet
- Bratislava Culenova New City Center ProposalDocument1 pageBratislava Culenova New City Center ProposalAli A KhanNo ratings yet
- 02-Speed Torque CurveDocument14 pages02-Speed Torque CurveFayez Al-ahmadiNo ratings yet
- The Moguls Success PlannerDocument49 pagesThe Moguls Success PlannerjanaleadcollectionNo ratings yet
- OCTF Capacitor Voltage Transformers PDFDocument8 pagesOCTF Capacitor Voltage Transformers PDFRakesh ShinganeNo ratings yet
- U5L5 Activity Guide - The Clicker Game PDFDocument2 pagesU5L5 Activity Guide - The Clicker Game PDFTarun Karthikeyan Student - PantherCreekHSNo ratings yet
- Engineering Minors: School of Computer Science and EngineeringDocument67 pagesEngineering Minors: School of Computer Science and EngineeringPreeti ToppoNo ratings yet
- Email Ids of DGSNDDocument13 pagesEmail Ids of DGSNDCS NarayanaNo ratings yet
- ABB ACS 6000 Tech Catalog RevDDocument171 pagesABB ACS 6000 Tech Catalog RevDmaria_bustelo_2100% (5)
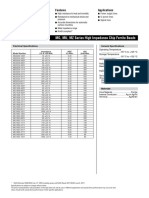
- Chip Ferrite Beads - FUSE - LIDocument6 pagesChip Ferrite Beads - FUSE - LIrouslankhNo ratings yet
- Itil 20200501 Practice Project-ManagementDocument42 pagesItil 20200501 Practice Project-ManagementrafeNo ratings yet
- Iqpacs Radivision DCFDocument42 pagesIqpacs Radivision DCFtretdgdNo ratings yet
- Cool N Comfort Data Sheet RockwoolDocument4 pagesCool N Comfort Data Sheet RockwoolMd Farid AhmedNo ratings yet
- Jilbab 28 PDFDocument1 pageJilbab 28 PDFKang NajiebNo ratings yet
- Deutsche GROVE Kessler Power Train: General Description: Transfer CaseDocument7 pagesDeutsche GROVE Kessler Power Train: General Description: Transfer CaseВиталий РогожинскийNo ratings yet
- State of European Tech 2020Document260 pagesState of European Tech 2020Louise SinghNo ratings yet
- Automatic Bottle Washing Machine NewDocument5 pagesAutomatic Bottle Washing Machine NewSHANU O SNo ratings yet
- D146L Fuel ConsumptionDocument1 pageD146L Fuel ConsumptionWilliam AlvaradoNo ratings yet
- Design of Machine Elements Mid Question PaperDocument1 pageDesign of Machine Elements Mid Question PaperYeswanth Kumar ReddyNo ratings yet
- 303 60 MCQs POM BBA 303 BBA V Dec 2021Document11 pages303 60 MCQs POM BBA 303 BBA V Dec 2021Fentahun Ze WoinambaNo ratings yet
- Configuring A BELKIN Router: Basic Configuration StepsDocument13 pagesConfiguring A BELKIN Router: Basic Configuration StepsAnisha JainNo ratings yet
- Dual Name and Sign Declaration FormDocument2 pagesDual Name and Sign Declaration FormT YeshwathNo ratings yet