You might also like
- SM TcsDocument4 pagesSM TcsKrishnamurthy BNo ratings yet
- DatabaseDocument39 pagesDatabaseBikash KandelNo ratings yet
- My ResumeDocument2 pagesMy ResumeShubham BoradeNo ratings yet
- Integration+Guide+ +OP+2021+Document48 pagesIntegration+Guide+ +OP+2021+Ahmed OthmanNo ratings yet
- Data Science Job Guarantee ProgramDocument28 pagesData Science Job Guarantee ProgramNitesh PandeyNo ratings yet
- Nagarjuna PowerBi BangaloreDocument2 pagesNagarjuna PowerBi BangaloresrilekhaNo ratings yet
- ELV Draftsman 2023Document3 pagesELV Draftsman 2023Praveen RajNo ratings yet
- Case Study On Building Data Warehouse/Data MartDocument6 pagesCase Study On Building Data Warehouse/Data MartCandida NoronhaNo ratings yet
- BI Tool InstallationDocument58 pagesBI Tool Installationapi-3745656No ratings yet
- HTML Color Codes PDFDocument12 pagesHTML Color Codes PDFAungKyawOoNo ratings yet
- Finance & Risk Analytics: Project ReportDocument16 pagesFinance & Risk Analytics: Project ReportsharwanidasNo ratings yet
- Mercer Et Al 2020 Automated Written Expression CBMDocument23 pagesMercer Et Al 2020 Automated Written Expression CBMManuela Lloreda ArangoNo ratings yet
- LP2 Junit ReportDocument20 pagesLP2 Junit Reportkirti reddy0% (4)
- InstallationAndConfigurationGuide 18.4CU2 Eprescribing PDFDocument42 pagesInstallationAndConfigurationGuide 18.4CU2 Eprescribing PDFvikiraj suryawanshiNo ratings yet
- SQL Tutorial 1Document107 pagesSQL Tutorial 1srinath nandamNo ratings yet
- Software Engineering BootcampDocument17 pagesSoftware Engineering Bootcampsuvrodeep duttaNo ratings yet
- AEM Forms AdministrationDocument116 pagesAEM Forms AdministrationCamilo GutierrezNo ratings yet
- Rpi RGB Led Matrix - WordDocument95 pagesRpi RGB Led Matrix - WordAbhiNo ratings yet
- Ravens Adaptive ManualDocument38 pagesRavens Adaptive ManualMa. Zerrise MarcillaNo ratings yet
- Permissions Poster SQL Server VNext and SQLDBDocument1 pagePermissions Poster SQL Server VNext and SQLDBandrey75sNo ratings yet
- Tosca Technical Release Notes 14.2Document4 pagesTosca Technical Release Notes 14.2Mansa ChNo ratings yet
- Design Notation and SpecificationDocument12 pagesDesign Notation and Specificationزین علیNo ratings yet
- Data Cleaning and Analysis of World Population DatasetDocument12 pagesData Cleaning and Analysis of World Population DatasetQuang VuNo ratings yet
- Global Vehicle Sales PGM Demand Hydrogen Aug 2020Document13 pagesGlobal Vehicle Sales PGM Demand Hydrogen Aug 2020ResearchtimeNo ratings yet
- Statistics Interview 02Document30 pagesStatistics Interview 02Sudharshan Venkatesh100% (1)
- CIO Tech Priorities 2016Document6 pagesCIO Tech Priorities 2016IDG_WorldNo ratings yet
- ML Quiz 2Document8 pagesML Quiz 2mr IndiaNo ratings yet
- Data Analyst SQL Tableau in San Francisco Bay CA Resume Rod CyrusDocument2 pagesData Analyst SQL Tableau in San Francisco Bay CA Resume Rod CyrusRod CyrusNo ratings yet
- Rahul SharmaDocument2 pagesRahul Sharmarahul triguneNo ratings yet
- Tableau BlueprintDocument205 pagesTableau BlueprintRahmat HidayatNo ratings yet
- DAX Functions - Quick GuideDAXDocument17 pagesDAX Functions - Quick GuideDAXErAchyutNamdeo100% (1)
- Logistics Sector Report TemplateDocument168 pagesLogistics Sector Report TemplateAbdiweli Ibrahim MahamedNo ratings yet
- mt541 MT543Document39 pagesmt541 MT543DR. OMID R TabrizianNo ratings yet
- Presentation of DataDocument25 pagesPresentation of DataKelliata BenjaminNo ratings yet
- SMDM Project ReportDocument27 pagesSMDM Project ReportGirish ChadhaNo ratings yet
- Digital Notes on Brief History and Methodology of Operations ResearchDocument30 pagesDigital Notes on Brief History and Methodology of Operations ResearchJoshna SambaNo ratings yet
- BIJ Data Analysis ReportDocument18 pagesBIJ Data Analysis Reportlevel 10No ratings yet
- NetBackup9.x EEB GuideDocument54 pagesNetBackup9.x EEB Guide黃國峯No ratings yet
- Data Visualization Using Tableau (WEEK-1)Document9 pagesData Visualization Using Tableau (WEEK-1)Balaji SNo ratings yet
- Pentaho Data Integration (PDI) TutorialDocument33 pagesPentaho Data Integration (PDI) TutorialStevanus ChristianNo ratings yet
- Ref. Data AXADocument3 pagesRef. Data AXAkonupoddarNo ratings yet
- DATA MINING LAB MANUALDocument74 pagesDATA MINING LAB MANUALAakashNo ratings yet
- Pega 60Q 1Document24 pagesPega 60Q 1BEENONo ratings yet
- Kailash ML ReportDocument51 pagesKailash ML ReportKailash the donNo ratings yet
- Use Case Specification: Prepared By: Date: (AD) Reviewed By: Date: (Architect/AD)Document6 pagesUse Case Specification: Prepared By: Date: (AD) Reviewed By: Date: (Architect/AD)MLastTryNo ratings yet
- AX2012 Financials L10 AccountsPayable LabsDocument73 pagesAX2012 Financials L10 AccountsPayable LabsSky Boon Kok LeongNo ratings yet
- Big Data PracticeDocument93 pagesBig Data Practicesrinivas75kNo ratings yet
- Time Series Forecasting FundamentalsDocument37 pagesTime Series Forecasting Fundamentalsravi mNo ratings yet
- SQL Relational Model and Database ConceptsDocument4 pagesSQL Relational Model and Database ConceptskevinazhuNo ratings yet
- Sarthi Coaching Pune MPSC Cet 2020 GuidelinesDocument10 pagesSarthi Coaching Pune MPSC Cet 2020 GuidelinesRaviNo ratings yet
- The Shared Assessments ProgramDocument51 pagesThe Shared Assessments ProgramShane FullerNo ratings yet
- Ds Roadmap 2Document9 pagesDs Roadmap 2zxczczxvcNo ratings yet
- Mobile Gps-Augmented Reality System For Tour Guide (Case Study - Kediri City)Document6 pagesMobile Gps-Augmented Reality System For Tour Guide (Case Study - Kediri City)alfisyahrfm3No ratings yet
- ZohoPartnerSummit17 Chennai AnalyticsDocument32 pagesZohoPartnerSummit17 Chennai AnalyticsPamela ChewNo ratings yet
- Rajat Agrawal ReportDocument77 pagesRajat Agrawal ReportVinayak GuptaNo ratings yet
- Data GripDocument132 pagesData Gripstorm9331No ratings yet
- MM 910 AdministratorGuide enDocument214 pagesMM 910 AdministratorGuide enSPNo ratings yet
- Chapter 2 - Intro. To Data Sciences (Autosaved)Document25 pagesChapter 2 - Intro. To Data Sciences (Autosaved)Daniel DamessaNo ratings yet
- General: Just A (Very Incomplete) List of R FunctionsDocument3 pagesGeneral: Just A (Very Incomplete) List of R Functionsswapnil palNo ratings yet
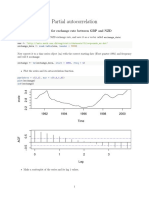
- Partial ACF GBP-NZDDocument6 pagesPartial ACF GBP-NZDSieben DoppeltNo ratings yet
- Stochastic processes I concepts and modelsDocument23 pagesStochastic processes I concepts and modelsSieben DoppeltNo ratings yet
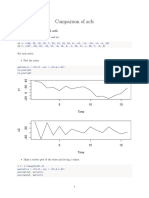
- Compare Acf-SolutionDocument3 pagesCompare Acf-SolutionSieben DoppeltNo ratings yet
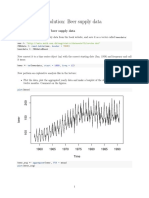
- Beer-Solution R StudioDocument4 pagesBeer-Solution R StudioSieben DoppeltNo ratings yet
- CFD Theory RANSDocument23 pagesCFD Theory RANSSieben DoppeltNo ratings yet
- MannDocument21 pagesMannNeagoeNo ratings yet
- Development of a Short Form of the Attitudes Toward Mathematics Inventory (ATMIDocument20 pagesDevelopment of a Short Form of the Attitudes Toward Mathematics Inventory (ATMImaleckisaleNo ratings yet
- Lesson 13 Activity 16 BUTALIDQUEENIEDocument4 pagesLesson 13 Activity 16 BUTALIDQUEENIEQUEENIE BUTALIDNo ratings yet
- IA Math Studies Example Ia 18 Out of 20Document6 pagesIA Math Studies Example Ia 18 Out of 20PABLO GOMEZ (Student)No ratings yet
- Topics in Time Series EconometricsDocument157 pagesTopics in Time Series EconometricsDrDeepti Ji67% (3)
- ExamplesDocument2 pagesExamplessum100% (1)
- The Insignificance of Null Hypothesis Significance TestingDocument30 pagesThe Insignificance of Null Hypothesis Significance TestingLida Natalia Gomez SolanoNo ratings yet
- Advanced Time Series and Forecasting Lecture 5Document100 pagesAdvanced Time Series and Forecasting Lecture 5UranUsNo ratings yet
- Kruskal Wallis or H-TestDocument11 pagesKruskal Wallis or H-TestHello HiNo ratings yet
- Unit 6Document60 pagesUnit 6UsmanNo ratings yet
- Estimating A Demand Function - It's About TimeDocument13 pagesEstimating A Demand Function - It's About TimeSebastián RojasNo ratings yet
- Hypothesis Testing ExercisesDocument7 pagesHypothesis Testing ExercisesNguyen Hoai PhuongNo ratings yet
- Cola AnswersDocument3 pagesCola AnswersFatimaNo ratings yet
- 4.1-4.3 Form B QuizDocument2 pages4.1-4.3 Form B QuizblessingtraciNo ratings yet
- Stata Training CourseDocument43 pagesStata Training CourseAshish KumarNo ratings yet
- STA 212 Formula Sheet: Normal DistributionDocument2 pagesSTA 212 Formula Sheet: Normal DistributioncourseNo ratings yet
- Exam Review Package Answers 2013Document9 pagesExam Review Package Answers 2013api-2598097460% (1)
- LECTURE Notes On Design of ExperimentsDocument31 pagesLECTURE Notes On Design of Experimentsvignanaraj88% (8)
- Measures of Dispersion ExplainedDocument28 pagesMeasures of Dispersion ExplainedPrincess Elaisa AbelloNo ratings yet
- Data Scientist Interview Questions and Answers PDFDocument37 pagesData Scientist Interview Questions and Answers PDFBimal ChandNo ratings yet
- Don Mariano Marcos Memorial State UniversityDocument28 pagesDon Mariano Marcos Memorial State UniversityMathew DegamoNo ratings yet
- Prelim Results Ef. Blanqueante 17-1015 Prod 17.0363 IngDocument3 pagesPrelim Results Ef. Blanqueante 17-1015 Prod 17.0363 IngfitboxxNo ratings yet
- NAVEED StatisticsDocument4 pagesNAVEED Statisticsyusha habibNo ratings yet
- Stats C PDFDocument5 pagesStats C PDFMaria SimõesNo ratings yet
- Solomon S2 E MSDocument4 pagesSolomon S2 E MSArjun MohindraNo ratings yet
- Psych MethodsDocument15 pagesPsych MethodsRahulNo ratings yet
- The Friedman FR Test For Randomized Block DesignDocument3 pagesThe Friedman FR Test For Randomized Block DesignCynthia Gemino BurgosNo ratings yet
- Normal Probability Distributions: 6-1 Review and PreviewDocument269 pagesNormal Probability Distributions: 6-1 Review and PreviewLorelei UrkelNo ratings yet
- Descriptive StatisticsDocument3 pagesDescriptive Statisticscharlotte899No ratings yet
- Biostatistics Workbook Aug07-1Document247 pagesBiostatistics Workbook Aug07-1WaElinChawiNo ratings yet
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Assessment Prep for Common Core Mathematics, Grade 6From EverandAssessment Prep for Common Core Mathematics, Grade 6Rating: 5 out of 5 stars5/5 (1)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)