You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Forum Lae Sheet 1Document8 pagesForum Lae Sheet 1dasa_108No ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5795)
- A Request From Aindra PrabhuDocument1 pageA Request From Aindra Prabhudasa_108No ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Syllabus: Cambridge IGCSE Sociology 0495Document27 pagesSyllabus: Cambridge IGCSE Sociology 0495dasa_108No ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- 7 Purposes of Iskcon: By: A.C Bhaktivedanta Swami Srila PrabhupadaDocument8 pages7 Purposes of Iskcon: By: A.C Bhaktivedanta Swami Srila Prabhupadadasa_108No ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Global E3 Steps For Applying - A UF Exchange ProgramDocument1 pageGlobal E3 Steps For Applying - A UF Exchange Programdasa_108No ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Indian Visa AnnexVI 01022018Document11 pagesIndian Visa AnnexVI 01022018dasa_108No ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Art and Science of Harinam Sankirtan Yajna - 2Document47 pagesThe Art and Science of Harinam Sankirtan Yajna - 2dasa_108No ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Naparima College 2020 Examinations Query Form: Deadline: Monday, October 19, 2020Document1 pageNaparima College 2020 Examinations Query Form: Deadline: Monday, October 19, 2020dasa_108No ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Understanding Your Scholarship Agreement: The Legal ToolboxDocument33 pagesUnderstanding Your Scholarship Agreement: The Legal Toolboxdasa_108No ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Complaint Letters - Gap Fill: Exercise 1:: Complaint Letter Writing Activities - Khanfar MounaDocument13 pagesComplaint Letters - Gap Fill: Exercise 1:: Complaint Letter Writing Activities - Khanfar Mounadasa_108100% (1)
- PDFsam - Escape From Tenopia 2 Trapped in The Sea KingdomDocument1 pagePDFsam - Escape From Tenopia 2 Trapped in The Sea Kingdomdasa_108No ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Application For Enrolment in A School in Trinidad and TobagoDocument2 pagesApplication For Enrolment in A School in Trinidad and Tobagodasa_108No ratings yet
- Day 1 Day 2 Day 3 Day 4 Day 5 Day 6 Day 7 Day 8 Day 9 Day 10Document1 pageDay 1 Day 2 Day 3 Day 4 Day 5 Day 6 Day 7 Day 8 Day 9 Day 10dasa_108No ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Project: List Title: Output Input DO AO AIDocument21 pagesProject: List Title: Output Input DO AO AIobaiNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Presentation - State of The System and Winter Outlook - 26 April 2026Document20 pagesPresentation - State of The System and Winter Outlook - 26 April 2026victoriaNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
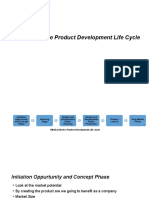
- Medical Device Product Development Life CycleDocument8 pagesMedical Device Product Development Life CycleSuresh Anand100% (1)
- OTM DM Data Management Guide Release18Document108 pagesOTM DM Data Management Guide Release18Alf ColNo ratings yet
- Lesson 5 Managing Text Flow 742780943 (Yeah Good Day)Document37 pagesLesson 5 Managing Text Flow 742780943 (Yeah Good Day)Ahmed El IssawiNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Presentation Software 2019 2020 PDFDocument50 pagesPresentation Software 2019 2020 PDFTony GaryNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Information Assurance PlanDocument5 pagesInformation Assurance PlanEddyOmburahNo ratings yet
- Hos-Sqm-Mos-009-01 Method Statement For Earthwork - CRSDocument1 pageHos-Sqm-Mos-009-01 Method Statement For Earthwork - CRSAnwar MohiuddinNo ratings yet
- Anurag Verma - Case StudyDocument9 pagesAnurag Verma - Case StudyAnurag VermaNo ratings yet
- Speed Control of Three-Phase Induction Motor Using Sinusoidal Pulse Width ModulationDocument37 pagesSpeed Control of Three-Phase Induction Motor Using Sinusoidal Pulse Width ModulationRavi KumarNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Quantity TakeoffDocument36 pagesQuantity Takeoffqaisarmehboob82No ratings yet
- Pinch Roll #05 (Guard Film)Document1 pagePinch Roll #05 (Guard Film)Gulshan sah.07No ratings yet
- 336-338-339-750-751-754-774-794 ServiceDocument134 pages336-338-339-750-751-754-774-794 ServiceLenny Forton100% (1)
- RIVERA - ECE11 - Enabling Assessment Hypothesis Part 1Document4 pagesRIVERA - ECE11 - Enabling Assessment Hypothesis Part 1Ehron RiveraNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Topik 10-Information Technology (It) and Decision MakingDocument32 pagesTopik 10-Information Technology (It) and Decision MakingPatriciaNo ratings yet
- Tympanometry Flute InventisDocument120 pagesTympanometry Flute InventisMUHAMMAD SAADNo ratings yet
- HUAWEI GENEX Discovery PS Collector Configuration Guide V2.0Document12 pagesHUAWEI GENEX Discovery PS Collector Configuration Guide V2.0eduardo2307No ratings yet
- Blackmail FMT: Share This DocumentDocument1 pageBlackmail FMT: Share This DocumentOladosu TaiwoNo ratings yet
- Mini Project Doc 2Document25 pagesMini Project Doc 2Likhil GoudNo ratings yet
- Coding:: Q1. Washing MachineDocument55 pagesCoding:: Q1. Washing Machinenayomi cherukuri0% (1)
- Valliammai Engineering College: SRM Nagar, Kattankulathur - 603 203Document9 pagesValliammai Engineering College: SRM Nagar, Kattankulathur - 603 203nandiniNo ratings yet
- Chapter 13 WorksheetDocument3 pagesChapter 13 WorksheetChris CamarilloNo ratings yet
- Aritco 7000 Maintenance ManualDocument36 pagesAritco 7000 Maintenance ManualZen-o SamaNo ratings yet
- Security Chaos Engineering VericaDocument92 pagesSecurity Chaos Engineering VericaAli DayaniNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- 69-343-136 Operator's and Maintenance Manual 14 Sandvik-PDF en-USDocument86 pages69-343-136 Operator's and Maintenance Manual 14 Sandvik-PDF en-USrobNo ratings yet
- Readme (WWW - Ir DL - Com)Document1 pageReadme (WWW - Ir DL - Com)Youjinn MadNo ratings yet
- DecconvDocument2 pagesDecconvabul hussainNo ratings yet
- Technical - Elkon Mix Master-30Document5 pagesTechnical - Elkon Mix Master-30Jenriel CatulingNo ratings yet
- Swift2 RR ManualDocument11 pagesSwift2 RR ManualChristian LimitNo ratings yet
- Construction Contract Administration Performance Assessment Tool by Using A Fuzzy Structural Equation ModelDocument22 pagesConstruction Contract Administration Performance Assessment Tool by Using A Fuzzy Structural Equation ModelAhed NabilNo ratings yet
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)From EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)No ratings yet