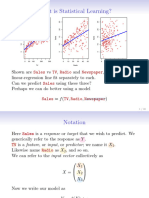
You might also like
- pt4 Adv Regression Models PDFDocument170 pagespt4 Adv Regression Models PDFVishwajit kumarNo ratings yet
- 2014 TestDocument13 pages2014 TestAnonymous gUySMcpSqNo ratings yet
- Regression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AiDocument50 pagesRegression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AithcNo ratings yet
- Stat 5102 Lecture Slides: Deck 6 Gauss-Markov Theorem, Sufficiency, Generalized Linear Models, Likelihood Ratio Tests, Categorical Data AnalysisDocument86 pagesStat 5102 Lecture Slides: Deck 6 Gauss-Markov Theorem, Sufficiency, Generalized Linear Models, Likelihood Ratio Tests, Categorical Data AnalysisHông HoaNo ratings yet
- Prelims StatsDocument39 pagesPrelims StatsSergioNo ratings yet
- Lecture 16: Polynomial and Categorical Regression 1 ReviewDocument10 pagesLecture 16: Polynomial and Categorical Regression 1 ReviewSNo ratings yet
- Sim RDocument6 pagesSim Rsipho23No ratings yet
- 330 Lecture11 2014Document61 pages330 Lecture11 2014PETERNo ratings yet
- Transformations and Misspecification of Econometric Models: August 27, 2014Document19 pagesTransformations and Misspecification of Econometric Models: August 27, 2014Maria RoaNo ratings yet
- ClusteringDocument62 pagesClusteringRichard RichieNo ratings yet
- Gradient Descent: Ryan Tibshirani Convex Optimization 10-725Document27 pagesGradient Descent: Ryan Tibshirani Convex Optimization 10-725JohnNo ratings yet
- Lecture 17: Multicollinearity 1 Why Collinearity Is A ProblemDocument9 pagesLecture 17: Multicollinearity 1 Why Collinearity Is A ProblemSNo ratings yet
- STAT1400 2022 1st Week4-Lecture 7Document19 pagesSTAT1400 2022 1st Week4-Lecture 7Sameer GuptaNo ratings yet
- C2 Statistical LearningDocument37 pagesC2 Statistical LearningLluïsa GualNo ratings yet
- K-Means Vs Mini Batch K-Means: A ComparisonDocument12 pagesK-Means Vs Mini Batch K-Means: A Comparisonrather AarifNo ratings yet
- Lpic Package - L TEX Over Graphics: Vinh Q. NguyenDocument4 pagesLpic Package - L TEX Over Graphics: Vinh Q. Nguyenvinhdizzo6130No ratings yet
- Lecture 07Document16 pagesLecture 07Deepak Kumar YadavNo ratings yet
- 5 Regression PDFDocument115 pages5 Regression PDFhawk91No ratings yet
- Model Visualisation: (With Ggplot2)Document25 pagesModel Visualisation: (With Ggplot2)api-14814295No ratings yet
- RQ Mcycle1Document1 pageRQ Mcycle1rojasleopNo ratings yet
- EloisaDocument12 pagesEloisastarbridNo ratings yet
- Math 141: Lecture 18: Correlation and RegressionDocument26 pagesMath 141: Lecture 18: Correlation and RegressionCory DimagibaNo ratings yet
- Economics 536 Transformations and The Specification of Econometric ModelsDocument13 pagesEconomics 536 Transformations and The Specification of Econometric ModelsMaria RoaNo ratings yet
- Midterm Test: Reaction Times Vs Caffeine IntakeDocument2 pagesMidterm Test: Reaction Times Vs Caffeine IntakeAnonymous gUySMcpSqNo ratings yet
- On The Estimation of Change Points in The Beer-Lambert Law ProblemDocument14 pagesOn The Estimation of Change Points in The Beer-Lambert Law ProblemNunee AyuNo ratings yet
- 330 Lecture8 2014Document34 pages330 Lecture8 2014Anonymous gUySMcpSqNo ratings yet
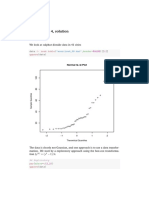
- Week 4, Solution: Exercise 4.38Document15 pagesWeek 4, Solution: Exercise 4.38John SmithNo ratings yet
- Calcula-Dibuja 4Document23 pagesCalcula-Dibuja 4ENRIQUE CRESPONo ratings yet
- CH Multiple Linear Regression Everitt HothornDocument12 pagesCH Multiple Linear Regression Everitt HothornRuan CerqueiraNo ratings yet
- 330 Lecture15 2014Document53 pages330 Lecture15 2014PiNo ratings yet
- Multivariate Statistics Principal Component Analysis (PCA)Document41 pagesMultivariate Statistics Principal Component Analysis (PCA)Axesh VamjaNo ratings yet
- ExamplesR Power LawDocument12 pagesExamplesR Power LawKen MatsudaNo ratings yet
- Flipped Lecture 4 Discussion February 10th 2020: A Few PointsDocument3 pagesFlipped Lecture 4 Discussion February 10th 2020: A Few PointsNikuBotnariNo ratings yet
- Ejemplo de UsoDocument13 pagesEjemplo de UsoCristian Daniel Quiroz MorenoNo ratings yet
- Lect6 PDFDocument22 pagesLect6 PDF杜晓晚No ratings yet
- SLR NotesDocument96 pagesSLR NotesRafi DawarNo ratings yet
- Data Visualization With Ggplot2: Sca!er PlotsDocument54 pagesData Visualization With Ggplot2: Sca!er PlotsSxk 333No ratings yet
- 330 Lecture9 2014Document40 pages330 Lecture9 2014Anonymous gUySMcpSqNo ratings yet
- RplotsDocument8 pagesRplotsveyeho1025No ratings yet
- Displaying Model Plots in Lattice PlotsDocument16 pagesDisplaying Model Plots in Lattice PlotsAriake SwyceNo ratings yet
- 02 SVM TabletDocument39 pages02 SVM TabletJiajun YuanNo ratings yet
- 330 Lecture8 2015Document33 pages330 Lecture8 2015Anonymous gUySMcpSqNo ratings yet
- 1 Microbalance Accuracy: Manuel F. G. Weinkauf, José G. Kunze, Joanna J. Waniek, Michal Ku CeraDocument9 pages1 Microbalance Accuracy: Manuel F. G. Weinkauf, José G. Kunze, Joanna J. Waniek, Michal Ku CerawessilissaNo ratings yet
- RQ RegsplineDocument1 pageRQ RegsplinerojasleopNo ratings yet
- 2.lecture2 AteDocument61 pages2.lecture2 AteMarc RomaníNo ratings yet
- STAT1400 2022 1st Week4-Lecture 8Document22 pagesSTAT1400 2022 1st Week4-Lecture 8Sameer GuptaNo ratings yet
- 330 Lecture4 2015Document32 pages330 Lecture4 2015Anonymous gUySMcpSqNo ratings yet
- MissingdataDocument10 pagesMissingdataAyaan ShahNo ratings yet
- Ggplot2 Course2 ch5 SlidesDocument23 pagesGgplot2 Course2 ch5 SlidesSxk 333No ratings yet
- Applied Econometrics WithDocument50 pagesApplied Econometrics WithSamia NasreenNo ratings yet
- 6 Slides-Ggplot2 Part1Document27 pages6 Slides-Ggplot2 Part1Ashwani KumarNo ratings yet
- Boxplots Degs NSVD - PTL 2Document1 pageBoxplots Degs NSVD - PTL 2Amal KatribNo ratings yet
- Regression AnalysisDocument23 pagesRegression Analysisicelon NNo ratings yet
- HX 4Document1 pageHX 4drassuss45No ratings yet
- (With Residual Plot) : 40 60 80 100 120 140 160 WeightDocument11 pages(With Residual Plot) : 40 60 80 100 120 140 160 WeightmehrinfatimaNo ratings yet
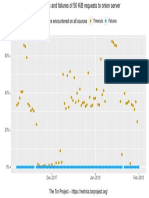
- Problems Encountered On All Sources: Timeouts FailuresDocument1 pageProblems Encountered On All Sources: Timeouts FailuresPatrick PerezNo ratings yet
- Foo PDFDocument7 pagesFoo PDFfodsffNo ratings yet
- Math, Grade 3: Strengthening Basic Skills with Jokes, Comics, and RiddlesFrom EverandMath, Grade 3: Strengthening Basic Skills with Jokes, Comics, and RiddlesNo ratings yet
- Math, Grade 4: Strengthening Basic Skills with Jokes, Comics, and RiddlesFrom EverandMath, Grade 4: Strengthening Basic Skills with Jokes, Comics, and RiddlesNo ratings yet
- Bayesian Inference For The Normal Distribution: 1. Ith A Sample Size of 1Document9 pagesBayesian Inference For The Normal Distribution: 1. Ith A Sample Size of 1Malika BehroozrazeghNo ratings yet
- Bayesian Inference For The Normal Distribution: 1. Ith A Sample Size of 1Document9 pagesBayesian Inference For The Normal Distribution: 1. Ith A Sample Size of 1Malika BehroozrazeghNo ratings yet
- Ba Yes LassoDocument22 pagesBa Yes LassoMalika BehroozrazeghNo ratings yet
- Simultaneous Diagonalization: John E. MitchellDocument24 pagesSimultaneous Diagonalization: John E. MitchellMalika BehroozrazeghNo ratings yet
- Web-Admin Configuration Manual: Altai C1N Series Wifi Ap/CpeDocument120 pagesWeb-Admin Configuration Manual: Altai C1N Series Wifi Ap/CpeosvaldoNo ratings yet
- Data Sheet Coolcheck 2Document2 pagesData Sheet Coolcheck 2pera detlicNo ratings yet
- Thesis Topics in Operations ManagementDocument8 pagesThesis Topics in Operations Managementgbxfr1p1100% (2)
- Active Online Learning For Social Media Analysis To Support Crisis ManagementDocument14 pagesActive Online Learning For Social Media Analysis To Support Crisis Managementrock starNo ratings yet
- Q # 1 What Is Machine Cycle in Computer and How It Works?Document4 pagesQ # 1 What Is Machine Cycle in Computer and How It Works?Coding ExpertNo ratings yet
- Symantec Endpoint Protection PDFDocument6 pagesSymantec Endpoint Protection PDFErica Volpi WerkmannNo ratings yet
- Downloaded From Manuals Search EngineDocument85 pagesDownloaded From Manuals Search EngineRadu BurloiuNo ratings yet
- Chapter15 1Document36 pagesChapter15 1Reyazul HasanNo ratings yet
- Irish Research Council Government of Ireland Postgraduate Scholarship Programme Including Strategic Funding Partner ThemesDocument4 pagesIrish Research Council Government of Ireland Postgraduate Scholarship Programme Including Strategic Funding Partner ThemesRaheem buxNo ratings yet
- Upendra Reddy 2019 IOP Conf. Ser. Mater. Sci. Eng. 590 012036Document7 pagesUpendra Reddy 2019 IOP Conf. Ser. Mater. Sci. Eng. 590 012036Hastavaram Dinesh Kumar ReddyNo ratings yet
- MELNG XC-268L (ML9020814) 220V50Hz EOMDocument20 pagesMELNG XC-268L (ML9020814) 220V50Hz EOMRichard FernandezNo ratings yet
- Currency Recognition System: A Final Project ReportDocument35 pagesCurrency Recognition System: A Final Project ReportAndreea ElenaNo ratings yet
- Bab-2 Linear Algebraic EquationsDocument51 pagesBab-2 Linear Algebraic EquationsNata CorpNo ratings yet
- Linux: 1. Naloga - Mape in DatotekeDocument14 pagesLinux: 1. Naloga - Mape in DatotekeAnonymous 9K7CnytNo ratings yet
- Audiencias en El Sistema Penal Acusatorio Epigmenio Mendieta ValdezDocument161 pagesAudiencias en El Sistema Penal Acusatorio Epigmenio Mendieta ValdezRuben RuizNo ratings yet
- Daftar Tyre M/C Curing: Size SizeDocument3 pagesDaftar Tyre M/C Curing: Size SizeJoni HermantoNo ratings yet
- ME PED-Scheme & Syllabus 2018Document21 pagesME PED-Scheme & Syllabus 2018Angamuthu AnanthNo ratings yet
- What Is The Output of This C CodeDocument14 pagesWhat Is The Output of This C Codearunkumar_a8131No ratings yet
- Thesis About E-Commerce in The PhilippinesDocument8 pagesThesis About E-Commerce in The Philippineslupitavickreypasadena100% (2)
- DP-203 - Data Engineering On Microsoft Azure 2021-1Document42 pagesDP-203 - Data Engineering On Microsoft Azure 2021-1Aayoshi Dutta100% (2)
- BSW1000 Heavy-Duty Automatic Underfloor Swing Door CatalogDocument3 pagesBSW1000 Heavy-Duty Automatic Underfloor Swing Door CatalogRaju KCNo ratings yet
- Oct. 2021 p.2 Mark SchemeDocument10 pagesOct. 2021 p.2 Mark Scheme9m2vwq7mcs100% (2)
- Felcom 16 - SSAS Operator's ManualDocument30 pagesFelcom 16 - SSAS Operator's ManualFabio Marcia GrassiNo ratings yet
- Achievers B1 Test Units 1-3 ConsolidationDocument4 pagesAchievers B1 Test Units 1-3 ConsolidationAnto Roldan Olivera100% (2)
- CRN Man PDM 002 Design Management ManualDocument102 pagesCRN Man PDM 002 Design Management ManualReda GuellilNo ratings yet
- Mapeh Vi ArtsDocument6 pagesMapeh Vi ArtsVALERIE Y. DIZONNo ratings yet
- Microsoft CSR Report AnalysisDocument9 pagesMicrosoft CSR Report AnalysisDaniela GudumacNo ratings yet
- Intel Annual Report 2021: Form 10-K (NASDAQ:INTC)Document10 pagesIntel Annual Report 2021: Form 10-K (NASDAQ:INTC)WigglepikeNo ratings yet
- Lecture 1.3 & 1.4Document31 pagesLecture 1.3 & 1.4Sagar SinghaniaNo ratings yet
- ML Number PlateDocument21 pagesML Number PlateSyeda Heena KousarNo ratings yet