You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5796)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Statistics and Probability KatabasisDocument7 pagesStatistics and Probability KatabasisDaniel N Sherine FooNo ratings yet
- Numpy - Python Package For DataDocument9 pagesNumpy - Python Package For DataDaniel N Sherine FooNo ratings yet
- Data Handling Using RDocument1 pageData Handling Using RDaniel N Sherine FooNo ratings yet
- Data Cleansing Using RDocument10 pagesData Cleansing Using RDaniel N Sherine Foo0% (1)
- Clustering - The Data EnsembleDocument4 pagesClustering - The Data EnsembleDaniel N Sherine FooNo ratings yet
- Advanced RegressionDocument13 pagesAdvanced RegressionDaniel N Sherine FooNo ratings yet
- End-to-End Developer Journey On GKE Ebook 02Document37 pagesEnd-to-End Developer Journey On GKE Ebook 02Daniel N Sherine FooNo ratings yet
- PCNE WorkbookDocument83 pagesPCNE WorkbookDaniel N Sherine FooNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- SE252 SE Lab Manual v.0.1Document83 pagesSE252 SE Lab Manual v.0.1Mujeeb khanNo ratings yet
- Bee TVDocument6 pagesBee TVMhsio JtneNo ratings yet
- SHS 21 Century Literature From The Philippines and The WorldDocument8 pagesSHS 21 Century Literature From The Philippines and The WorldMollyNo ratings yet
- Excel Activity 14 Review of Charts & Formatting PracticeDocument2 pagesExcel Activity 14 Review of Charts & Formatting Practiceverneiza balbastroNo ratings yet
- Servicenow Certified System Administrator Exam SpecificationDocument6 pagesServicenow Certified System Administrator Exam Specificationibmkamal-1No ratings yet
- Belgium - AMS SAP Leaflet PDFDocument12 pagesBelgium - AMS SAP Leaflet PDFashahmednNo ratings yet
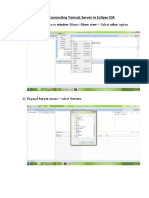
- Connecting Tomcat Server in Eclipse IDEDocument13 pagesConnecting Tomcat Server in Eclipse IDEAKHILA KHODAYNo ratings yet
- Subject Outline: 41889 Application Development in The iOS EnvironmentDocument10 pagesSubject Outline: 41889 Application Development in The iOS EnvironmentmjNo ratings yet
- Chapter 5 Listening To Customers Through ResearchDocument22 pagesChapter 5 Listening To Customers Through ResearchSaadNo ratings yet
- JFSM Active Flow ControlDocument9 pagesJFSM Active Flow ControlFahmi IzzuddinNo ratings yet
- Introduction To Smart Contracts - Solidity 0.7.6 DocumentationDocument11 pagesIntroduction To Smart Contracts - Solidity 0.7.6 DocumentationRoyce NicholasNo ratings yet
- Enterprise Announcement Public Webinar June 2020 v2Document45 pagesEnterprise Announcement Public Webinar June 2020 v2Almamata Ghsa99setNo ratings yet
- Aravali International School Class - Viii Subject - Mathematics Algebraic Expressions and Identities Name: - Roll No: - Teacher's SignatureDocument3 pagesAravali International School Class - Viii Subject - Mathematics Algebraic Expressions and Identities Name: - Roll No: - Teacher's SignatureSujnya Sucharita DashNo ratings yet
- Virtualized Data Center and Cloud Infrastructure Planning and DesignDocument3 pagesVirtualized Data Center and Cloud Infrastructure Planning and Designmayank10yadav_741026No ratings yet
- Dokumen - Tips - 1996 Polaris Magnum 425 4x4 Service Repair Manual 1600180584Document14 pagesDokumen - Tips - 1996 Polaris Magnum 425 4x4 Service Repair Manual 1600180584Will smithNo ratings yet
- Hematology Analyzer LIS Communication Protocol For New PlatformDocument51 pagesHematology Analyzer LIS Communication Protocol For New PlatformAbhishek MandalNo ratings yet
- 9 - SINCRO - 7a - EN - WIRING DIAGRAMSDocument17 pages9 - SINCRO - 7a - EN - WIRING DIAGRAMSBoldsaikhan Tavkhai100% (1)
- Iso 15614-1 Amd 1-2008Document8 pagesIso 15614-1 Amd 1-2008Anbarasan PerumalNo ratings yet
- 2017-TQWT ImrfDocument4 pages2017-TQWT ImrfSushilKumar AzadNo ratings yet
- ASSIGNMENT 1 - Firing If Howitzer Gun - HaleemaMalik MS19Document7 pagesASSIGNMENT 1 - Firing If Howitzer Gun - HaleemaMalik MS19Haleema MalikNo ratings yet
- 2009 Iridium-Cosmos Collision FactsheetDocument3 pages2009 Iridium-Cosmos Collision FactsheetPratiwi NingrumNo ratings yet
- Base Designs Castle Clash Wiki FandomDocument1 pageBase Designs Castle Clash Wiki FandomMaike OliveiraNo ratings yet
- Midea VRF V5X Katalogas 2017Document106 pagesMidea VRF V5X Katalogas 2017Erwin MaldoNo ratings yet
- G-7 Math QuizDocument6 pagesG-7 Math QuizExer ArabisNo ratings yet
- Quantifying The Role of Social Media On Education An Analysis Between The Correlation of Social Media To The Selected Students at Kaylaway National Highschool 3Document12 pagesQuantifying The Role of Social Media On Education An Analysis Between The Correlation of Social Media To The Selected Students at Kaylaway National Highschool 3Julius BayagaNo ratings yet
- CodeDocument3 pagesCodeSi Yang LeeNo ratings yet
- Audio Routes 2 - Advanced TopicsDocument6 pagesAudio Routes 2 - Advanced TopicsBob BustamanteNo ratings yet
- 1200 MW Lanco Amarkantak Power Private Limited: Standard Check List Raw Water SystemDocument7 pages1200 MW Lanco Amarkantak Power Private Limited: Standard Check List Raw Water Systemlp mishraNo ratings yet
- PCI DSS 3.2.1 Guide: PCI DSS Requirements v3.2.1 Milestone Wazuh Component How It HelpsDocument13 pagesPCI DSS 3.2.1 Guide: PCI DSS Requirements v3.2.1 Milestone Wazuh Component How It Helpspham huy hungNo ratings yet
- Comix 35Document6 pagesComix 35oriol.berges.bergadaNo ratings yet