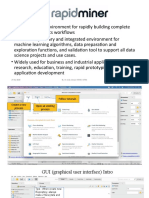
You might also like
- TRIZ Companies Database As of June 23, 2003Document5 pagesTRIZ Companies Database As of June 23, 2003Mohd RiyazNo ratings yet
- Business_Analysis_Canvas_Reference_Guide_1681951775Document1 pageBusiness_Analysis_Canvas_Reference_Guide_1681951775jain_binitmitsNo ratings yet
- Tesda Op Co 01 f11 Heo Moi Basic 400311324Document4 pagesTesda Op Co 01 f11 Heo Moi Basic 400311324Stelito JumaranNo ratings yet
- Theoretical and Practical Analysis On CNN, MTCNN and Caps-Net Base Face Recognition and Detection PDFDocument35 pagesTheoretical and Practical Analysis On CNN, MTCNN and Caps-Net Base Face Recognition and Detection PDFDarshan ShahNo ratings yet
- UCS RM Intro-EtlDocument30 pagesUCS RM Intro-Etlnur ashfaralianaNo ratings yet
- Check List - SEDocument2 pagesCheck List - SEDHANYANo ratings yet
- Khin Than Nyunt PHD (Ce-It) 7: Presented byDocument14 pagesKhin Than Nyunt PHD (Ce-It) 7: Presented byKhin Than NyuntNo ratings yet
- Business AnalyticsDocument6 pagesBusiness AnalyticsHarsh Gandhi100% (1)
- Data Science: DemystifyingDocument73 pagesData Science: DemystifyingSukant Kumar ChoudharyNo ratings yet
- Curriculum Mapping Grade 9: Computer HardwareDocument6 pagesCurriculum Mapping Grade 9: Computer HardwareAndrew C. BrazaNo ratings yet
- D2.5 DICE MethodologyDocument45 pagesD2.5 DICE MethodologygkoutNo ratings yet
- Solving Water Jugs with Cognitive ApproachDocument10 pagesSolving Water Jugs with Cognitive ApproachKhalil AfghanNo ratings yet
- RG-Comtrade PM Coffee Break N33 Managing AI Projects Atanasijevic Srdjan v1.8Document16 pagesRG-Comtrade PM Coffee Break N33 Managing AI Projects Atanasijevic Srdjan v1.8Sanjay PrajapatiNo ratings yet
- Ids PPT and PDFDocument493 pagesIds PPT and PDFygaurav160599No ratings yet
- Vignan’s II Year II Semester Lecture Plan on DBMS, Java, OS and other subjectsDocument24 pagesVignan’s II Year II Semester Lecture Plan on DBMS, Java, OS and other subjectsshyam15287No ratings yet
- Asansol Engineering College: Topic: PPT AssignmentDocument11 pagesAsansol Engineering College: Topic: PPT AssignmentHaimanti SadhuNo ratings yet
- Data Preprocessing For Supervised LearningDocument8 pagesData Preprocessing For Supervised LearningMuzungu Hirwa SylvainNo ratings yet
- NASA Constellation Program Ontologies Ralph Hodgson 20080320Document48 pagesNASA Constellation Program Ontologies Ralph Hodgson 20080320ralphtqNo ratings yet
- Data Scientist: Extracting Insights from DataDocument2 pagesData Scientist: Extracting Insights from DataRiry RizkiyahNo ratings yet
- Md Mahade Hassan Senior Software Engineer ResumeDocument3 pagesMd Mahade Hassan Senior Software Engineer ResumeMd. Bepul HossainNo ratings yet
- Xpresso - Ai:: Enterprise AI Application Lifecycle ManagementDocument2 pagesXpresso - Ai:: Enterprise AI Application Lifecycle Managementdrewen deeeNo ratings yet
- Multi Attribute Front End For Effective: Tradespace Exploration As Space System DesignDocument33 pagesMulti Attribute Front End For Effective: Tradespace Exploration As Space System DesignOdumoduChigozieUzomaNo ratings yet
- Hyperion Learning PathDocument23 pagesHyperion Learning PathAmit SharmaNo ratings yet
- Star Dog AssessmentDocument8 pagesStar Dog Assessment1977amNo ratings yet
- Course Detail Summary: Widyatama University Faculty of Engineering Information System - S1Document8 pagesCourse Detail Summary: Widyatama University Faculty of Engineering Information System - S1Simkabpdg PandeglangNo ratings yet
- Matla Blabs ModifiedDocument49 pagesMatla Blabs ModifiedAfeefabadelNo ratings yet
- Software: Software Application Domain IntoductionDocument1 pageSoftware: Software Application Domain IntoductionSaifulAmirRamaliNo ratings yet
- Job DescriptionDocument1 pageJob Descriptionfungayi tutaiNo ratings yet
- 19earcs010 Akshat TailorDocument8 pages19earcs010 Akshat TailorMahesh SharmaNo ratings yet
- Modern Data Science - Best Practices For Predictive AnalyticsDocument11 pagesModern Data Science - Best Practices For Predictive Analyticscarlos padillaNo ratings yet
- Pertemuan 11: Systems Analysis and Design of A Business Event Driven SystemDocument15 pagesPertemuan 11: Systems Analysis and Design of A Business Event Driven SystemCIndy SaputriNo ratings yet
- Data ScienceDocument14 pagesData Sciencescientist01234No ratings yet
- ITC 2023 TRIZ Generative AI Tanasak PheunghuaDocument30 pagesITC 2023 TRIZ Generative AI Tanasak PheunghuawuttichaispNo ratings yet
- Exploring the Data Science ProcessDocument47 pagesExploring the Data Science ProcessTareq HassanNo ratings yet
- Jr. Data Scientist Job DescriptionDocument2 pagesJr. Data Scientist Job DescriptionNazmul Alam DiptuNo ratings yet
- Dashpreet Singh ResumeDocument1 pageDashpreet Singh Resumebencekatarina4No ratings yet
- Akselerasi Transformasi HC BUMN at ESDM 10022021Document36 pagesAkselerasi Transformasi HC BUMN at ESDM 10022021bagus kuncoro hadi100% (1)
- Analysis within the Systems Development Life-Cycle: Book 3 Activity Analysis — The DeliverablesFrom EverandAnalysis within the Systems Development Life-Cycle: Book 3 Activity Analysis — The DeliverablesNo ratings yet
- 1 or IntroDocument14 pages1 or IntroSimply AmazingNo ratings yet
- Anuja Mesh DocumentDocument4 pagesAnuja Mesh DocumentPallaviPansareNo ratings yet
- Knowledge Discovery Data Mining - SyllabusDocument6 pagesKnowledge Discovery Data Mining - SyllabusVishal AnandNo ratings yet
- Lecture 4Document37 pagesLecture 4weetan studioNo ratings yet
- Artificial Intelligence in KM (1) - Tagged PDFDocument53 pagesArtificial Intelligence in KM (1) - Tagged PDFlavanya.channelingNo ratings yet
- Introduction To Data Science: Week 1 Unit 1Document69 pagesIntroduction To Data Science: Week 1 Unit 1qwerty_qwerty_2009No ratings yet
- OpenSAP Ds1 Week 1 Unit 1 INTRODS PresentationDocument16 pagesOpenSAP Ds1 Week 1 Unit 1 INTRODS Presentationश्रीकांत शरमाNo ratings yet
- Process Mapping in PracticeDocument21 pagesProcess Mapping in Practiceokamo100% (2)
- Study and Review On Developed Data Mining Systems: Preeti, Ms. Preethi Jose DollyDocument2 pagesStudy and Review On Developed Data Mining Systems: Preeti, Ms. Preethi Jose DollyerpublicationNo ratings yet
- de Lecture 1 Intro To Data EnggDocument12 pagesde Lecture 1 Intro To Data Enggmb.doumiNo ratings yet
- Edureka Data Science EbookDocument22 pagesEdureka Data Science EbookHemant Tejwani100% (2)
- A Survey On Deep Learning Techniques For Image and Video Semantic SegmentationDocument68 pagesA Survey On Deep Learning Techniques For Image and Video Semantic SegmentationMufqi Ananda RahmadiNo ratings yet
- Data Structures and AlgorithmsDocument3 pagesData Structures and Algorithmsu chaitanyaNo ratings yet
- System Design: LIVE SessionDocument15 pagesSystem Design: LIVE SessionParminder SinghNo ratings yet
- MS EXCEL ADVANCEDDocument2 pagesMS EXCEL ADVANCEDyogesh patilNo ratings yet
- WS1UNRDocument13 pagesWS1UNRAbiy MulugetaNo ratings yet
- Big Data AnalyticsDocument31 pagesBig Data AnalyticsTushar SawantNo ratings yet
- Course Structure & Syllabus of Bachelor of Technology (B.Tech)Document3 pagesCourse Structure & Syllabus of Bachelor of Technology (B.Tech)anupNo ratings yet
- Tips For RecruitersDocument38 pagesTips For Recruitersapi-3731247No ratings yet
- Open Reusable and Configurable Multi-Agent SystemsDocument80 pagesOpen Reusable and Configurable Multi-Agent SystemsMario Gómez MartínezNo ratings yet
- Analysis within the Systems Development Life-Cycle: Data Analysis — The DeliverablesFrom EverandAnalysis within the Systems Development Life-Cycle: Data Analysis — The DeliverablesNo ratings yet
- Performance Testing: An ISTQB Certified Tester Foundation Level Specialist Certification ReviewFrom EverandPerformance Testing: An ISTQB Certified Tester Foundation Level Specialist Certification ReviewNo ratings yet
- Excel Random Data AnalysisDocument7 pagesExcel Random Data AnalysisVeken BakradNo ratings yet
- Automata TheoryDocument57 pagesAutomata Theorysir ABDNo ratings yet
- VSCC - PowerFactory - Benchmark - v1 - Part IIDocument15 pagesVSCC - PowerFactory - Benchmark - v1 - Part IIbenjaxxNo ratings yet
- Broyce Product Information V2 - 0 PDFDocument164 pagesBroyce Product Information V2 - 0 PDFcallmenuandagmail.comNo ratings yet
- Procom Interview QuestionsDocument10 pagesProcom Interview QuestionsMuhammad Izaan SohailNo ratings yet
- A2IOT2020 Paper 5Document6 pagesA2IOT2020 Paper 5Ettaoufik AbdelazizNo ratings yet
- 2.1 Setting Up Your Cold Email MachineDocument6 pages2.1 Setting Up Your Cold Email MachineSpam KhanNo ratings yet
- SN e Reference PDFDocument1,269 pagesSN e Reference PDFPMNo ratings yet
- COA Course MaterialDocument390 pagesCOA Course Materialjiiiiilab100% (1)
- Ecdis MateriDocument10 pagesEcdis Materistmpl munduNo ratings yet
- Panasonic TX-65DX900E LED TelevisionDocument372 pagesPanasonic TX-65DX900E LED TelevisionsoteliNo ratings yet
- Huawei-B535-232 Manual - ESDocument88 pagesHuawei-B535-232 Manual - ESAlbertNo ratings yet
- 3 Hours / 70 Marks: Seat NoDocument3 pages3 Hours / 70 Marks: Seat NokumavatvedantiNo ratings yet
- Requirements FullDocument6 pagesRequirements FullAnthony FloydNo ratings yet
- XINJE XD Series MODBUS TCP IPDocument3 pagesXINJE XD Series MODBUS TCP IPMaicon ZagonelNo ratings yet
- Attention: Sharad JonesDocument25 pagesAttention: Sharad JonesDavid GuevaraNo ratings yet
- Pendeteksi Volume Air Secara Otomatis Menggunakan FuzzyDocument6 pagesPendeteksi Volume Air Secara Otomatis Menggunakan Fuzzymuhamad tazalulNo ratings yet
- 0786 Linux FundamentalsDocument6 pages0786 Linux FundamentalsBalaPothinaNo ratings yet
- Esq Elec Completos Tgox - v3 - NXDocument40 pagesEsq Elec Completos Tgox - v3 - NXJavier ZapatNo ratings yet
- Compal Confidential QIWG7 DIS M/B Schematics DocumentDocument5 pagesCompal Confidential QIWG7 DIS M/B Schematics DocumentКирилл ГулякевичNo ratings yet
- IP Issues & CyberspaceDocument13 pagesIP Issues & Cyberspace1234tempoNo ratings yet
- DS-2DE4225IW-DE (E) 2MP 25× Network IR Speed Dome: Key FeaturesDocument6 pagesDS-2DE4225IW-DE (E) 2MP 25× Network IR Speed Dome: Key FeaturesKarsim BoimNo ratings yet
- Inventory list of electronic equipment and accessoriesDocument2 pagesInventory list of electronic equipment and accessoriessmuralirajNo ratings yet
- Spiral ModelDocument12 pagesSpiral ModelVineethNo ratings yet
- Array, Classes and ObjectsDocument31 pagesArray, Classes and Objectsrina mahureNo ratings yet
- Cashtech WPDocument19 pagesCashtech WPZicoNo ratings yet
- Create SiteDocument21 pagesCreate SiteMENANI ZineddineNo ratings yet
- Itns Year 1 T3-Module Dip-01001 Network 11 Introduction To Networks (Version 7.00) - Modules 11 - 13 Ip Addressing Answer All QuestionsDocument25 pagesItns Year 1 T3-Module Dip-01001 Network 11 Introduction To Networks (Version 7.00) - Modules 11 - 13 Ip Addressing Answer All Questionskwasi williamsNo ratings yet
- Specification Sheet - Nova (English)Document2 pagesSpecification Sheet - Nova (English)RonNo ratings yet
- Title: Password Security System: I. ObjectiveDocument3 pagesTitle: Password Security System: I. ObjectiveRam RajaNo ratings yet