You might also like
- Cisa Ebook New 1 188Document188 pagesCisa Ebook New 1 188thivahar balanNo ratings yet
- Series 3 Electrical Minicargador CASEDocument15 pagesSeries 3 Electrical Minicargador CASEMauricio DuranNo ratings yet
- Computer Systems Servicing-DLLDocument55 pagesComputer Systems Servicing-DLLJen DescargarNo ratings yet
- Data visualization with ggplot2Document54 pagesData visualization with ggplot2Sxk 333No ratings yet
- XML for Data Architects: Designing for Reuse and IntegrationFrom EverandXML for Data Architects: Designing for Reuse and IntegrationRating: 5 out of 5 stars5/5 (1)
- Build Contractor Marketing App for Hardware StoreDocument67 pagesBuild Contractor Marketing App for Hardware StorenaimNo ratings yet
- Multivariate Statistics Principal Component Analysis (PCA)Document41 pagesMultivariate Statistics Principal Component Analysis (PCA)Axesh VamjaNo ratings yet
- STAT1400 2022 1st Week4-Lecture 8Document22 pagesSTAT1400 2022 1st Week4-Lecture 8Sameer GuptaNo ratings yet
- pt4 Adv Regression Models PDFDocument170 pagespt4 Adv Regression Models PDFVishwajit kumarNo ratings yet
- 02 SVM TabletDocument39 pages02 SVM TabletJiajun YuanNo ratings yet
- 330 Lecture8 2014Document34 pages330 Lecture8 2014Anonymous gUySMcpSqNo ratings yet
- Gradient Descent: Ryan Tibshirani Convex Optimization 10-725Document27 pagesGradient Descent: Ryan Tibshirani Convex Optimization 10-725JohnNo ratings yet
- Multicollinearity DiagnosticsDocument9 pagesMulticollinearity DiagnosticsSNo ratings yet
- Outliers & Influential Points DetectionDocument11 pagesOutliers & Influential Points DetectionSNo ratings yet
- 2.lecture2 AteDocument61 pages2.lecture2 AteMarc RomaníNo ratings yet
- STATS 330: Understanding collinearity and its impact on regression coefficientsDocument33 pagesSTATS 330: Understanding collinearity and its impact on regression coefficientsAnonymous gUySMcpSqNo ratings yet
- The Bayesian Lasso: Rebecca C. Steorts Predictive Modeling and Data Mining: STA 521Document16 pagesThe Bayesian Lasso: Rebecca C. Steorts Predictive Modeling and Data Mining: STA 521Malika BehroozrazeghNo ratings yet
- Stat 5102 Lecture Slides: Deck 6 Gauss-Markov Theorem, Sufficiency, Generalized Linear Models, Likelihood Ratio Tests, Categorical Data AnalysisDocument86 pagesStat 5102 Lecture Slides: Deck 6 Gauss-Markov Theorem, Sufficiency, Generalized Linear Models, Likelihood Ratio Tests, Categorical Data AnalysisHông HoaNo ratings yet
- Flipped Lecture 4 Discussion February 10th 2020: A Few PointsDocument3 pagesFlipped Lecture 4 Discussion February 10th 2020: A Few PointsNikuBotnariNo ratings yet
- Transformations and Misspecification of Econometric Models: August 27, 2014Document19 pagesTransformations and Misspecification of Econometric Models: August 27, 2014Maria RoaNo ratings yet
- Econometrics Lecture on Functional Form and Specification of ModelsDocument13 pagesEconometrics Lecture on Functional Form and Specification of ModelsMaria RoaNo ratings yet
- Sim RDocument6 pagesSim Rsipho23No ratings yet
- ISOMDocument5 pagesISOMAntaraNo ratings yet
- ClusteringDocument62 pagesClusteringRichard RichieNo ratings yet
- Lecture 21Document6 pagesLecture 21Lasme Ephrem DominiqueNo ratings yet
- Foo PDFDocument7 pagesFoo PDFfodsffNo ratings yet
- 1 Microbalance Accuracy: Manuel F. G. Weinkauf, José G. Kunze, Joanna J. Waniek, Michal Ku CeraDocument9 pages1 Microbalance Accuracy: Manuel F. G. Weinkauf, José G. Kunze, Joanna J. Waniek, Michal Ku CerawessilissaNo ratings yet
- STATS 330: Detect and diagnose outliersDocument61 pagesSTATS 330: Detect and diagnose outliersPETERNo ratings yet
- Regression Analysis - From Statistics to Machine LearningDocument50 pagesRegression Analysis - From Statistics to Machine LearningthcNo ratings yet
- Understanding Copulas and Their ApplicationsDocument22 pagesUnderstanding Copulas and Their ApplicationsWOONGCHAE YOONo ratings yet
- 5 Regression PDFDocument115 pages5 Regression PDFhawk91No ratings yet
- Anscombe Regression Example DataDocument5 pagesAnscombe Regression Example DataAnonymous GvTPw4sNo ratings yet
- Calcula-Dibuja 4Document23 pagesCalcula-Dibuja 4ENRIQUE CRESPONo ratings yet
- Fitting distributions and comparing fits with R's fitdistrplus packageDocument34 pagesFitting distributions and comparing fits with R's fitdistrplus packageElíGomaraGilNo ratings yet
- 2014 TestDocument13 pages2014 TestAnonymous gUySMcpSqNo ratings yet
- ExamplesR Power LawDocument12 pagesExamplesR Power LawKen MatsudaNo ratings yet
- Introduction to Linear Regression - Key ConceptsDocument6 pagesIntroduction to Linear Regression - Key ConceptsSajid bkrNo ratings yet
- Noncentral TDocument56 pagesNoncentral TMadara RadillaNo ratings yet
- K-Means Vs Mini Batch K-Means: A ComparisonDocument12 pagesK-Means Vs Mini Batch K-Means: A Comparisonrather AarifNo ratings yet
- STAT1400 2022 1st Week4-Lecture 7Document19 pagesSTAT1400 2022 1st Week4-Lecture 7Sameer GuptaNo ratings yet
- EloisaDocument12 pagesEloisastarbridNo ratings yet
- Displaying Model Plots in Lattice PlotsDocument16 pagesDisplaying Model Plots in Lattice PlotsAriake SwyceNo ratings yet
- C2 Statistical LearningDocument37 pagesC2 Statistical LearningLluïsa GualNo ratings yet
- RQ Mcycle1Document1 pageRQ Mcycle1rojasleopNo ratings yet
- 330 Lecture4 2015Document32 pages330 Lecture4 2015Anonymous gUySMcpSqNo ratings yet
- 330 Lecture15 2014Document53 pages330 Lecture15 2014PiNo ratings yet
- STATS 330 Lecture 9 DiagnosticsDocument40 pagesSTATS 330 Lecture 9 DiagnosticsAnonymous gUySMcpSqNo ratings yet
- Part3 Set1 GARCHDocument37 pagesPart3 Set1 GARCHJames DeenNo ratings yet
- Week 4, Solution: Exercise 4.38Document15 pagesWeek 4, Solution: Exercise 4.38John SmithNo ratings yet
- 330 Lecture18 2014Document24 pages330 Lecture18 2014PETERNo ratings yet
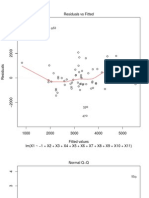
- (With Residual Plot) : 40 60 80 100 120 140 160 WeightDocument11 pages(With Residual Plot) : 40 60 80 100 120 140 160 WeightmehrinfatimaNo ratings yet
- Wager14a PDFDocument27 pagesWager14a PDFgeoman970No ratings yet
- Non-Parametric Copula Model for Semi-Supervised Domain AdaptationDocument9 pagesNon-Parametric Copula Model for Semi-Supervised Domain AdaptationTran CuongNo ratings yet
- IntroductionDocument5 pagesIntroductionTalha FarooqNo ratings yet
- MissingdataDocument10 pagesMissingdataAyaan ShahNo ratings yet
- Course2 - Principal Component Analysis (PCA) : Fiche TD Avec Le LogicielDocument17 pagesCourse2 - Principal Component Analysis (PCA) : Fiche TD Avec Le LogicielJohnnyNo ratings yet
- OutliersDocument7 pagesOutliersSasidhar NandikollaNo ratings yet
- Lecture HPC 11 ParallelizationDocument128 pagesLecture HPC 11 ParallelizationAldo Ndun AveiroNo ratings yet
- Find multiple roots and Taylor coefficients of a functionDocument16 pagesFind multiple roots and Taylor coefficients of a functionmgrubisicNo ratings yet
- Prelims StatsDocument39 pagesPrelims StatsSergioNo ratings yet
- SLR NotesDocument96 pagesSLR NotesRafi DawarNo ratings yet
- Intervening With - Purge Without - Noov L2 Intervening Without - Purge Without - Noov L2Document10 pagesIntervening With - Purge Without - Noov L2 Intervening Without - Purge Without - Noov L2Esubalew MaruNo ratings yet
- Graph Comparing Sample Quantiles to Theoretical Normal QuantilesDocument1 pageGraph Comparing Sample Quantiles to Theoretical Normal QuantilesBorysław PaulewiczNo ratings yet
- Lectures Machine LearningDocument205 pagesLectures Machine LearningGuilherme MartheNo ratings yet
- Density Estimation 36-708Document32 pagesDensity Estimation 36-708SNo ratings yet
- Linear Classification: 1 1 N N I D IDocument33 pagesLinear Classification: 1 1 N N I D ISNo ratings yet
- Boosting: I I I IDocument5 pagesBoosting: I I I ISNo ratings yet
- Sparse Additive Models: University of California, Berkeley, USADocument22 pagesSparse Additive Models: University of California, Berkeley, USASNo ratings yet
- Linear Regression: 1 1 N N I I I D I IDocument20 pagesLinear Regression: 1 1 N N I I I D I ISNo ratings yet
- Differential Privacy: 1 N I 1 N NDocument7 pagesDifferential Privacy: 1 N I 1 N NSNo ratings yet
- Nonparametric Classification ExplainedDocument20 pagesNonparametric Classification ExplainedSNo ratings yet
- High-Dimensional, Two-Sample TestingDocument9 pagesHigh-Dimensional, Two-Sample TestingSNo ratings yet
- Carnegie Mellon Statistics Course SolutionsDocument12 pagesCarnegie Mellon Statistics Course SolutionsSNo ratings yet
- Homework 4 Due Friday April 19 3:00 PM Submit A PDF File On CanvasDocument2 pagesHomework 4 Due Friday April 19 3:00 PM Submit A PDF File On CanvasSNo ratings yet
- 36-708 Statistical Machine Learning Homework #3 Solutions: DUE: March 29, 2019Document22 pages36-708 Statistical Machine Learning Homework #3 Solutions: DUE: March 29, 2019SNo ratings yet
- 10/36-702 Statistical Machine Learning Homework #2 SolutionsDocument11 pages10/36-702 Statistical Machine Learning Homework #2 SolutionsSNo ratings yet
- Support Vector Machines: A Guide to Maximizing MarginsDocument5 pagesSupport Vector Machines: A Guide to Maximizing MarginsSNo ratings yet
- Online Learning: T T T T T T T TDocument8 pagesOnline Learning: T T T T T T T TSNo ratings yet
- Manifold Estimation, Hidden Structure and Dimension ReductionDocument39 pagesManifold Estimation, Hidden Structure and Dimension ReductionSNo ratings yet
- 36-708 Statistical Machine Learning Homework #4 Solutions: DUE: April 19, 2019Document16 pages36-708 Statistical Machine Learning Homework #4 Solutions: DUE: April 19, 2019SNo ratings yet
- Dimension Reduction and Hidden Structure ExplainedDocument40 pagesDimension Reduction and Hidden Structure ExplainedSNo ratings yet
- High-Dimensional, Two-Sample TestingDocument9 pagesHigh-Dimensional, Two-Sample TestingSNo ratings yet
- A Closer Look at Sparse Regression Ryan Tibshirani: 2.1 Three Norms: ', ', 'Document25 pagesA Closer Look at Sparse Regression Ryan Tibshirani: 2.1 Three Norms: ', ', 'SNo ratings yet
- Causal Inference: 1.1 Two Types of Causal QuestionsDocument19 pagesCausal Inference: 1.1 Two Types of Causal QuestionsSNo ratings yet
- Functionspaces PDFDocument15 pagesFunctionspaces PDFgabrieleNo ratings yet
- Data Analysis Project 2 Due 5:00 PM Nov 21 1 InstructionsDocument3 pagesData Analysis Project 2 Due 5:00 PM Nov 21 1 InstructionsSNo ratings yet
- Homework 2 Section B Regression Analysis and SimulationDocument2 pagesHomework 2 Section B Regression Analysis and SimulationSNo ratings yet
- HW7Document1 pageHW7SNo ratings yet
- 1 ReviewDocument7 pages1 ReviewSNo ratings yet
- 36-401 Modern Regression HW #2 Solutions: Problem 1 (36 Points Total)Document15 pages36-401 Modern Regression HW #2 Solutions: Problem 1 (36 Points Total)SNo ratings yet
- Data Analysis Exam 1 36-401, Section BDocument3 pagesData Analysis Exam 1 36-401, Section BSNo ratings yet
- Lecture 7: Diagnostics: 36-401, Fall 2017, Section BDocument35 pagesLecture 7: Diagnostics: 36-401, Fall 2017, Section BSNo ratings yet
- Lecture 8: Inference 36-401, Fall 2015, Section BDocument16 pagesLecture 8: Inference 36-401, Fall 2015, Section BSNo ratings yet
- Lecture 4: Simple Linear Regression Models, With Hints at Their EstimationDocument12 pagesLecture 4: Simple Linear Regression Models, With Hints at Their EstimationSNo ratings yet
- Aladdin XT Installation Guide PDFDocument10 pagesAladdin XT Installation Guide PDFDiego de SouzaNo ratings yet
- Notes - Unit 7Document21 pagesNotes - Unit 7GunjaNo ratings yet
- Using vi Text Editor: Create, Edit, Search and Delete TextDocument3 pagesUsing vi Text Editor: Create, Edit, Search and Delete TextDharvin DaranNo ratings yet
- Tedmore Flexmark Product Series Details - VukDocument8 pagesTedmore Flexmark Product Series Details - VukWisan Nursamsi SidikNo ratings yet
- BD Facspresto: A Near-Patient Complete Cd4 Testing SolutionDocument16 pagesBD Facspresto: A Near-Patient Complete Cd4 Testing SolutionIsah MohammedNo ratings yet
- MST UNIT I r20 IotDocument40 pagesMST UNIT I r20 IotYadavilli Vinay100% (1)
- DCC ProgrammingDocument238 pagesDCC ProgrammingEmad MulqiNo ratings yet
- The DevOps Guide To Database Backups For MySQL and MariaDBDocument48 pagesThe DevOps Guide To Database Backups For MySQL and MariaDBPedroNo ratings yet
- Living in It Era ScrapbookDocument91 pagesLiving in It Era ScrapbookEj AparriNo ratings yet
- Ricoh MP C2011SP: Digital Full Colour Multi Function PrinterDocument4 pagesRicoh MP C2011SP: Digital Full Colour Multi Function PrinterRj TechNo ratings yet
- IOT Based Electrical Switching Circuit For The Safety of Human and Electrical SystemDocument4 pagesIOT Based Electrical Switching Circuit For The Safety of Human and Electrical SystemIJRASETPublicationsNo ratings yet
- Research Paper On Cloud Computing: June 2021Document7 pagesResearch Paper On Cloud Computing: June 2021AzureNo ratings yet
- Dell Technologies Networking: Edge Platforms Portfolio OverviewDocument44 pagesDell Technologies Networking: Edge Platforms Portfolio OverviewAhmed Hassan100% (1)
- AlgNotes PDFDocument106 pagesAlgNotes PDFAsHraf G. ElrawEiNo ratings yet
- NodeXL - Network Overview, Discovery and Exploration For Excel - CodePlex ArchiveDocument3 pagesNodeXL - Network Overview, Discovery and Exploration For Excel - CodePlex ArchivekombateNo ratings yet
- Syed Usama Ali ProjectDocument25 pagesSyed Usama Ali ProjectSarmad MehmoodNo ratings yet
- TraceDocument3 pagesTraceSiegfried P. CatipayNo ratings yet
- MourtzisDocument32 pagesMourtzisFerdyanta Yanta SitepuNo ratings yet
- Digital Literacy SkillsDocument2 pagesDigital Literacy SkillsMary Ann Dela CruzNo ratings yet
- Cópias de Programas - MozardDocument6 pagesCópias de Programas - MozardTânia RodriguesNo ratings yet
- PLC Compare, Jump, and MCR InstructionsDocument18 pagesPLC Compare, Jump, and MCR InstructionsReine100% (1)
- January 2043 : Sun Mon Tue Wed Thu Fri SatDocument12 pagesJanuary 2043 : Sun Mon Tue Wed Thu Fri SatCF-ThunderNo ratings yet
- Binary Tree and BSTDocument48 pagesBinary Tree and BSTsri aknthNo ratings yet
- Middleware Technologies 2marksDocument16 pagesMiddleware Technologies 2marksappsectesting3No ratings yet
- Major Project Report On NewsDocument16 pagesMajor Project Report On NewsAkash NegiNo ratings yet
- CCCDocument2 pagesCCCduranNo ratings yet