You might also like
- Practice Exam IIIDocument8 pagesPractice Exam IIIAdam Hylton100% (2)
- Kailash BusinessReportDocument31 pagesKailash BusinessReportKailash the donNo ratings yet
- Random Motors Presentation Ganesh MisraDocument10 pagesRandom Motors Presentation Ganesh MisraGanesh Misra100% (2)
- Fourth Quarter Periodical Test in Grade Eleven Statistics and ProbabilityDocument2 pagesFourth Quarter Periodical Test in Grade Eleven Statistics and ProbabilityAnonymous GLXj9kKp2100% (2)
- Probability, Statistics, and Queueing TheoryFrom EverandProbability, Statistics, and Queueing TheoryRating: 5 out of 5 stars5/5 (1)
- A Student's Guide to Python for Physical Modeling: Second EditionFrom EverandA Student's Guide to Python for Physical Modeling: Second EditionNo ratings yet
- Lcup Compre Stat Review EditedDocument44 pagesLcup Compre Stat Review EditedJoseph Cabrera100% (1)
- FRAMEDocument49 pagesFRAMEMARKCHRISTMASNo ratings yet
- Chapter 9 Multiple Regression AnalysisDocument15 pagesChapter 9 Multiple Regression AnalysisShahir ImanNo ratings yet
- Calculate Mean and Variance of The Following Data (Intervals)Document2 pagesCalculate Mean and Variance of The Following Data (Intervals)Paritosh TonkNo ratings yet
- A Particle Swarm Optimization (PSO) PrimerDocument16 pagesA Particle Swarm Optimization (PSO) PrimersathiskumarBENo ratings yet
- MBA HRM Batch 2021-2023Document5 pagesMBA HRM Batch 2021-2023Imtiaz SkNo ratings yet
- Physics ExperDocument4 pagesPhysics ExperArchana ArchuNo ratings yet
- Plantilla Doble División SinteticaDocument4 pagesPlantilla Doble División SinteticaAngelBoyNo ratings yet
- VND - Openxmlformats Officedocument - Spreadsheetml.sheet&rendition 1Document12 pagesVND - Openxmlformats Officedocument - Spreadsheetml.sheet&rendition 1patilom0009No ratings yet
- Sources of ErrorDocument23 pagesSources of ErrorMuhammad Ahmad RazaNo ratings yet
- ESI 4313 Operations Research 2: Markov Chains BasicsDocument45 pagesESI 4313 Operations Research 2: Markov Chains BasicsSaman_timNo ratings yet
- Abu ShobakkDocument4 pagesAbu Shobakkmohammad alshawabkaNo ratings yet
- Diketahui: Putaran (N) : 3000 RPM Batas Ukur Amperemeter (I Batas Ukur Amperemeter (Isc) : 12Document2 pagesDiketahui: Putaran (N) : 3000 RPM Batas Ukur Amperemeter (I Batas Ukur Amperemeter (Isc) : 12anon_859877685No ratings yet
- Lect.3 - Simple Genetic AlgorithmsDocument30 pagesLect.3 - Simple Genetic AlgorithmsAmany El-zonkolyNo ratings yet
- FN GRP 4.2 Assignment No 5Document7 pagesFN GRP 4.2 Assignment No 5Darshan sakleNo ratings yet
- Case AnalysisDocument10 pagesCase AnalysisSami Un BashirNo ratings yet
- QMS ExamplesDocument14 pagesQMS ExamplesMuhammad Taha ZakaNo ratings yet
- SlopeDocument1 pageSlopemeajagunNo ratings yet
- Slope PDFDocument1 pageSlope PDFYaritza MirandaNo ratings yet
- Slope PDFDocument1 pageSlope PDFYaritza MirandaNo ratings yet
- Term Project ST5054 - Turbulence Modeling For Engineering FlowsDocument14 pagesTerm Project ST5054 - Turbulence Modeling For Engineering FlowsÜmit CihanNo ratings yet
- Lecture6 Linear Regressionv2Document40 pagesLecture6 Linear Regressionv2翁江靖No ratings yet
- Income Qualification Project3Document40 pagesIncome Qualification Project3NikhilNo ratings yet
- Hasil Panel Ardl MonaDocument6 pagesHasil Panel Ardl MonaNurulNo ratings yet
- Assignment Module 1Document30 pagesAssignment Module 1Priyanka SindhwaniNo ratings yet
- Lect.3 - Simple Genetic AlgorithmsDocument30 pagesLect.3 - Simple Genetic AlgorithmsAmany El-zonkolyNo ratings yet
- Blackwell Publishing Royal Statistical SocietyDocument11 pagesBlackwell Publishing Royal Statistical SocietywatzlawwutzNo ratings yet
- 26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienDocument18 pages26 Xay Dung Va Validate Mo Hinh Hoi Qui Logistic Da BienPhạm Minh ChâuNo ratings yet
- Ansto RadioisotopesDocument3 pagesAnsto RadioisotopesRudransh KatiyarNo ratings yet
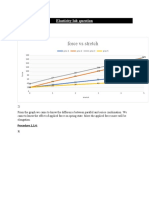
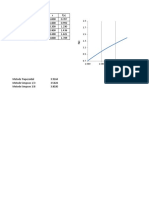
- Force Vs Stretch: Elasticity Lab QuestionDocument2 pagesForce Vs Stretch: Elasticity Lab Questionfarooq umerNo ratings yet
- RiyaThomas SECPresentationDocument5 pagesRiyaThomas SECPresentationRacNo ratings yet
- NSGA and Optimization DocumentDocument6 pagesNSGA and Optimization DocumentAnutthara RatnayakeNo ratings yet
- Assignment #2 Quantitative Methods: Dilivered To: Sir Ahsan Ul Haq Dilivered By: Mubashir HassanDocument6 pagesAssignment #2 Quantitative Methods: Dilivered To: Sir Ahsan Ul Haq Dilivered By: Mubashir HassanHayaa KhanNo ratings yet
- MiniProject - ML - Ipynb - ColaboratoryDocument26 pagesMiniProject - ML - Ipynb - ColaboratoryNight MusicNo ratings yet
- Analysis of DataDocument6 pagesAnalysis of DataJustinNo ratings yet
- Institutional Quality Indicators and Their Impact On Attracting Foreign Direct Investment in Algeria Using The ARDL ModelDocument14 pagesInstitutional Quality Indicators and Their Impact On Attracting Foreign Direct Investment in Algeria Using The ARDL ModelNajib BenslimaneNo ratings yet
- Time Series ARIMA Models Example PDFDocument11 pagesTime Series ARIMA Models Example PDFOye RomeoNo ratings yet
- Computation ProductivityDocument18 pagesComputation ProductivityMark Roger Huberit IINo ratings yet
- HW 2Document4 pagesHW 2الحمزه حبيبNo ratings yet
- Dma TestDocument7 pagesDma TestJatin yadavNo ratings yet
- Histograma: 1 Frecuencia % AcumuladoDocument27 pagesHistograma: 1 Frecuencia % AcumuladoÓscar Fernando VallejoNo ratings yet
- SPACE FRAME Contoh 8,4Document205 pagesSPACE FRAME Contoh 8,4Nabila FairuzNo ratings yet
- Poisson Distribution: Cumulative X P (X) ProbabilityDocument6 pagesPoisson Distribution: Cumulative X P (X) ProbabilityRemy Gamarra PisfilNo ratings yet
- Week 4 Seminar QuestionsDocument5 pagesWeek 4 Seminar QuestionsRoxana AntociNo ratings yet
- Soft Sensor For Faulty Measurements Detection and Reconstruction in Urban TrafficDocument22 pagesSoft Sensor For Faulty Measurements Detection and Reconstruction in Urban TrafficShivankyJaiswalNo ratings yet
- Asignacion 7Document9 pagesAsignacion 7daniel jesusNo ratings yet
- Problem No 1. Solution 1. Conventional Techniques: Skin EffectDocument4 pagesProblem No 1. Solution 1. Conventional Techniques: Skin EffectPaola SalinasNo ratings yet
- Dynamics of Machinery Introduction To Signal Analysis - Parts I and IIDocument29 pagesDynamics of Machinery Introduction To Signal Analysis - Parts I and IIFernando TezzaNo ratings yet
- What We Have Done So Far?Document32 pagesWhat We Have Done So Far?UTKARSH PABALENo ratings yet
- ProjectDocument22 pagesProjectmr haldarNo ratings yet
- Mloa Exp1 C121Document49 pagesMloa Exp1 C121Devanshu MaheshwariNo ratings yet
- Sources of ErrorDocument22 pagesSources of ErrorHiraya HaeldrichNo ratings yet
- RSQ PDFDocument1 pageRSQ PDFYaritza MirandaNo ratings yet
- RSQ PDFDocument1 pageRSQ PDFYaritza MirandaNo ratings yet
- Lab 4 Poisson Distribution: Object: Output: CodeDocument4 pagesLab 4 Poisson Distribution: Object: Output: CodehareemmisbahNo ratings yet
- Book 1Document6 pagesBook 1Muhammad Hafizh AhsanNo ratings yet
- 5535 Chapter 19Document56 pages5535 Chapter 19ChunTing LinNo ratings yet
- Structural Model TestsDocument50 pagesStructural Model Testsyasit10No ratings yet
- QT II (Hy I) & (Hy II)Document116 pagesQT II (Hy I) & (Hy II)avijeetboparaiNo ratings yet
- Composites: Part BDocument13 pagesComposites: Part BShahnewaz BhuiyanNo ratings yet
- Recent and Future Trends in E - Banking Services For Indian Banking SectorDocument8 pagesRecent and Future Trends in E - Banking Services For Indian Banking SectorarmsocketproductionsNo ratings yet
- Hypothesis Testing Using MinitabDocument20 pagesHypothesis Testing Using MinitabAero AcadNo ratings yet
- Time Series Analysis of Philippine Agricultural Rice Productivity Using Cobb-Douglas Production Function From 2017 To 2022Document5 pagesTime Series Analysis of Philippine Agricultural Rice Productivity Using Cobb-Douglas Production Function From 2017 To 2022Poonam KilaniyaNo ratings yet
- 12 HR Practices in SBI 2016 PDFDocument9 pages12 HR Practices in SBI 2016 PDFPrateek DadhichNo ratings yet
- Numpy NP Pandas PD Scipy Matplotlib - Pyplot PLT Statsmodels - Api SM Statsmodels - Tsa.setar - Model Setar - ModelDocument3 pagesNumpy NP Pandas PD Scipy Matplotlib - Pyplot PLT Statsmodels - Api SM Statsmodels - Tsa.setar - Model Setar - ModelAnthony Alarcón MorenoNo ratings yet
- IMPACT OF MARKETING KNOWLEDGE MANAGEMENT ON MARKETING INNOVATION - EMPIRICAL EVIDENCE FROM NIGERIAN SMEsDocument18 pagesIMPACT OF MARKETING KNOWLEDGE MANAGEMENT ON MARKETING INNOVATION - EMPIRICAL EVIDENCE FROM NIGERIAN SMEsparsadNo ratings yet
- A Study On The Financial Performance of General Insurance Companies in IndiaDocument7 pagesA Study On The Financial Performance of General Insurance Companies in IndiaanilNo ratings yet
- Lesson 1 Intro To Hypothesis TestingDocument26 pagesLesson 1 Intro To Hypothesis TestingMaimai PanaNo ratings yet
- Math644 - Chapter 1 - Part2 PDFDocument14 pagesMath644 - Chapter 1 - Part2 PDFaftab20No ratings yet
- Some Exercises Using MinitabDocument20 pagesSome Exercises Using Minitabkambiz imani khaniNo ratings yet
- Airline IndusDocument8 pagesAirline IndusJanani SivaNo ratings yet
- ST130 S1 2016 SolDocument5 pagesST130 S1 2016 SolChand DivneshNo ratings yet
- Customer Preference and Satisfaction Towards Online Movie Ticket Booking System PDFDocument14 pagesCustomer Preference and Satisfaction Towards Online Movie Ticket Booking System PDFdanyashNo ratings yet
- A Sample Econometric ModelDocument4 pagesA Sample Econometric ModelHarvey Malmis NiereNo ratings yet
- Nptel Research Assignment 7Document6 pagesNptel Research Assignment 7Bhargav Bhat100% (1)
- Impact of Economic and Non-Economic Variables On RDocument14 pagesImpact of Economic and Non-Economic Variables On RNovoraj RoyNo ratings yet
- Violons Osteo BerlinDocument19 pagesViolons Osteo Berlinbooetienne30No ratings yet
- The Effect of Constraint Induced Movement Therapy in Brachial Plexus Injury PDocument59 pagesThe Effect of Constraint Induced Movement Therapy in Brachial Plexus Injury PImran KhanNo ratings yet
- Probability and Statistic Chapter5Document29 pagesProbability and Statistic Chapter5PHƯƠNG ĐẶNG YẾNNo ratings yet
- 145 Chapter 8 2009Document25 pages145 Chapter 8 2009VANESSA JABAGATNo ratings yet
- Full Statistical Techniques in Business and Economics 16Th Edition Lind Solutions Manual Online PDF All ChapterDocument42 pagesFull Statistical Techniques in Business and Economics 16Th Edition Lind Solutions Manual Online PDF All Chapterbarbaraaguirre519555100% (5)
- Sample Thesis With AnovaDocument4 pagesSample Thesis With Anovavxjtklxff100% (2)