You might also like
- PLC Controls with Structured Text (ST): IEC 61131-3 and best practice ST programmingFrom EverandPLC Controls with Structured Text (ST): IEC 61131-3 and best practice ST programmingRating: 4 out of 5 stars4/5 (11)
- QuestionsDocument10 pagesQuestionsRizzy Shinigami50% (2)
- Assembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageFrom EverandAssembly Programming:Simple, Short, And Straightforward Way Of Learning Assembly LanguageRating: 5 out of 5 stars5/5 (1)
- Edit Check - A Critical Step To Ensure The Data Quality During Clinical TrialsDocument3 pagesEdit Check - A Critical Step To Ensure The Data Quality During Clinical Trialsvinay kumarNo ratings yet
- Mad Unit 3-JntuworldDocument53 pagesMad Unit 3-JntuworldDilip TheLipNo ratings yet
- LZW Data CompressionDocument5 pagesLZW Data CompressionAJER JOURNALNo ratings yet
- Imc14 05 Dictionary CodesDocument31 pagesImc14 05 Dictionary CodesRohan BorgalliNo ratings yet
- Design and Implementation Af LZW Data Compression AlgorithmDocument11 pagesDesign and Implementation Af LZW Data Compression AlgorithmMandy DiazNo ratings yet
- LZW Compression AlgorithmDocument4 pagesLZW Compression AlgorithmVlad PașcaNo ratings yet
- Unit 2 - Part 7 Coding Information Sources: 1 Adaptive Variable-Length CodesDocument5 pagesUnit 2 - Part 7 Coding Information Sources: 1 Adaptive Variable-Length CodesfsaNo ratings yet
- Chapter 6: The Assembly ProcessDocument7 pagesChapter 6: The Assembly ProcessSiranjeevi MohanarajaNo ratings yet
- Address Decoders: Reading From, or Writing ToDocument3 pagesAddress Decoders: Reading From, or Writing ToMeenakshi SundaramNo ratings yet
- LZW (Lempel Ziv Welch) : 60.1 Brief HistoryDocument4 pagesLZW (Lempel Ziv Welch) : 60.1 Brief HistoryMuziKhumaloNo ratings yet
- Lempel ZivDocument11 pagesLempel ZivabhiNo ratings yet
- Journal of Discrete Algorithms: Satoshi Yoshida, Takuya KidaDocument12 pagesJournal of Discrete Algorithms: Satoshi Yoshida, Takuya KidaChaRly CvNo ratings yet
- 3 Solution Assignment - 02 CoalDocument6 pages3 Solution Assignment - 02 CoalMUHAMMAD AQEEL ANWAR KAMBOHNo ratings yet
- SEM-5 IT137 AMP JOURNAL RemovedDocument69 pagesSEM-5 IT137 AMP JOURNAL RemovedPreet chauhanNo ratings yet
- ch3 Part1Document7 pagesch3 Part1hassan IQNo ratings yet
- Lempel ZivDocument22 pagesLempel ZivHoós LászlóNo ratings yet
- EL213 Computer Organization & Assembly Language Lab 11: String Handling InstructionsDocument12 pagesEL213 Computer Organization & Assembly Language Lab 11: String Handling InstructionsMUHAMMAD AHMEDNo ratings yet
- Compression IIDocument51 pagesCompression IIJagadeesh NaniNo ratings yet
- Basics of Information TheoryDocument21 pagesBasics of Information TheoryTanvi SharmaNo ratings yet
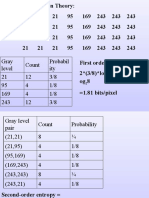
- Gray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8Document51 pagesGray Level Count Probabil Ity 21 12 3/8 95 4 1/8 169 4 1/8 243 12 3/8kamnakhannaNo ratings yet
- Homework #6 (Optional HW) EE457: Due Date: May 2, 2016Document2 pagesHomework #6 (Optional HW) EE457: Due Date: May 2, 2016ottoporNo ratings yet
- Presentation - Lempelziv Ese751 (DR TiDocument55 pagesPresentation - Lempelziv Ese751 (DR TiSuhana SabudinNo ratings yet
- DSD Lab Manuals: Design and Implementation of Leap Year Calculator On FpgaDocument9 pagesDSD Lab Manuals: Design and Implementation of Leap Year Calculator On FpgaAL RIZWANNo ratings yet
- 4 LZWDocument7 pages4 LZWmayur morvekarNo ratings yet
- MOS Decoders, Gate Sizing: ReadingDocument14 pagesMOS Decoders, Gate Sizing: ReadingWaqar AhmedNo ratings yet
- The Lempel Ziv Algorithm: Seminar "Famous Algorithms" January 16, 2003Document26 pagesThe Lempel Ziv Algorithm: Seminar "Famous Algorithms" January 16, 2003Bhushan ShahNo ratings yet
- PLDDocument10 pagesPLDDr Ravi Kumar A.VNo ratings yet
- Chapter 2Document36 pagesChapter 2Bontu GirmaNo ratings yet
- RMF Based EZW Algorithm: School of Computer Science, University of Central Florida, VLSI and M-5 Research GroupDocument33 pagesRMF Based EZW Algorithm: School of Computer Science, University of Central Florida, VLSI and M-5 Research GroupsakilakumaresanNo ratings yet
- prob-F-Talent 2021 Rehearsal - A.LEO Number SystemDocument4 pagesprob-F-Talent 2021 Rehearsal - A.LEO Number SystemHuy Nguyen BaNo ratings yet
- CS LabDocument15 pagesCS LabEncom InternationalNo ratings yet
- Block Arithmetic Coding Source Compression: AbstructDocument9 pagesBlock Arithmetic Coding Source Compression: AbstructGabbu GoshaNo ratings yet
- LZW Compression and Decompression: December 4, 2015Document7 pagesLZW Compression and Decompression: December 4, 2015tafzeman891No ratings yet
- 11.5 Sense Amplifiers and Address Decoders: Reading AssignmentDocument4 pages11.5 Sense Amplifiers and Address Decoders: Reading AssignmentAhmed58seribegawanNo ratings yet
- Introduction To Logic Circuits Lab #7 - Combinational Logic Design 3 (Discrete Parts)Document2 pagesIntroduction To Logic Circuits Lab #7 - Combinational Logic Design 3 (Discrete Parts)Cepheid FaarjanaNo ratings yet
- Japanese Character Code Sets & Encodings:: HistoryDocument8 pagesJapanese Character Code Sets & Encodings:: Historyanindya.partha100% (2)
- Chapter 4 MultiDocument45 pagesChapter 4 Multiadu gNo ratings yet
- CompilerDocument31 pagesCompilerxgnoxcnisharklasersNo ratings yet
- Dictionary Techniques (Lempel-Ziv Codes) : Dictionary, and Encode These Patterns by TransmittingDocument26 pagesDictionary Techniques (Lempel-Ziv Codes) : Dictionary, and Encode These Patterns by TransmittingHarold GealanNo ratings yet
- Prachi, MPDocument71 pagesPrachi, MPSanket ThakareNo ratings yet
- Sri Vidya College of Engineering and Technology Question BankDocument5 pagesSri Vidya College of Engineering and Technology Question BankThiyagarajan JayasankarNo ratings yet
- Lecture 9 ArraysDocument7 pagesLecture 9 Arraysapi-3739389100% (5)
- Chapter 2 New CariculumDocument55 pagesChapter 2 New CariculumElias BaludeNo ratings yet
- Paper - 2011 - List Decoding of Polar Codes - Ido TalDocument14 pagesPaper - 2011 - List Decoding of Polar Codes - Ido Talrobertmotaoliveira73No ratings yet
- Fault Tolerant Huffman Coding For JPEG Image Coding SystemDocument11 pagesFault Tolerant Huffman Coding For JPEG Image Coding SystemMymy SuityNo ratings yet
- Lemp El Ziv CompressionDocument6 pagesLemp El Ziv CompressionssfofoNo ratings yet
- What Is Forward Error Correction (FEC) ? Ans:: Data Transmission Character Code BlockDocument8 pagesWhat Is Forward Error Correction (FEC) ? Ans:: Data Transmission Character Code BlockNicky SanthoshNo ratings yet
- N LMS Impedance BridgeDocument7 pagesN LMS Impedance BridgeCazzKazikNo ratings yet
- Lec0 Source Coding & CompressionDocument38 pagesLec0 Source Coding & CompressionYaseen MoNo ratings yet
- ClassicalDocument1,920 pagesClassicalJayaprakash SundarrajNo ratings yet
- ADC DAC LeastSignificantBit MasteringElexDesignDocument7 pagesADC DAC LeastSignificantBit MasteringElexDesignJohanson CamasuraNo ratings yet
- DecoderDocument6 pagesDecoderAparajitha Narayanan0% (1)
- Modern Introduction to Object Oriented Programming for Prospective DevelopersFrom EverandModern Introduction to Object Oriented Programming for Prospective DevelopersNo ratings yet
- Activity03 SolutionDocument3 pagesActivity03 SolutionHamdi AlbadaniNo ratings yet
- Digital Multimedia - Class Activity 03 26 - 03 - 2017Document3 pagesDigital Multimedia - Class Activity 03 26 - 03 - 2017Hamdi AlbadaniNo ratings yet
- Class Activity 02 SolutionDocument3 pagesClass Activity 02 SolutionHamdi AlbadaniNo ratings yet
- Digital Multimedia - Class Activity 02 12 - 03 - 2017Document3 pagesDigital Multimedia - Class Activity 02 12 - 03 - 2017Hamdi AlbadaniNo ratings yet
- Ust, Yemen: 13 January 2020 1Document18 pagesUst, Yemen: 13 January 2020 1Hamdi AlbadaniNo ratings yet
- Ust, Yemen: 13 January 2020 1Document18 pagesUst, Yemen: 13 January 2020 1Hamdi AlbadaniNo ratings yet
- The Web and The Internet: Learning OutcomesDocument6 pagesThe Web and The Internet: Learning OutcomesRahmat HidayatNo ratings yet
- 8051 Timers and Serial Port: Module - 4Document16 pages8051 Timers and Serial Port: Module - 4Pate VishnuNo ratings yet
- Flake 8Document14 pagesFlake 8ambatiNo ratings yet
- SybeSEC+x Bonus QuestionsDocument31 pagesSybeSEC+x Bonus QuestionsDrizzy Ray50% (2)
- 9303 p10 Cons enDocument130 pages9303 p10 Cons enQuách HuyNo ratings yet
- Programming and Erasing Flash Memory by User Program For Traveo ™ FamilyDocument17 pagesProgramming and Erasing Flash Memory by User Program For Traveo ™ FamilyNight ShadeNo ratings yet
- 25 Hardening Security Tips For Linux ServersDocument9 pages25 Hardening Security Tips For Linux Serverschinku85No ratings yet
- SEO Report - SEO Site CheckupDocument18 pagesSEO Report - SEO Site CheckupDarshak KathiriyaNo ratings yet
- AxTraxNG™ Software Installation and User ManualDocument177 pagesAxTraxNG™ Software Installation and User ManualAtilim TuranNo ratings yet
- S106585GC10 sg2Document318 pagesS106585GC10 sg2Mengistu Redae100% (2)
- Cyber Conflict Between USA and RussiaDocument25 pagesCyber Conflict Between USA and RussiaADNo ratings yet
- Consent Form: (Friday) - Failure To Submit The Accomplished Form Shall Mean Exclusion From TheDocument3 pagesConsent Form: (Friday) - Failure To Submit The Accomplished Form Shall Mean Exclusion From TheSheena SilvaniaNo ratings yet
- Isi Tersirat Isi Tersurat WorksheetDocument6 pagesIsi Tersirat Isi Tersurat WorksheetMegat LokmanNo ratings yet
- QSG FortiGate QuickStart GuideDocument22 pagesQSG FortiGate QuickStart GuidelazyleftNo ratings yet
- EnervistaFlex 105 ReleaseNotesDocument4 pagesEnervistaFlex 105 ReleaseNotestransient matterNo ratings yet
- Mobilising Cyber Power KlimburgDocument20 pagesMobilising Cyber Power KlimburgAntonija JurićNo ratings yet
- 1 Introduction To Network Security PDFDocument18 pages1 Introduction To Network Security PDFsamNo ratings yet
- PWK Example Report v1Document14 pagesPWK Example Report v1Patrick Manzanza100% (1)
- Oracle Mobile Hub DatasheetDocument6 pagesOracle Mobile Hub DatasheetMurtuza SadikotNo ratings yet
- BRKPTC 2309Document180 pagesBRKPTC 2309HAzimNo ratings yet
- Huawei D105 MiFi Modem-En-UserGuideDocument28 pagesHuawei D105 MiFi Modem-En-UserGuideCarlos RodriguesNo ratings yet
- Blitz-Logs 20221002183515Document75 pagesBlitz-Logs 20221002183515Олег КозярчукNo ratings yet
- Project PlanDocument2 pagesProject PlanGuddi ShelarNo ratings yet
- Lab 11: Endpoint Profiling and ReportsDocument14 pagesLab 11: Endpoint Profiling and ReportsJosel ArevaloNo ratings yet
- Networking Methods: Local Area Network (LAN)Document4 pagesNetworking Methods: Local Area Network (LAN)VIKALP KULSHRESTHANo ratings yet
- Unit-I Introduction To Computers: Keyboard Alu, Cu, MU CPU MonitorDocument15 pagesUnit-I Introduction To Computers: Keyboard Alu, Cu, MU CPU MonitorPeter MbuguaNo ratings yet
- Test Analysis Report Test Analysis Report: 1 PurposeDocument4 pagesTest Analysis Report Test Analysis Report: 1 Purposesarav dNo ratings yet
- It Ethics Chap 3Document8 pagesIt Ethics Chap 3Kathleen Gunio100% (1)