You might also like
- Decision Support System: Fundamentals and Applications for The Art and Science of Smart ChoicesFrom EverandDecision Support System: Fundamentals and Applications for The Art and Science of Smart ChoicesNo ratings yet
- CISA Exam-Testing Concept-Decision Support System (DSS) (Domain-3)From EverandCISA Exam-Testing Concept-Decision Support System (DSS) (Domain-3)No ratings yet
- Decision Support Systems (DSS)Document13 pagesDecision Support Systems (DSS)wasiuddinNo ratings yet
- Decision Support SystemDocument1 pageDecision Support Systemleonel_1717No ratings yet
- Marketing Decision Support SystemDocument7 pagesMarketing Decision Support SystemSyed Umair RizviNo ratings yet
- Decision Support SystemDocument26 pagesDecision Support SystemamreenaNo ratings yet
- Decision Support System - WikipediaDocument5 pagesDecision Support System - WikipediaSarah Jean TrajanoNo ratings yet
- Decision Support SystemDocument40 pagesDecision Support SystemAnonymous gUjimJKNo ratings yet
- DssDocument7 pagesDssanashussainNo ratings yet
- Decision Support SystemDocument19 pagesDecision Support SystemClassic WheelsNo ratings yet
- Mis 2 & 3Document90 pagesMis 2 & 3sijim_88437No ratings yet
- Decision Support SystemDocument16 pagesDecision Support SystemGuillermo SotoNo ratings yet
- DSS and ESS: Decision Support Systems and Executive Support SystemsDocument17 pagesDSS and ESS: Decision Support Systems and Executive Support SystemsCR7 الظاهرةNo ratings yet
- Decision Support Systems & Executive Support SystemsDocument17 pagesDecision Support Systems & Executive Support SystemsNabila T. Chowdhury100% (10)
- Decision Support SystemDocument5 pagesDecision Support SystemSai SridharNo ratings yet
- DSS Characteristics:: Decision Support SystemDocument6 pagesDSS Characteristics:: Decision Support Systemmuddassir videosNo ratings yet
- Intelligent Decision Support Systems - A FrameworkDocument9 pagesIntelligent Decision Support Systems - A FrameworkAlexander DeckerNo ratings yet
- Compare - Dss and Bi PDFDocument6 pagesCompare - Dss and Bi PDFSharmila SaravananNo ratings yet
- Decision Support SystemDocument3 pagesDecision Support SystemValerie BautistaNo ratings yet
- Dss - WikiDocument9 pagesDss - Wikishvetabhan100% (1)
- Decision Support System: HistoryDocument16 pagesDecision Support System: HistoryMsafiri Kafiri Nathan Francis100% (4)
- Seminar On Decision Support SystemDocument5 pagesSeminar On Decision Support Systemjatin_57187No ratings yet
- Georgiana MarinDocument4 pagesGeorgiana MarinRadhianisa IgatamaNo ratings yet
- DSS overview and role in businessDocument26 pagesDSS overview and role in businessMadhurGuptaNo ratings yet
- Decision Support SystemsDocument36 pagesDecision Support SystemssindhujaNo ratings yet
- The Architecture of An Optimizing Decision Support SystemDocument6 pagesThe Architecture of An Optimizing Decision Support SystempraveenaviNo ratings yet
- MIS-10 HandoutDocument2 pagesMIS-10 HandoutRaphael Pepiton IslaNo ratings yet
- A NARRATIVE REPORT OF Chapter16Document22 pagesA NARRATIVE REPORT OF Chapter16Mafe Angela OrejolaNo ratings yet
- Decision Support SystemDocument18 pagesDecision Support Systemsharma100% (2)
- Research PaperDocument13 pagesResearch PaperChampa BopegamaNo ratings yet
- A Decision Support SystemDocument4 pagesA Decision Support SystemVasudha DadaNo ratings yet
- Components of A DSS: SoftwareDocument3 pagesComponents of A DSS: Softwareaisolamaddy86No ratings yet
- 3 - DSS and EISDocument27 pages3 - DSS and EISBshwas TeamllcenaNo ratings yet
- Group 5 MisDocument16 pagesGroup 5 Mischak.m.beyenaNo ratings yet
- Dss As An Umbrella TermDocument28 pagesDss As An Umbrella Termarchana_sree13No ratings yet
- CL585Document7 pagesCL585marcusfdm69No ratings yet
- MIS - Management Information SystemDocument8 pagesMIS - Management Information SystemGinu L PrakashNo ratings yet
- Management Information System: The Business School, University of JammuDocument10 pagesManagement Information System: The Business School, University of Jammuanon_945457258No ratings yet
- Unit 1-Decision Support SystemsDocument10 pagesUnit 1-Decision Support SystemsDisha Verma KalraNo ratings yet
- Decision Support Systems: Practical No. 3Document8 pagesDecision Support Systems: Practical No. 3Suvarna LangadeNo ratings yet
- Lesson 5 - Building DSSDocument8 pagesLesson 5 - Building DSSSamwelNo ratings yet
- Mis 3Document73 pagesMis 3JithuHashMiNo ratings yet
- Understanding Decision Support Systems (DSSDocument19 pagesUnderstanding Decision Support Systems (DSSankitNo ratings yet
- Dss Class PDFDocument17 pagesDss Class PDFAkashNo ratings yet
- Dss 3Document21 pagesDss 3ErwinFunaNo ratings yet
- Dss Assignment 2 RealDocument7 pagesDss Assignment 2 RealPeace Runyararo MutenderiNo ratings yet
- Decision Support SystemsDocument9 pagesDecision Support SystemsJowanna BurceNo ratings yet
- Decision Support SystemsDocument9 pagesDecision Support Systemsu5999424No ratings yet
- Dss Introduction2Document16 pagesDss Introduction2boychatmateNo ratings yet
- DECISION-MAKING PROCESS AND TOOLSDocument28 pagesDECISION-MAKING PROCESS AND TOOLSvenkat1972No ratings yet
- Module 1 Lesson 4 Supllementary NotesDocument6 pagesModule 1 Lesson 4 Supllementary NotesMohit DaymaNo ratings yet
- Decision Support SystemDocument5 pagesDecision Support SystemKaviya VarshiniNo ratings yet
- Management Information System: AssignmentDocument7 pagesManagement Information System: AssignmentiftikharhassanNo ratings yet
- Decision Support SystemDocument11 pagesDecision Support SystemGaurav MittalNo ratings yet
- Information Systems Analysis 488Document20 pagesInformation Systems Analysis 488Mebiratu BeyeneNo ratings yet
- Unit 2Document18 pagesUnit 2galaxy123No ratings yet
- Decision Support SystemDocument4 pagesDecision Support SystemNickyGuptaNo ratings yet
- Decision Support SystemDocument6 pagesDecision Support SystemNaveenNo ratings yet
- decision-support-systems (1)Document7 pagesdecision-support-systems (1)JonathanNo ratings yet
- B.I Unit 1Document106 pagesB.I Unit 1kayNo ratings yet
- Understanding Batch File Distribution Packages v1.4 PDFDocument44 pagesUnderstanding Batch File Distribution Packages v1.4 PDFAdrian AdunaNo ratings yet
- ChatGPT Plugin Database - ROIHacks - Com - Live - 2Document143 pagesChatGPT Plugin Database - ROIHacks - Com - Live - 2Jean100% (1)
- Ch4 OS BasicsDocument41 pagesCh4 OS Basicspimat40375No ratings yet
- BMW TIS HandbookDocument3 pagesBMW TIS Handbookandcm0% (1)
- Chinese Remainder Theorem PDFDocument5 pagesChinese Remainder Theorem PDFAnish RayNo ratings yet
- FMC Microflow CalculationsDocument24 pagesFMC Microflow Calculationsstefano375No ratings yet
- Drone Technology Explained: A Guide to UAV Components and ApplicationsDocument19 pagesDrone Technology Explained: A Guide to UAV Components and ApplicationsArvind KeesaraNo ratings yet
- P0903BDG: N-Channel Enhancement Mode MOSFETDocument5 pagesP0903BDG: N-Channel Enhancement Mode MOSFETJohnny Alberto Caicedo NiñoNo ratings yet
- MELSEC-A - QnA Series Transition Examples - L08121ecDocument184 pagesMELSEC-A - QnA Series Transition Examples - L08121ecAym BrNo ratings yet
- Board Resolution No 1 For ECT 2011Document21 pagesBoard Resolution No 1 For ECT 2011Reygie Bulanon MoconNo ratings yet
- Module 3 - Data and Database ManagementDocument11 pagesModule 3 - Data and Database ManagementDarrilyn VillalunaNo ratings yet
- A Review On Load Sharing of TransformerDocument5 pagesA Review On Load Sharing of TransformerIJSTENo ratings yet
- Long Range Uhf Idt 88Document2 pagesLong Range Uhf Idt 88abishek lakhotiaNo ratings yet
- Data Calls Check Gena Reset Uplink DownlinkDocument14 pagesData Calls Check Gena Reset Uplink DownlinkPradheep Renganathan100% (1)
- Service Manual: Digital KeyboardDocument58 pagesService Manual: Digital KeyboardIbu Guru VinaNo ratings yet
- N1 Brief Introduction20171020Document27 pagesN1 Brief Introduction20171020Carlos CabreraNo ratings yet
- INFO EDGE (INDIA) LIMITED (Standalone)Document2 pagesINFO EDGE (INDIA) LIMITED (Standalone)Arjun SomanNo ratings yet
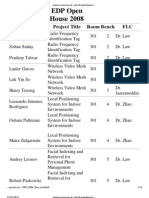
- EDP 2008 Class ListDocument12 pagesEDP 2008 Class ListYash GandhiNo ratings yet
- Jde 910 Accounts ReceivableDocument612 pagesJde 910 Accounts ReceivableazizirfanNo ratings yet
- Alberta Health SurveillanceDocument1 pageAlberta Health SurveillanceDaniel OtzoyNo ratings yet
- Communication Trainer CT 3000Document2 pagesCommunication Trainer CT 3000UmairIsmail100% (1)
- Hosting Company Network SetupDocument32 pagesHosting Company Network SetupJoyfulness EphaNo ratings yet
- Question Bank FinalDocument44 pagesQuestion Bank Finalswadeshsxc100% (1)
- Transmision PDFDocument26 pagesTransmision PDFAirton Ahyrton Macazana HuaringaNo ratings yet
- History of EdutechDocument4 pagesHistory of EdutechMaripaz MorelosNo ratings yet
- Report On (Type Your Title Here)Document21 pagesReport On (Type Your Title Here)dbbony 0099No ratings yet
- CrashDocument4 pagesCrashzDarkCodexNo ratings yet
- K Uniflair Mp20engDocument27 pagesK Uniflair Mp20engtucurici5740No ratings yet
- 1Document2 pages1Karl Meng100% (1)
- Solaris - Sys Admin 1Document419 pagesSolaris - Sys Admin 1pradipgudale2000No ratings yet