You might also like
- 2 LESSON 2 Freq Graphs FQDocument21 pages2 LESSON 2 Freq Graphs FQexams_sbsNo ratings yet
- Chapter-3-Methods of Data PresentationDocument13 pagesChapter-3-Methods of Data PresentationAba MachaNo ratings yet
- Chapter-2-Methods of Data PresentationDocument14 pagesChapter-2-Methods of Data PresentationTithina TekluNo ratings yet
- Chapter-2-Methods of Data PresentationDocument14 pagesChapter-2-Methods of Data PresentationOdana negeroNo ratings yet
- SM 1Document125 pagesSM 1Amit YadavNo ratings yet
- Utilization of Assessment DataDocument50 pagesUtilization of Assessment DataIvy Claris Ba-awa Iquin100% (3)
- Chapter 2: Frequency Distribution and Measures of Central Tendency 2.1 A FREQUENCY DISTRIBUTION Is A Tabular Arrangement of Data Whereby The Data Is GroupedDocument9 pagesChapter 2: Frequency Distribution and Measures of Central Tendency 2.1 A FREQUENCY DISTRIBUTION Is A Tabular Arrangement of Data Whereby The Data Is GroupedDaille Wroble GrayNo ratings yet
- Chapter 1ppt 1Document40 pagesChapter 1ppt 1Abazer SultanNo ratings yet
- Statistics chp3&4Document33 pagesStatistics chp3&4Tasebe GetachewNo ratings yet
- Chapter-2-Methods of Data PresentationDocument17 pagesChapter-2-Methods of Data PresentationAyu AlemuNo ratings yet
- Statistika BisnisDocument20 pagesStatistika BisnisZkdlin 23No ratings yet
- Statistics CombineDocument65 pagesStatistics CombineMustansar saeedNo ratings yet
- MODULE 3 - Data ManagementDocument21 pagesMODULE 3 - Data ManagementCIELICA BURCANo ratings yet
- Engineering Statistics: Ministry of Higher Education & Scientific Research University of Kirkuk College of EngineeringDocument15 pagesEngineering Statistics: Ministry of Higher Education & Scientific Research University of Kirkuk College of Engineeringfaroze libraryNo ratings yet
- DBMS ConceptsDocument18 pagesDBMS ConceptsRoha CbcNo ratings yet
- Chapter 02 PowerPointDocument31 pagesChapter 02 PowerPointMutiara BintangNo ratings yet
- Chapter-2-Static of Data-1Document13 pagesChapter-2-Static of Data-1Gatluak Thalow KuethNo ratings yet
- MMW Module 4 - StatisticsDocument18 pagesMMW Module 4 - StatisticsAndrey Mary RanolaNo ratings yet
- Classification of DataDocument22 pagesClassification of DataSourabh ChavanNo ratings yet
- StatisticsDocument5 pagesStatisticsElsie Mae Murillo Balba-ArañezNo ratings yet
- Chapter 02 PowerPointDocument29 pagesChapter 02 PowerPointtantriNo ratings yet
- Chapter-2-Methods of Data PresentationDocument17 pagesChapter-2-Methods of Data Presentationkenenisa.abdisastatNo ratings yet
- RESEARCHDocument9 pagesRESEARCHMazze Ashley SenaNo ratings yet
- MMW Module 4 - Statistics - Data ManagementDocument4 pagesMMW Module 4 - Statistics - Data ManagementErille Julianne (Rielianne)100% (1)
- Lesson 2: Summarizing DataDocument53 pagesLesson 2: Summarizing DataminhchauNo ratings yet
- Chapter 2 Classification and Presentation of DataDocument43 pagesChapter 2 Classification and Presentation of DataKNo ratings yet
- Measure of Central TendancyDocument14 pagesMeasure of Central TendancyZamiyr MuthoniNo ratings yet
- Chapter-2-Methods of Data PresentationDocument15 pagesChapter-2-Methods of Data Presentationfiriikedir4No ratings yet
- C3 Measures of Central TendencyDocument48 pagesC3 Measures of Central TendencyTeresa Mae Abuzo Vallejos-BucagNo ratings yet
- Statistics, mg4Document58 pagesStatistics, mg4Himanshu ChawlaNo ratings yet
- Lecture 1 PDFDocument49 pagesLecture 1 PDFPorkkodi Sugumaran0% (1)
- Chapter 2 PPT EngDocument29 pagesChapter 2 PPT Engaju michaelNo ratings yet
- Learning Competencies:: at The End of The Chapter, The Learner Should Be Able ToDocument29 pagesLearning Competencies:: at The End of The Chapter, The Learner Should Be Able ToJhanna Miegh RentilloNo ratings yet
- LAS4 PR2 Quarter 2 Week 4 1Document11 pagesLAS4 PR2 Quarter 2 Week 4 1Monica SolomonNo ratings yet
- Chapter 5, ANOVADocument6 pagesChapter 5, ANOVAGirma erenaNo ratings yet
- ResearchDocument9 pagesResearchMazze Ashley SenaNo ratings yet
- Business Statistics: A Decision-Making Approach: Graphs, Charts, and Tables - Describing Your DataDocument47 pagesBusiness Statistics: A Decision-Making Approach: Graphs, Charts, and Tables - Describing Your DataYahya AodahNo ratings yet
- LECTURE NO. 5 Measures of Central TendencyDocument27 pagesLECTURE NO. 5 Measures of Central TendencyCzarina GuevarraNo ratings yet
- StatsB FrequencyDistributionsDocument2 pagesStatsB FrequencyDistributionsmery9jean9lasamNo ratings yet
- Saint Ma 'S College September 4, 2021: 6 October 2021Document30 pagesSaint Ma 'S College September 4, 2021: 6 October 2021Chin TampipiNo ratings yet
- Statistics Chapter-IIDocument66 pagesStatistics Chapter-IIMiley GirmayNo ratings yet
- Data Presentation and OrganizationDocument40 pagesData Presentation and OrganizationGina Mangco-SantosNo ratings yet
- Principal Component AnalysisDocument39 pagesPrincipal Component AnalysisAsimullah, M.Phil. Scholar Department of Computer Science, UoPNo ratings yet
- MODULE 2 For 2nd Year BSEd-Mathematics First Sem AY 2023 - 2024Document25 pagesMODULE 2 For 2nd Year BSEd-Mathematics First Sem AY 2023 - 2024Shiella BaydalNo ratings yet
- JAGUIMIT - Detailed Doc For The PresentationDocument5 pagesJAGUIMIT - Detailed Doc For The PresentationKailah Kristine Congreso JaguimitNo ratings yet
- Measure of Central Tendency (Ungrouped and Grouped Data)Document40 pagesMeasure of Central Tendency (Ungrouped and Grouped Data)Ahlan Marciano Emmanuel De Silva100% (1)
- Business Statistics: Graphs, Charts, and Tables - Describing Your Data Graphs, Charts, and Tables - Describing Your DataDocument74 pagesBusiness Statistics: Graphs, Charts, and Tables - Describing Your Data Graphs, Charts, and Tables - Describing Your DataMuneer Quraishi100% (1)
- Chapter 3 PDFDocument27 pagesChapter 3 PDFShiv NeelNo ratings yet
- Statistics 1 Year Paper PatternDocument7 pagesStatistics 1 Year Paper PatternYousaf AsgharNo ratings yet
- Chapter 5Document29 pagesChapter 5Sherbeth DorojaNo ratings yet
- Aj Ka KaamDocument21 pagesAj Ka KaamAnonymous fg4ACqNo ratings yet
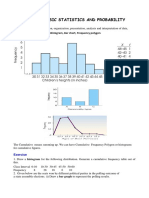
- Unit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonDocument6 pagesUnit-V Basic Statistics and Probability: Presentation - Three Forms - Histogram, Bar Chart, Frequency PolygonVenkatesh WaranNo ratings yet
- 3.dispersion and Skewness-Students Notes-MARDocument29 pages3.dispersion and Skewness-Students Notes-MARhalilmohamed830No ratings yet
- Frequency Distribution: A Frequency Distribution Is Constructed For Three Main ReasonsDocument15 pagesFrequency Distribution: A Frequency Distribution Is Constructed For Three Main ReasonsBhawna JoshiNo ratings yet
- Math in The Modern World - Module - Final Term - Revised 1Document72 pagesMath in The Modern World - Module - Final Term - Revised 1Jac ValdenorNo ratings yet
- Research Methods Lesson NotesDocument35 pagesResearch Methods Lesson NotesCarol SoiNo ratings yet
- Chapter 2 Method of Data Collection andDocument59 pagesChapter 2 Method of Data Collection andG Gጂጂ TubeNo ratings yet
- 1 Unnamed 04 01 2024Document66 pages1 Unnamed 04 01 2024vanchagargNo ratings yet
- 02 - Descriptive StatisticsDocument45 pages02 - Descriptive StatisticsSayapPutihNo ratings yet
- BIM II Final Exam 2019-20Document3 pagesBIM II Final Exam 2019-20Yohannes AlemayehuNo ratings yet
- Apartment Program DevelopmentDocument3 pagesApartment Program DevelopmentYohannes Alemayehu100% (1)
- Architectural Working Drawing II (Presentaion)Document27 pagesArchitectural Working Drawing II (Presentaion)Yohannes AlemayehuNo ratings yet
- Chapter 1Document12 pagesChapter 1Mekonin LakewNo ratings yet
- Knowledge From School in InternshipDocument3 pagesKnowledge From School in InternshipYohannes AlemayehuNo ratings yet
- Apartment Buildings Are MultiDocument14 pagesApartment Buildings Are MultiYohannis AlemayehuNo ratings yet
- Adamma Sceince and Technology Univercity Architecture Program DevelopmentDocument4 pagesAdamma Sceince and Technology Univercity Architecture Program DevelopmentYohannes AlemayehuNo ratings yet
- Inernational and Local Case StudyDocument13 pagesInernational and Local Case StudyYohannes AlemayehuNo ratings yet
- CH 2 Building DrawingsDocument8 pagesCH 2 Building DrawingsYohannes AlemayehuNo ratings yet
- Relationship Between Structure and Architecture Presentation 1Document43 pagesRelationship Between Structure and Architecture Presentation 1Yohannes AlemayehuNo ratings yet
- East ElevationDocument1 pageEast ElevationYohannes AlemayehuNo ratings yet
- Advanced Schedule Management of Shopping Mall ProjectsDocument6 pagesAdvanced Schedule Management of Shopping Mall ProjectsYohannes AlemayehuNo ratings yet
- Shopping Mall Project: Citation PreviewDocument11 pagesShopping Mall Project: Citation PreviewYohannes AlemayehuNo ratings yet
- Responses To Urban Idps in Adama Ethiopia WebDocument32 pagesResponses To Urban Idps in Adama Ethiopia WebYohannes AlemayehuNo ratings yet
- Latvia Univ Agriculture Civil Engineering2011 253 255Document3 pagesLatvia Univ Agriculture Civil Engineering2011 253 255Yohannes AlemayehuNo ratings yet
- Project Profile AdamaDocument4 pagesProject Profile AdamaYohannes AlemayehuNo ratings yet
- HVAC - Natural Ventilation Principles R1Document51 pagesHVAC - Natural Ventilation Principles R1siddique27No ratings yet
- Types of Foundations: Shallow Foundation Deep FoundationDocument28 pagesTypes of Foundations: Shallow Foundation Deep FoundationLeung Wai YipNo ratings yet
- Responses To Urban Idps in Adama Ethiopia WebDocument32 pagesResponses To Urban Idps in Adama Ethiopia WebYohannes AlemayehuNo ratings yet
- Frequency Distribution & GraghsDocument28 pagesFrequency Distribution & GraghsManish KumarNo ratings yet
- LP 3 - Data Management, HeheDocument36 pagesLP 3 - Data Management, HeheRiane SabañecoNo ratings yet
- Describing Data:: Frequency Tables, Frequency Distributions, and Graphic PresentationDocument14 pagesDescribing Data:: Frequency Tables, Frequency Distributions, and Graphic PresentationARKONo ratings yet
- A OFdh O5 Ecar EZ9 o 9 W 0 T QDocument95 pagesA OFdh O5 Ecar EZ9 o 9 W 0 T QShreya GuheNo ratings yet
- Chapter Four: Measures of Central TendencyDocument33 pagesChapter Four: Measures of Central TendencyLove IsNo ratings yet
- BTEC HNC - Analytical Methods - Statistics and ProbabilityDocument20 pagesBTEC HNC - Analytical Methods - Statistics and ProbabilityBrendan Burr50% (2)
- 0580 Statistics Lesson4 Cumulative v1Document31 pages0580 Statistics Lesson4 Cumulative v1Andreas EqqoNo ratings yet
- Types of Data and Data Sources MbaDocument19 pagesTypes of Data and Data Sources MbaHimanshu SharmaNo ratings yet
- Statistics 2 WorksheetDocument16 pagesStatistics 2 WorksheetPrince YugNo ratings yet
- CENTRAL TENDENCY Topical Past PapersDocument35 pagesCENTRAL TENDENCY Topical Past PapersLearn MathematicsNo ratings yet
- New Generation University College: AUGUST 2020Document51 pagesNew Generation University College: AUGUST 2020sileshiNo ratings yet
- Supplementary Exercise 3 - Summary StatisticsDocument3 pagesSupplementary Exercise 3 - Summary StatisticsMohamed EzzatNo ratings yet
- Mathematics W18Document31 pagesMathematics W18Alexander IkechukwuNo ratings yet
- Graphical Representation of DataDocument6 pagesGraphical Representation of DataJustine Louise Bravo FerrerNo ratings yet
- ES031 M1 DataCollection&PresentationDocument64 pagesES031 M1 DataCollection&PresentationGwyneth Marie DayaganNo ratings yet
- Module Two: Frequency Distribution and Their Graphic RepresentationsDocument14 pagesModule Two: Frequency Distribution and Their Graphic RepresentationsDarcknyPusodNo ratings yet
- Practice B: Frequency Tables, Stem-and-Leaf Plots, and Line PlotsDocument2 pagesPractice B: Frequency Tables, Stem-and-Leaf Plots, and Line PlotsShimaa SamirNo ratings yet
- Assignment-Bfc 34303 StatisticsDocument3 pagesAssignment-Bfc 34303 StatisticsNur AzminaNo ratings yet
- QUIZDocument2 pagesQUIZJessiah Jade LeyvaNo ratings yet
- SS2 Maths Lesson Note PDFDocument104 pagesSS2 Maths Lesson Note PDFdnlbalogun100% (1)
- Measures of Central TendencyDocument7 pagesMeasures of Central TendencyAnjo Pasiolco CanicosaNo ratings yet
- CASE STUDY (Statistics) Mam EstorDocument13 pagesCASE STUDY (Statistics) Mam EstorChristine Jane RamosNo ratings yet
- EDA Lecture NotesDocument113 pagesEDA Lecture Notesyusif samNo ratings yet
- CH 2Document14 pagesCH 2Bayelign GedefawNo ratings yet
- Chapter 6Document15 pagesChapter 6Abhinav MohantyNo ratings yet
- Statistics AnswerDocument8 pagesStatistics AnswerVeeno DarveenaNo ratings yet
- Geography PracticalDocument108 pagesGeography Practicaldev900975% (4)
- Chapter 1 Introduction To Statistics For EngineersDocument91 pagesChapter 1 Introduction To Statistics For EngineersEngidNo ratings yet
- Dwnload Full Essentials of Statistics For Business and Economics 7th Edition Anderson Test Bank PDFDocument36 pagesDwnload Full Essentials of Statistics For Business and Economics 7th Edition Anderson Test Bank PDFmortgagechoric3yh7100% (9)
- Project Risk Management Process Construction ProjectsDocument12 pagesProject Risk Management Process Construction ProjectsPrateek VyasNo ratings yet
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryFrom EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNo ratings yet
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)From EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)No ratings yet
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathFrom EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathRating: 5 out of 5 stars5/5 (1)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsFrom EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsRating: 3.5 out of 5 stars3.5/5 (9)
- Magic Multiplication: Discover the Ultimate Formula for Fast MultiplicationFrom EverandMagic Multiplication: Discover the Ultimate Formula for Fast MultiplicationNo ratings yet
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (80)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet
- Who Tells the Truth?: Collection of Logical Puzzles to Make You ThinkFrom EverandWho Tells the Truth?: Collection of Logical Puzzles to Make You ThinkRating: 5 out of 5 stars5/5 (1)