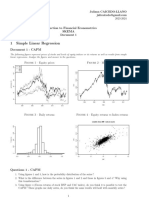
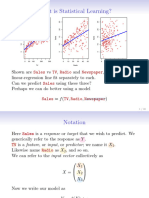
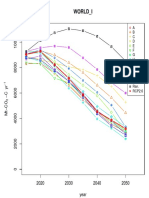
You might also like
- Document 1 - CAPM and Hedge RatioDocument2 pagesDocument 1 - CAPM and Hedge Ratiojovana.mlnvNo ratings yet
- R Programming: 7.1 R, Matlab, and PythonDocument24 pagesR Programming: 7.1 R, Matlab, and PythonbfilinNo ratings yet
- About Us Sustainability Report and Policy Sustainability Report 2010 en PDFDocument98 pagesAbout Us Sustainability Report and Policy Sustainability Report 2010 en PDFandreea stamanteNo ratings yet
- Lectures Machine LearningDocument205 pagesLectures Machine LearningGuilherme MartheNo ratings yet
- Fitting distributions and comparing fits with R's fitdistrplus packageDocument34 pagesFitting distributions and comparing fits with R's fitdistrplus packageElíGomaraGilNo ratings yet
- Task 3 - JPMDocument1 pageTask 3 - JPMPratham sadanaNo ratings yet
- SLR NotesDocument96 pagesSLR NotesRafi DawarNo ratings yet
- C2 Statistical LearningDocument37 pagesC2 Statistical LearningLluïsa GualNo ratings yet
- Player Aid - Ark SheetDocument1 pagePlayer Aid - Ark SheetRichard HarrisonNo ratings yet
- STAT1400 2022 1st Week4-Lecture 7Document19 pagesSTAT1400 2022 1st Week4-Lecture 7Sameer GuptaNo ratings yet
- Sim RDocument6 pagesSim Rsipho23No ratings yet
- Agile Experience Affects Adoption and Use of PracticesDocument17 pagesAgile Experience Affects Adoption and Use of PracticesHaja ShareefNo ratings yet
- Ch Multiple Linear Regression Everitt HothornDocument12 pagesCh Multiple Linear Regression Everitt HothornRuan CerqueiraNo ratings yet
- Foo PDFDocument7 pagesFoo PDFfodsffNo ratings yet
- Bayesian Structural Time Series ModelsDocument100 pagesBayesian Structural Time Series ModelsClaudyaNo ratings yet
- Find multiple roots and Taylor coefficients of a functionDocument16 pagesFind multiple roots and Taylor coefficients of a functionmgrubisicNo ratings yet
- Horizontal Beam Engine with Centrifugal PumpDocument1 pageHorizontal Beam Engine with Centrifugal PumpQTG channelNo ratings yet
- Vdocuments - MX Rotalign Ultra System ManualDocument31 pagesVdocuments - MX Rotalign Ultra System ManualTanNo ratings yet
- Mock Midterm Test 1: Exercise Exercise ExerciseDocument2 pagesMock Midterm Test 1: Exercise Exercise ExercisePETERNo ratings yet
- Italian Air Quality DataDocument7 pagesItalian Air Quality Databenn yassNo ratings yet
- KL22 - 20 21 June High Impact Audit ReportingDocument7 pagesKL22 - 20 21 June High Impact Audit ReportingramasockalingamNo ratings yet
- FANUC ROBOT - (CR 4ia 7ia 7iAL 14iAL)Document2 pagesFANUC ROBOT - (CR 4ia 7ia 7iAL 14iAL)R Dinansyah PrawirasapoetraNo ratings yet
- Manage Ark Development ProgressDocument2 pagesManage Ark Development ProgressMatt GullettNo ratings yet
- Calcula-Dibuja 4Document23 pagesCalcula-Dibuja 4ENRIQUE CRESPONo ratings yet
- Peerj Preprints 3190Document25 pagesPeerj Preprints 3190Anonymous biYLgFqhThNo ratings yet
- Transformations and Misspecification of Econometric Models: August 27, 2014Document19 pagesTransformations and Misspecification of Econometric Models: August 27, 2014Maria RoaNo ratings yet
- Management of InnovationDocument12 pagesManagement of InnovationBezawit MekNo ratings yet
- Ark SheetDocument2 pagesArk SheetSarfantNo ratings yet
- Development Levels The Ark: Food Supply Culture Technology WarfareDocument2 pagesDevelopment Levels The Ark: Food Supply Culture Technology WarfareSarfantNo ratings yet
- Filtracion Lubricantes NuevosDocument100 pagesFiltracion Lubricantes NuevosHernan Andres GarciaNo ratings yet
- Week2 StatisticalLearningDocument46 pagesWeek2 StatisticalLearningMuntaz MuntazNo ratings yet
- A Hands-On Guide To Google DataDocument25 pagesA Hands-On Guide To Google Datavikky90No ratings yet
- Displaying Model Plots in Lattice PlotsDocument16 pagesDisplaying Model Plots in Lattice PlotsAriake SwyceNo ratings yet
- Práctica 4.2Document1 pagePráctica 4.2Andrey Vargas MoralesNo ratings yet
- Saad and Zohaib FYPDocument5 pagesSaad and Zohaib FYPAseel & BirdsNo ratings yet
- MYZ Ark Sheet Printer Friendly PDFDocument1 pageMYZ Ark Sheet Printer Friendly PDFMasis 'Ara' ShahbaziansNo ratings yet
- Lect6 PDFDocument22 pagesLect6 PDF杜晓晚No ratings yet
- Multivariate MethodsDocument14 pagesMultivariate MethodsWERU JOAN NYOKABINo ratings yet
- 2020 322 Moesm6 EsmDocument2 pages2020 322 Moesm6 EsmkjhgfghjkNo ratings yet
- Grommet 6.0mm IDDocument1 pageGrommet 6.0mm IDShrikant DeshmukhNo ratings yet
- Zhejiang Taotao VIN decoding guideDocument4 pagesZhejiang Taotao VIN decoding guideAndroid User100% (1)
- D105236677 5491461259308861 SchedulescDocument3 pagesD105236677 5491461259308861 SchedulescGowtham VaddadiNo ratings yet
- Gambar Micrometer StandDocument4 pagesGambar Micrometer Standcakim.anhNo ratings yet
- Estimating Change Points in Beer-Lambert Law Using Determination CoefficientsDocument14 pagesEstimating Change Points in Beer-Lambert Law Using Determination CoefficientsNunee AyuNo ratings yet
- ES Randers Exercise 2017Document79 pagesES Randers Exercise 2017JuanJerezMonsalvesNo ratings yet
- Explore Historic Fort Mackinac and Its 23 SitesDocument1 pageExplore Historic Fort Mackinac and Its 23 SitesJackson HarmerNo ratings yet
- CHAPTER 13. Time Series Models: Further Topics: Economic Time Series Often Exhibit Strong Seasonal VariationDocument20 pagesCHAPTER 13. Time Series Models: Further Topics: Economic Time Series Often Exhibit Strong Seasonal VariationWOONGCHAE YOONo ratings yet
- TransformationsDocument21 pagesTransformationslemuel sardualNo ratings yet
- Learn Time Series Analysis FundamentalsDocument20 pagesLearn Time Series Analysis Fundamentalsenrique gonzalez duranNo ratings yet
- In MaDocument1 pageIn ManguyenxuanlinhNo ratings yet
- PT PELAYARAN NASIONAL BINA BUANA RAYA Tbk 2015 ANNUAL REPORTDocument67 pagesPT PELAYARAN NASIONAL BINA BUANA RAYA Tbk 2015 ANNUAL REPORTBang SuriaNo ratings yet
- OM - Kubota M100GX, M110GX, M126GX, M135GX PDFDocument178 pagesOM - Kubota M100GX, M110GX, M126GX, M135GX PDFtgit28No ratings yet
- My PlotDocument1 pageMy Plotjmoxey6577No ratings yet
- Roc FP Elixir TalkDocument47 pagesRoc FP Elixir TalkJames DeanNo ratings yet
- Inspection Report Dimensions CheckDocument1 pageInspection Report Dimensions CheckGhiță SfîraNo ratings yet
- ISOMDocument5 pagesISOMAntaraNo ratings yet
- Engine Control System OverviewDocument4 pagesEngine Control System Overviewaritw541214No ratings yet
- S2 S5e G305 - Main - SCH - V2.1 - 20130705Document13 pagesS2 S5e G305 - Main - SCH - V2.1 - 20130705Riza VirsadaNo ratings yet
- Body of RegulatorDocument1 pageBody of RegulatorDian MelianaNo ratings yet
- Fill Your Glass With Gold-When It's Half-Full or Even Completely ShatteredFrom EverandFill Your Glass With Gold-When It's Half-Full or Even Completely ShatteredNo ratings yet
- On the Complexity of Requirements Engineering for Decision Support Systems The CID Case StudyDocument39 pagesOn the Complexity of Requirements Engineering for Decision Support Systems The CID Case StudyefiolNo ratings yet
- Analysis of Requirement Engineering Processes, Tools, Techniques and MethodologiesDocument9 pagesAnalysis of Requirement Engineering Processes, Tools, Techniques and MethodologiesefiolNo ratings yet
- Package Cellranger': R Topics DocumentedDocument21 pagesPackage Cellranger': R Topics DocumentedefiolNo ratings yet
- Copernicus in The Cultural Deb - Omodeo, Pietro Daniel - 6029Document448 pagesCopernicus in The Cultural Deb - Omodeo, Pietro Daniel - 6029paoloNo ratings yet
- H.R. Maturana, F.J. Varela Autopoiesis and Cognition The Realization of The Living 1980Document87 pagesH.R. Maturana, F.J. Varela Autopoiesis and Cognition The Realization of The Living 1980Giannis NinosNo ratings yet
- Requirement Engineering and the Role of Design ThinkingDocument7 pagesRequirement Engineering and the Role of Design ThinkingefiolNo ratings yet
- SEG3101-ch1-2 - Basics - The RE ProcessDocument37 pagesSEG3101-ch1-2 - Basics - The RE ProcesskashafNo ratings yet
- Requirement EngineringDocument44 pagesRequirement EngineringMunthitra ThadthapongNo ratings yet
- Using R For Data Analysis and Graphics Introduction, Code and CommentaryDocument96 pagesUsing R For Data Analysis and Graphics Introduction, Code and Commentaryjto777No ratings yet
- Statistical Computing and GraphicsDocument179 pagesStatistical Computing and GraphicsefiolNo ratings yet
- Shipunov Visual StatisticsDocument429 pagesShipunov Visual StatisticsZen KyoNo ratings yet
- R IntsDocument69 pagesR IntsMaster testNo ratings yet
- Seefeld-Statistics Using R With Biological Examples PDFDocument325 pagesSeefeld-Statistics Using R With Biological Examples PDFManuel LoGaNo ratings yet
- Rprogramming PDFDocument182 pagesRprogramming PDFSaiSagireddyNo ratings yet
- R Reference CardDocument1 pageR Reference CardefiolNo ratings yet
- R Notes For ProfessionalsDocument475 pagesR Notes For Professionalsmick100% (1)
- Writing R ExtensionsDocument201 pagesWriting R ExtensionsMaster testNo ratings yet
- SAS BigData FinalDocument37 pagesSAS BigData FinalDevika RadjkoemarNo ratings yet
- Farnsworth Grant V.-Econometrics in RDocument50 pagesFarnsworth Grant V.-Econometrics in RRalf SanderNo ratings yet
- R For Windows UsersDocument35 pagesR For Windows UsersefiolNo ratings yet
- R LangDocument60 pagesR Langasoni98No ratings yet
- R For BiologistsDocument35 pagesR For BiologistsJoão Paulo MedeirosNo ratings yet
- R IntroductionDocument141 pagesR IntroductionChristopher PaulNo ratings yet
- Krijnen IntroBioInfStatisticsDocument278 pagesKrijnen IntroBioInfStatisticsTianbao LuoNo ratings yet
- Brainstorm - : Your Text HereDocument2 pagesBrainstorm - : Your Text HereefiolNo ratings yet
- Epicalc BookDocument328 pagesEpicalc BookLuke MceachronNo ratings yet
- Evaluating The Design of The R LanguageDocument28 pagesEvaluating The Design of The R LanguageTehzeeb FaizanNo ratings yet
- De Jonge+van Der Loo-Introduction To Data Cleaning With RDocument53 pagesDe Jonge+van Der Loo-Introduction To Data Cleaning With RTuanNguyenNo ratings yet
- Brainstorm - : Your Text HereDocument2 pagesBrainstorm - : Your Text HereefiolNo ratings yet
- Persian Colloquial 1Document125 pagesPersian Colloquial 1pannunfirm100% (1)
- Gagnes Conditions of Learning TheoryDocument6 pagesGagnes Conditions of Learning TheoryDorothy Joy Nadela100% (1)
- Exp LG 032754 - 0Document1 pageExp LG 032754 - 0Aritra DasguptaNo ratings yet
- B2B Starter User GuideDocument31 pagesB2B Starter User GuideDecio FerreiraNo ratings yet
- Al-Jallad. 2019. Safaitic The Semitic La PDFDocument25 pagesAl-Jallad. 2019. Safaitic The Semitic La PDFFadlNo ratings yet
- Glossary-O of Magic TermsDocument44 pagesGlossary-O of Magic TermsReppin SetsNo ratings yet
- Configuration A Profibus-DP Node Using Step7 and WAGO-I/O ComponentsDocument18 pagesConfiguration A Profibus-DP Node Using Step7 and WAGO-I/O ComponentsJose LunaNo ratings yet
- What's in A Name: Walker Percy On The Phenomenon of LanguageDocument11 pagesWhat's in A Name: Walker Percy On The Phenomenon of LanguageJoseph L. GrabowskiNo ratings yet
- Bridge Course Math.Document17 pagesBridge Course Math.Sankalp DasNo ratings yet
- The Interconnected Ḥawāmīm SurahsDocument39 pagesThe Interconnected Ḥawāmīm SurahsMyriam GouiaaNo ratings yet
- Rainbow of Translation: A Semiotic Approach To Intercultural Transfer of Colors in Children's Picture BooksDocument19 pagesRainbow of Translation: A Semiotic Approach To Intercultural Transfer of Colors in Children's Picture BooksMony AlmalechNo ratings yet
- C Programming Practical ExercisesDocument6 pagesC Programming Practical ExercisesAdvance TechnologyNo ratings yet
- USB232-485× Operation InstructionsDocument17 pagesUSB232-485× Operation InstructionsDamijan SrdočNo ratings yet
- English Proverbs PDFDocument3 pagesEnglish Proverbs PDFAlex JohnsonNo ratings yet
- Closing ReflectionDocument2 pagesClosing Reflectionapi-317272663No ratings yet
- Horen-Lenavi 1.32 VersionDocument81 pagesHoren-Lenavi 1.32 VersionVadym PopovNo ratings yet
- Research-Based Teaching and Student-Centered LearningDocument2 pagesResearch-Based Teaching and Student-Centered LearningNova VillonesNo ratings yet
- EE124 Sessional IDocument2 pagesEE124 Sessional IkishorebabNo ratings yet
- (Kaspersky) Kaspersky Linux Mail SecurityDocument157 pages(Kaspersky) Kaspersky Linux Mail Securityhiehie272No ratings yet
- EE371-Microprocessor Systems Fall2014Document2 pagesEE371-Microprocessor Systems Fall2014Cepheid FaarjanaNo ratings yet
- Dalai Lama Teaches on Four Seals and Path to LiberationDocument17 pagesDalai Lama Teaches on Four Seals and Path to LiberationdimeotanNo ratings yet
- Biography Writing PowerpointDocument7 pagesBiography Writing PowerpointSoniaNo ratings yet
- BRICKS READING 150 Bricks Reading 150 1.ocr - BakDocument141 pagesBRICKS READING 150 Bricks Reading 150 1.ocr - BakJackie Francois100% (2)
- Pre-Quiz - Attempt ReviewDocument4 pagesPre-Quiz - Attempt ReviewVinesh DaraNo ratings yet
- Present Simple Present Continuous - Leisure Time Activities - Consolidation WorksheetDocument4 pagesPresent Simple Present Continuous - Leisure Time Activities - Consolidation WorksheetblogswebquestsNo ratings yet
- Reply To Sri Vidyamanya TirthaDocument17 pagesReply To Sri Vidyamanya Tirthaanishkrishnannayar0% (1)
- Harvard Referencing Guideline SBL ProgrammesDocument28 pagesHarvard Referencing Guideline SBL ProgrammesSaChibvuri JeremiahNo ratings yet
- SMC6000 HMDocument33 pagesSMC6000 HMNo KidderNo ratings yet
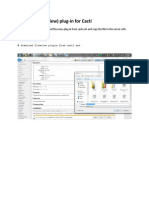
- Flowview Plugin For CactiDocument7 pagesFlowview Plugin For CactiJh0n Fredy H100% (2)
- Command Quick Guide R12 - 2009Document48 pagesCommand Quick Guide R12 - 2009Marcelito MorongNo ratings yet